Cos'è la cache LRU?
Gli algoritmi di sostituzione della cache sono progettati in modo efficiente per sostituire la cache quando lo spazio è pieno. IL Usato meno di recente (LRU) è uno di quegli algoritmi. Come suggerisce il nome, quando la memoria cache è piena, LRU seleziona i dati utilizzati meno di recente e li rimuove per fare spazio ai nuovi dati. La priorità dei dati nella cache cambia in base alla necessità di tali dati, ovvero se alcuni dati vengono recuperati o aggiornati di recente, la priorità di tali dati verrebbe modificata e assegnata alla priorità più alta, mentre la priorità dei dati diminuisce se rimane inutilizzato operazioni dopo operazioni.
Tabella dei contenuti
- Cos'è la cache LRU?
- Operazioni sulla cache LRU:
- Funzionamento della cache LRU:
- Modi per implementare la cache LRU:
- Implementazione della cache LRU utilizzando Queue e Hashing:
- Implementazione della cache LRU utilizzando Doubly Linked List e Hashing:
- Implementazione della cache LRU utilizzando Deque e Hashmap:
- Implementazione della cache LRU utilizzando Stack e Hashmap:
- Cache LRU che utilizza l'implementazione del contatore:
- Implementazione della cache LRU utilizzando Aggiornamenti Lazy:
- Analisi della complessità della cache LRU:
- Vantaggi della cache LRU:
- Svantaggi della cache LRU:
- Applicazione nel mondo reale della cache LRU:
LRU L'algoritmo è un problema standard e può presentare variazioni in base alle necessità, ad esempio nei sistemi operativi LRU gioca un ruolo cruciale in quanto può essere utilizzato come algoritmo di sostituzione della pagina per ridurre al minimo gli errori di pagina.
Operazioni sulla cache LRU:
- LRUCache (Capacità c): Inizializza la cache LRU con capacità di dimensione positiva C.
- ottenere (chiave) : Restituisce il valore di Chiave ' K' se è presente nella cache altrimenti restituisce -1. Aggiorna anche la priorità dei dati nella cache LRU.
- put (chiave, valore): Aggiorna il valore della chiave se esiste, altrimenti aggiungi la coppia chiave-valore alla cache. Se il numero di chiavi supera la capacità della cache LRU, eliminare la chiave utilizzata meno di recente.
Funzionamento della cache LRU:
Supponiamo di avere una cache LRU di capacità 3 e di voler eseguire le seguenti operazioni:
- Inserisci (chiave=1, valore=A) nella cache
- Inserisci (chiave=2, valore=B) nella cache
- Inserisci (chiave=3, valore=C) nella cache
- Ottieni (chiave=2) dalla cache
- Ottieni (chiave=4) dalla cache
- Inserisci (chiave=4, valore=D) nella cache
- Inserisci (chiave=3, valore=E) nella cache
- Ottieni (chiave=4) dalla cache
- Inserisci (chiave=1, valore=A) nella cache
Le operazioni di cui sopra vengono eseguite una dopo l'altra come mostrato nell'immagine seguente:
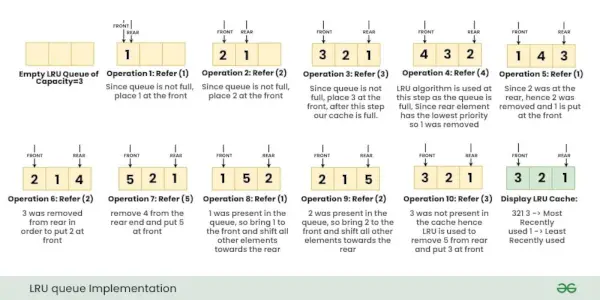
Spiegazione dettagliata di ciascuna operazione:
- Put (chiave 1, valore A) : Poiché la cache LRU ha una capacità vuota=3, non è necessaria alcuna sostituzione e inseriamo {1: A} in alto, ovvero {1: A} ha la massima priorità.
- Put (chiave 2, valore B) : Poiché la cache LRU ha una capacità vuota=2, anche in questo caso non è necessaria alcuna sostituzione, ma ora {2: B} ha la priorità più alta e la priorità di {1: A} diminuisce.
- Put (chiave 3, valore C) : C'è ancora 1 spazio vuoto libero nella cache, quindi inserisci {3: C} senza alcuna sostituzione, nota ora che la cache è piena e l'attuale ordine di priorità dal più alto al più basso è {3:C}, {2:B }, {1:A}.
- Ottieni (tasto 2) : Ora, restituisci il valore di key=2 durante questa operazione, inoltre poiché viene utilizzata key=2, ora il nuovo ordine di priorità è {2:B}, {3:C}, {1:A}
- Ottieni (tasto 4): Osserva che la chiave 4 non è presente nella cache, restituiamo '-1' per questa operazione.
- Put (chiave 4, valore D) : Osserva che la cache è PIENA, ora utilizza l'algoritmo LRU per determinare quale chiave è stata utilizzata meno recentemente. Poiché {1:A} ha la priorità minore, rimuovi {1:A} dalla nostra cache e inserisci {4:D} nella cache. Tieni presente che il nuovo ordine di priorità è {4:D}, {2:B}, {3:C}
- Put (chiave 3, valore E) : Poiché key=3 era già presente nella cache con valore=C, questa operazione non comporterà la rimozione di alcuna chiave, piuttosto aggiornerà il valore di key=3 in ' E' . Ora il nuovo ordine di priorità diventerà {3:E}, {4:D}, {2:B}
- Ottieni (tasto 4) : Restituisce il valore di chiave=4. Ora la nuova priorità diventerà {4:D}, {3:E}, {2:B}
- Put (chiave 1, valore A) : Poiché la nostra cache è PIENA, utilizza il nostro algoritmo LRU per determinare quale chiave è stata utilizzata meno recentemente e poiché {2:B} ha la priorità minore, rimuovi {2:B} dalla nostra cache e inserisci {1:A} nella cache. Ora il nuovo ordine di priorità è {1:A}, {4:D}, {3:E}
Modi per implementare la cache LRU:
La cache LRU può essere implementata in vari modi e ogni programmatore può scegliere un approccio diverso. Tuttavia, di seguito sono riportati gli approcci comunemente utilizzati:
- LRU utilizzando coda e hashing
- LRU utilizzando Elenco doppiamente collegato + Hashing
- LRU utilizzando Deque
- LRU utilizzando Stack
- LRU utilizzando Controimplementazione
- LRU utilizzando Aggiornamenti lenti
Implementazione della cache LRU utilizzando Queue e Hashing:
Utilizziamo due strutture dati per implementare una cache LRU.
- Coda viene implementato utilizzando un elenco doppiamente collegato. La dimensione massima della coda sarà pari al numero totale di frame disponibili (dimensione della cache). Le pagine utilizzate più di recente si troveranno nella parte anteriore e le pagine utilizzate meno di recente si troveranno nella parte posteriore.
- Un hash con il numero di pagina come chiave e l'indirizzo del nodo della coda corrispondente come valore.
Quando si fa riferimento a una pagina, la pagina richiesta potrebbe essere in memoria. Se è in memoria, dobbiamo staccare il nodo della lista e portarlo in testa alla coda.
Se la pagina richiesta non è in memoria, la riportiamo in memoria. In parole semplici, aggiungiamo un nuovo nodo all'inizio della coda e aggiorniamo l'indirizzo del nodo corrispondente nell'hash. Se la coda è piena, cioè tutti i frame sono pieni, rimuoviamo un nodo dalla parte posteriore della coda e aggiungiamo il nuovo nodo all'inizio della coda.
Illustrazione:
Consideriamo le operazioni, Si riferisce chiave X con nella cache LRU: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Nota: Inizialmente non è presente alcuna pagina in memoria.Le immagini sottostanti mostrano l'esecuzione passo passo delle operazioni di cui sopra sulla cache LRU.
Algoritmo:
- Crea una classe LRUCache con la dichiarazione di un elenco di tipo int, una mappa di tipo non ordinata
- Nella funzione di riferimento di LRUCache
- Se questo valore non è presente nella coda, inserisci questo valore davanti alla coda e rimuovi l'ultimo valore se la coda è piena
- Se il valore è già presente, rimuovilo dalla coda e inseriscilo in primo piano
- Nella funzione di visualizzazione stampa, LRUCache utilizza la coda a partire dalla parte anteriore
Di seguito è riportata l’implementazione dell’approccio di cui sopra:
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::iteratore> ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->numeropagina = numeropagina;> > >// Initialize prev and next as NULL> >temp->precedente = temp->successivo = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->conteggio = 0;> >queue->anteriore = coda->posteriore = NULL;> > >// Number of frames that can be stored in memory> >queue->numeroFrames = numeroFrames;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->capacità = capacità;> > >// Create an array of pointers for referring queue nodes> >hash->matrice> >= (QNode**)>malloc>(hash->capacità *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->array[i] = NULL;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->conteggio == coda->numeroFrames;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->posteriore == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->davanti == coda->dietro)> >queue->anteriore = NULL;> > >// Change rear and remove the previous rear> >QNode* temp = queue->posteriore;> >queue->dietro = coda->dietro->precedente;> > >if> (queue->posteriore)> >queue->posteriore->successivo = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->contare--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->array[coda->retro->numeropagina] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->next = coda->fronte;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->dietro = coda->davanti = temp;> >else> // Else change the front> >{> >queue->fronte->precedente = temp;> >queue->anteriore = temperatura;> >}> > >// Add page entry to hash also> >hash->array[numeropagina] = temp;> > >// increment number of full frames> >queue->conta++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->array[Numeropagina];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->anteriore) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->precedente->successivo = reqPage->successivo;> >if> (reqPage->successivo)> >reqPage->successivo->prev = reqPage->prev;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->posteriore) {> >queue->posteriore = reqPage->prev;> >queue->posteriore->successivo = NULL;> >}> > >// Put the requested page before current front> >reqPage->next = coda->fronte;> >reqPage->precedente = NULL;> > >// Change prev of current front> >reqPage->successivo->precedente = reqPage;> > >// Change front to the requested page> >queue->anteriore = reqPage;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->fronte->Numeropagina);> >printf>(>'%d '>, q->anteriore->successivo->Numeropagina);> >printf>(>'%d '>, q->anteriore->successivo->successivo->Numeropagina);> >printf>(>'%d '>, q->anteriore->successivo->successivo->successivo->NumeroPagina);> > >return> 0;> }> |
>
>
Giava
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>doppiamenteQueue;> > >// store references of key in cache> >private> HashSet<>int>>hashSet;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
Implementazione della cache LRU utilizzando Doubly Linked List e Hashing :
L'idea è molto semplice, ovvero continuare a inserire gli elementi in testa.
- se l'elemento non è presente nella lista allora aggiungetelo in testa alla lista
- se l'elemento è presente nell'elenco, sposta l'elemento in testa e sposta l'elemento rimanente dell'elenco
Si noti che la priorità del nodo dipenderà dalla distanza di quel nodo dalla testa, più il nodo è vicino alla testa, maggiore è la priorità che ha. Quindi, quando la dimensione della cache è piena e dobbiamo rimuovere qualche elemento, rimuoviamo l'elemento adiacente alla coda della lista doppiamente collegata.
Implementazione della cache LRU utilizzando Deque e Hashmap:
La struttura dei dati di deque consente l'inserimento e l'eliminazione sia dal front che dall'end, questa proprietà consente l'implementazione di LRU possibile poiché l'elemento Front può rappresentare un elemento ad alta priorità mentre l'elemento end può essere l'elemento a bassa priorità, ovvero quello utilizzato meno di recente.
Lavorando:
- Ottieni l'operazione : controlla se la chiave esiste nella mappa hash della cache e segue i casi seguenti sulla deque:
- Se la chiave viene trovata:
- L'articolo è considerato utilizzato di recente, quindi viene spostato in primo piano nella deque.
- Il valore associato alla chiave viene restituito come risultato dell'operazione
get>operazione.- Se la chiave non viene trovata:
- restituisce -1 per indicare che tale chiave non è presente.
- Operazione Put: Per prima cosa controlla se la chiave esiste già nella mappa hash della cache e segui i casi seguenti sulla deque
- Se la chiave esiste:
- Il valore associato alla chiave viene aggiornato.
- L'elemento viene spostato in primo piano nella deque poiché ora è l'ultimo utilizzato.
- Se la chiave non esiste:
- Se la cache è piena, significa che è necessario inserire un nuovo elemento e eliminare l'elemento utilizzato meno di recente. Questo viene fatto rimuovendo l'elemento dalla fine della deque e la voce corrispondente dalla mappa hash.
- La nuova coppia chiave-valore viene quindi inserita sia nella mappa hash che nella parte anteriore della deque per indicare che si tratta dell'elemento utilizzato più di recente
Implementazione della cache LRU utilizzando Stack e Hashmap:
L'implementazione di una cache LRU (Least Recently Used) utilizzando una struttura dati stack e l'hashing può essere un po' complicata perché uno stack semplice non fornisce un accesso efficiente all'elemento utilizzato meno di recente. Tuttavia, puoi combinare uno stack con una mappa hash per raggiungere questo obiettivo in modo efficiente. Ecco un approccio di alto livello per implementarlo:
- Utilizza una mappa hash : La mappa hash memorizzerà le coppie chiave-valore della cache. Le chiavi verranno mappate ai nodi corrispondenti nello stack.
- Usa una pila : Lo stack manterrà l'ordine delle chiavi in base al loro utilizzo. L'elemento utilizzato meno di recente si troverà in fondo alla pila, mentre l'elemento utilizzato più di recente sarà in cima
Questo approccio non è così efficiente e quindi non viene utilizzato spesso.
Cache LRU che utilizza l'implementazione del contatore:
Ogni blocco nella cache avrà il proprio contatore LRU a cui appartiene il valore del contatore da {0 a n-1} , Qui ' N ‘ rappresenta la dimensione della cache. Il blocco modificato durante la sostituzione del blocco diventa il blocco MRU e, di conseguenza, il suo valore del contatore viene modificato in n – 1. I valori del contatore maggiori del valore del contatore del blocco a cui si accede vengono diminuiti di uno. I restanti blocchi rimangono inalterati.
| Valore di Conter | Priorità | Stato usato |
|---|---|---|
| 0 | Basso | Usato meno di recente polimorfismo Java |
| n-1 | Alto | Usato più di recente |
Implementazione della cache LRU utilizzando Aggiornamenti Lazy:
L'implementazione di una cache LRU (Least Recently Used) utilizzando aggiornamenti lazy è una tecnica comune per migliorare l'efficienza delle operazioni della cache. Gli aggiornamenti lenti implicano il monitoraggio dell'ordine in cui si accede agli elementi senza aggiornare immediatamente l'intera struttura dei dati. Quando si verifica un errore nella cache, puoi decidere se eseguire o meno un aggiornamento completo in base ad alcuni criteri.
Analisi della complessità della cache LRU:
- Complessità temporale:
- Operazione Put(): O(1), ovvero il tempo richiesto per inserire o aggiornare una nuova coppia chiave-valore è costante
- Operazione Get(): O(1), ovvero il tempo necessario per ottenere il valore di una chiave è costante
- Spazio ausiliario: O(N) dove N è la capacità della Cache.
Vantaggi della cache LRU:
- Accesso veloce : È necessario un tempo O(1) per accedere ai dati dalla cache LRU.
- Aggiornamento veloce : è necessario un tempo O(1) per aggiornare una coppia chiave-valore nella cache LRU.
- Rimozione rapida dei dati utilizzati meno di recente : Occorre O(1) eliminare ciò che non è stato utilizzato di recente.
- Nessuna frustata: LRU è meno suscettibile al thrashing rispetto a FIFO perché considera la cronologia di utilizzo delle pagine. È in grado di rilevare quali pagine vengono utilizzate frequentemente e dare loro la priorità per l'allocazione della memoria, riducendo il numero di errori di pagina e di operazioni di I/O del disco.
Svantaggi della cache LRU:
- Richiede una cache di grandi dimensioni per aumentare l'efficienza.
- Richiede l'implementazione di una struttura dati aggiuntiva.
- L'assistenza hardware è elevata.
- In LRU il rilevamento degli errori è difficile rispetto ad altri algoritmi.
- Ha un'accettabilità limitata.
Applicazione nel mondo reale della cache LRU:
- Nei sistemi di database per risultati rapidi delle query.
- Nei sistemi operativi per ridurre al minimo gli errori di pagina.
- Editor di testo e IDE per archiviare file o frammenti di codice utilizzati di frequente
- I router e gli switch di rete utilizzano LRU per aumentare l'efficienza della rete di computer
- Nelle ottimizzazioni del compilatore
- Strumenti di previsione del testo e di completamento automatico