Come sappiamo, l'algoritmo di apprendimento automatico supervisionato può essere ampiamente classificato in algoritmi di regressione e classificazione. Negli algoritmi di regressione abbiamo previsto l'output per valori continui, ma per prevedere i valori categoriali abbiamo bisogno di algoritmi di classificazione.
Cos'è l'algoritmo di classificazione?
L'algoritmo di classificazione è una tecnica di apprendimento supervisionato che viene utilizzata per identificare la categoria di nuove osservazioni sulla base dei dati di addestramento. Nella classificazione, un programma apprende dal set di dati o dalle osservazioni forniti e quindi classifica la nuova osservazione in un numero di classi o gruppi. Ad esempio, Sì o No, 0 o 1, Spam o Non Spam, gatto o cane, ecc. Le classi possono essere chiamate come obiettivi/etichette o categorie.
Java raddoppia in stringa
A differenza della regressione, la variabile di output della Classificazione è una categoria, non un valore, come 'Verde o Blu', 'frutto o animale', ecc. Poiché l'algoritmo di Classificazione è una tecnica di apprendimento supervisionato, richiede dati di input etichettati, che significa che contiene input con l'output corrispondente.
Nell'algoritmo di classificazione, una funzione di output discreta (y) viene mappata sulla variabile di input (x).
y=f(x), where y = categorical output
Il miglior esempio di algoritmo di classificazione ML è Rilevatore di spam e-mail .
L'obiettivo principale dell'algoritmo di classificazione è identificare la categoria di un determinato set di dati e questi algoritmi vengono utilizzati principalmente per prevedere l'output per i dati categorici.
Gli algoritmi di classificazione possono essere meglio compresi utilizzando il diagramma seguente. Nel diagramma seguente, ci sono due classi, la classe A e la classe B. Queste classi hanno caratteristiche simili tra loro e diverse dalle altre classi.
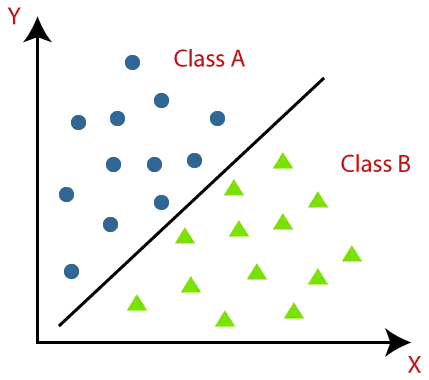
L'algoritmo che implementa la classificazione su un set di dati è noto come classificatore. Esistono due tipi di classificazioni:
Esempi: SI o NO, MASCHIO o FEMMINA, SPAM o NON SPAM, GATTO o CANE, ecc.
Esempio: Classificazioni dei tipi di colture, Classificazione dei tipi di musica.
Studenti in problemi di classificazione:
Nei problemi di classificazione ci sono due tipi di studenti:
Esempio: Algoritmo K-NN, ragionamento basato sui casi
Tipi di algoritmi di classificazione ML:
Gli algoritmi di classificazione possono essere ulteriormente suddivisi nelle due categorie principali:
- Regressione logistica
- Supporta macchine vettoriali
- K-Vicini più vicini
- SVM del kernel
- Na�ve Bayes
- Classificazione dell'albero decisionale
- Classificazione casuale delle foreste
Nota: Impareremo gli algoritmi di cui sopra nei capitoli successivi.
Valutare un modello di classificazione:
Una volta completato il nostro modello è necessario valutarne le prestazioni; o si tratta di un modello di classificazione o di regressione. Quindi per valutare un modello di classificazione, abbiamo i seguenti modi:
confronto di stringhe in Java
1. Perdita logaritmica o perdita di entropia incrociata:
- Viene utilizzato per valutare le prestazioni di un classificatore, il cui output è un valore di probabilità compreso tra 0 e 1.
- Per un buon modello di classificazione binaria, il valore della perdita logaritmica dovrebbe essere vicino a 0.
- Il valore della perdita logaritmica aumenta se il valore previsto si discosta dal valore effettivo.
- La minore perdita logaritmica rappresenta la maggiore precisione del modello.
- Per la classificazione binaria, l'entropia incrociata può essere calcolata come:
?(ylog(p)+(1?y)log(1?p))
Dove y= produzione effettiva, p= produzione prevista.
2. Matrice di confusione:
- La matrice di confusione ci fornisce una matrice/tabella come output e descrive le prestazioni del modello.
- È detta anche matrice degli errori.
- La matrice è costituita dal risultato delle previsioni in una forma riepilogativa, che presenta un numero totale di previsioni corrette e previsioni errate. La matrice appare come nella tabella seguente:
| Effettivo positivo | Effettivo negativo | |
|---|---|---|
| Previsto positivo | Vero positivo | Falso positivo |
| Previsto negativo | Falso negativo | Vero negativo |

3. Curva AUC-ROC:
- La curva ROC sta per Curva delle caratteristiche operative del ricevitore e AUC sta per Area sotto la curva .
- Si tratta di un grafico che mostra l'andamento del modello di classificazione a diverse soglie.
- Per visualizzare le prestazioni del modello di classificazione multiclasse, utilizziamo la curva AUC-ROC.
- La curva ROC viene tracciata con TPR e FPR, dove TPR (tasso di veri positivi) sull'asse Y e FPR (tasso di falsi positivi) sull'asse X.
Casi d'uso di algoritmi di classificazione
Gli algoritmi di classificazione possono essere utilizzati in luoghi diversi. Di seguito sono riportati alcuni casi d'uso popolari degli algoritmi di classificazione:
- Rilevamento dello spam nelle e-mail
- Riconoscimento vocale
- Identificazioni delle cellule tumorali del cancro.
- Classificazione dei farmaci
- Identificazione biometrica, ecc.