Un processo può essere di due tipi:
- Processo indipendente.
- Processo di cooperazione.
Un processo indipendente non è influenzato dall'esecuzione di altri processi mentre un processo cooperante può essere influenzato da altri processi in esecuzione. Sebbene si possa pensare che questi processi, che funzionano in modo indipendente, verranno eseguiti in modo molto efficiente, in realtà ci sono molte situazioni in cui la natura cooperativa può essere utilizzata per aumentare la velocità di calcolo, la comodità e la modularità. La comunicazione interprocesso (IPC) è un meccanismo che consente ai processi di comunicare tra loro e sincronizzare le proprie azioni. La comunicazione tra questi processi può essere vista come un metodo di cooperazione tra di loro. I processi possono comunicare tra loro attraverso entrambi:
- Memoria condivisa
- Passaggio del messaggio
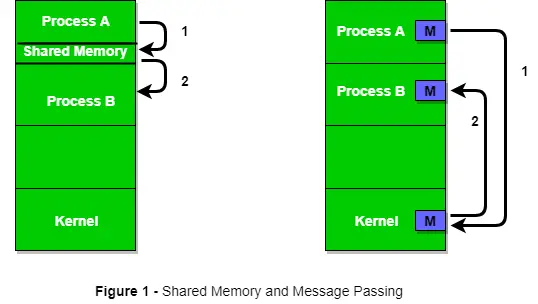
La Figura 1 seguente mostra una struttura di base della comunicazione tra processi tramite il metodo della memoria condivisa e tramite il metodo del passaggio di messaggi.
Un sistema operativo può implementare entrambi i metodi di comunicazione. Per prima cosa discuteremo i metodi di comunicazione della memoria condivisa e poi il passaggio dei messaggi. La comunicazione tra processi che utilizzano la memoria condivisa richiede che i processi condividano alcune variabili e dipende completamente da come il programmatore la implementerà. Un modo di comunicazione che utilizza la memoria condivisa può essere immaginato in questo modo: supponiamo che processo1 e processo2 siano in esecuzione simultaneamente e condividano alcune risorse o utilizzino alcune informazioni da un altro processo. Process1 genera informazioni su determinati calcoli o risorse utilizzate e le conserva come record nella memoria condivisa. Quando process2 deve utilizzare le informazioni condivise, controllerà il record archiviato nella memoria condivisa e prenderà nota delle informazioni generate da process1 e agirà di conseguenza. I processi possono utilizzare la memoria condivisa per estrarre informazioni come record da un altro processo e per fornire informazioni specifiche ad altri processi.
Discutiamo un esempio di comunicazione tra processi utilizzando il metodo della memoria condivisa.
i) Metodo della memoria condivisa
Esempio: problema produttore-consumatore
Esistono due processi: Produttore e Consumatore. Il produttore produce alcuni articoli e il consumatore consuma quell'articolo. I due processi condividono uno spazio comune o una posizione di memoria nota come buffer in cui viene archiviato l'articolo prodotto dal produttore e da cui il consumatore consuma l'articolo se necessario. Esistono due versioni di questo problema: la prima è nota come problema del buffer illimitato in cui il produttore può continuare a produrre elementi e non vi è alcun limite alla dimensione del buffer, la seconda è nota come problema del buffer limitato in che il Produttore può produrre fino a un certo numero di articoli prima di iniziare ad aspettare che il Consumatore lo consumi. Discuteremo il problema del buffer limitato. Innanzitutto, il produttore e il consumatore condivideranno una memoria comune, quindi il produttore inizierà a produrre articoli. Se l'articolo totale prodotto è uguale alla dimensione del buffer, il produttore aspetterà che venga consumato dal consumatore. Allo stesso modo, il consumatore verificherà innanzitutto la disponibilità dell'articolo. Se nessun articolo è disponibile, il Consumatore attenderà che il Produttore lo produca. Se ci sono articoli disponibili, il Consumatore li consumerà. Lo pseudo-codice da dimostrare è fornito di seguito:
Dati condivisi tra i due processi
C
#define buff_max 25> #define mod %> >struct> item{> >// different member of the produced data> >// or consumed data> >---------> >}> > >// An array is needed for holding the items.> >// This is the shared place which will be> >// access by both process> >// item shared_buff [ buff_max ];> > >// Two variables which will keep track of> >// the indexes of the items produced by producer> >// and consumer The free index points to> >// the next free index. The full index points to> >// the first full index.> >int> free_index = 0;> >int> full_index = 0;> > |
>
>
Codice processo produttore
C
item nextProduced;> > >while>(1){> > >// check if there is no space> >// for production.> >// if so keep waiting.> >while>((free_index+1) mod buff_max == full_index);> > >shared_buff[free_index] = nextProduced;> >free_index = (free_index + 1) mod buff_max;> >}> |
>
>
Codice del processo di consumo
C
item nextConsumed;> > >while>(1){> > >// check if there is an available> >// item for consumption.> >// if not keep on waiting for> >// get them produced.> >while>((free_index == full_index);> > >nextConsumed = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >}> |
>
>
Nel codice sopra, il Produttore inizierà di nuovo a produrre quando il (free_index+1) mod buff max sarà gratuito perché se non è gratuito, ciò implica che ci sono ancora oggetti che possono essere consumati dal Consumatore quindi non ce n'è bisogno per produrre di più. Allo stesso modo, se l’indice libero e l’indice completo puntano allo stesso indice, ciò implica che non ci sono elementi da consumare.
Implementazione complessiva del C++:
C++
#include> #include> #include> #include> #define buff_max 25> #define mod %> struct> item {> >// different member of the produced data> >// or consumed data> >// ---------> };> // An array is needed for holding the items.> // This is the shared place which will be> // access by both process> // item shared_buff[buff_max];> // Two variables which will keep track of> // the indexes of the items produced by producer> // and consumer The free index points to> // the next free index. The full index points to> // the first full index.> std::atomic<>int>>indice_libero(0);> std::atomic<>int>>indice_completo(0);> std::mutex mtx;> void> producer() {> >item new_item;> >while> (>true>) {> >// Produce the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >// Add the item to the buffer> >while> (((free_index + 1) mod buff_max) == full_index) {> >// Buffer is full, wait for consumer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Add the item to the buffer> >// shared_buff[free_index] = new_item;> >free_index = (free_index + 1) mod buff_max;> >mtx.unlock();> >}> }> void> consumer() {> >item consumed_item;> >while> (>true>) {> >while> (free_index == full_index) {> >// Buffer is empty, wait for producer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Consume the item from the buffer> >// consumed_item = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >mtx.unlock();> >// Consume the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> }> int> main() {> >// Create producer and consumer threads> >std::vectorthread>discussioni; threads.emplace_back(produttore); threads.emplace_back(consumatore); // Attendi che i thread finiscano for (auto& thread : threads) { thread.join(); } restituisce 0; }> |
>
>
java hasuccessivo
Si noti che la classe atomic viene utilizzata per assicurarsi che le variabili condivise free_index e full_index vengano aggiornate atomicamente. Il mutex viene utilizzato per proteggere la sezione critica in cui si accede al buffer condiviso. La funzione sleep_for viene utilizzata per simulare la produzione e il consumo di articoli.
ii) Metodo di passaggio dei messaggi
Ora inizieremo la nostra discussione sulla comunicazione tra processi tramite lo scambio di messaggi. In questo metodo, i processi comunicano tra loro senza utilizzare alcun tipo di memoria condivisa. Se due processi p1 e p2 vogliono comunicare tra loro, procedono come segue:
- Stabilire un collegamento di comunicazione (se un collegamento esiste già, non è necessario stabilirlo nuovamente).
- Inizia a scambiare messaggi utilizzando le primitive di base.
Abbiamo bisogno di almeno due primitive:
– Inviare (messaggio, destinazione) o Inviare (Messaggio)
– ricevere (messaggio, host) o ricevere (Messaggio)

La dimensione del messaggio può essere di dimensione fissa o di dimensione variabile. Se è di dimensione fissa, è facile per un progettista del sistema operativo ma complicato per un programmatore, mentre se è di dimensione variabile è facile per un programmatore ma complicato per il progettista del sistema operativo. Un messaggio standard può essere composto da due parti: intestazione e corpo.
IL parte dell'intestazione viene utilizzato per memorizzare il tipo di messaggio, l'ID di destinazione, l'ID di origine, la lunghezza del messaggio e le informazioni di controllo. Le informazioni di controllo contengono informazioni come cosa fare se si esaurisce lo spazio del buffer, il numero di sequenza, la priorità. Generalmente, il messaggio viene inviato utilizzando lo stile FIFO.
Messaggio che passa attraverso il collegamento di comunicazione.
Collegamento di comunicazione diretta e indiretta
Ora inizieremo la nostra discussione sui metodi di implementazione dei collegamenti di comunicazione. Durante l'implementazione del collegamento, ci sono alcune domande che devono essere tenute a mente come:
- Come vengono stabiliti i collegamenti?
- Un collegamento può essere associato a più di due processi?
- Quanti collegamenti possono esserci tra ogni coppia di processi comunicanti?
- Qual è la capacità di un collegamento? La dimensione di un messaggio che il collegamento può contenere è fissa o variabile?
- Un collegamento è unidirezionale o bidirezionale?
Un collegamento ha una certa capacità che determina il numero di messaggi che possono risiedere temporaneamente al suo interno, per cui a ogni collegamento è associata una coda che può essere di capacità zero, limitata o illimitata. A capacità zero, il mittente attende finché il destinatario non informa il mittente di aver ricevuto il messaggio. Nei casi di capacità diversa da zero, un processo non sa se un messaggio è stato ricevuto o meno dopo l'operazione di invio. Per questo, il mittente deve comunicare esplicitamente con il destinatario. L'implementazione del collegamento dipende dalla situazione, può essere un collegamento di comunicazione diretto o un collegamento di comunicazione indiretta.
Collegamenti di comunicazione diretta vengono implementati quando i processi utilizzano un identificatore di processo specifico per la comunicazione, ma è difficile identificare il mittente in anticipo.
Ad esempio il server di stampa.
Comunicazione indiretta avviene tramite una casella di posta condivisa (porta), che consiste in una coda di messaggi. Il mittente conserva il messaggio nella casella di posta e il destinatario lo ritira.
Messaggio che passa attraverso lo scambio di messaggi.
Passaggio di messaggi sincrono e asincrono:
Un processo bloccato è un processo in attesa di un evento, ad esempio la disponibilità di una risorsa o il completamento di un'operazione di I/O. L'IPC è possibile tra i processi sullo stesso computer così come sui processi in esecuzione su computer diversi, ovvero in sistemi collegati in rete/distribuiti. In entrambi i casi, il processo può essere bloccato o meno durante l'invio di un messaggio o il tentativo di ricevere un messaggio, quindi il passaggio del messaggio potrebbe essere bloccante o non bloccante. Si considera il blocco sincrono E blocco dell'invio significa che il mittente verrà bloccato finché il messaggio non verrà ricevuto dal destinatario. Allo stesso modo, blocco della ricezione ha il ricevitore bloccato finché non è disponibile un messaggio. È considerato non bloccante asincrono e Invio non bloccante fa sì che il mittente invii il messaggio e continui. Allo stesso modo, la ricezione non bloccante fa sì che il destinatario riceva un messaggio valido o nullo. Dopo un'attenta analisi, possiamo giungere alla conclusione che per un mittente è più naturale non bloccare dopo il passaggio del messaggio poiché potrebbe essere necessario inviare il messaggio a processi diversi. Tuttavia, il mittente si aspetta una conferma dal destinatario nel caso in cui l'invio fallisca. Allo stesso modo, è più naturale che un destinatario si blocchi dopo aver emesso la ricezione poiché le informazioni del messaggio ricevuto possono essere utilizzate per ulteriori esecuzioni. Allo stesso tempo, se l'invio del messaggio continua a fallire, il destinatario dovrà attendere indefinitamente. Ecco perché consideriamo anche l'altra possibilità di passaggio del messaggio. Fondamentalmente le combinazioni preferite sono tre:
- Blocco dell'invio e blocco della ricezione
- Invio non bloccante e ricezione non bloccante
- Invio non bloccante e ricezione bloccante (utilizzato principalmente)
Nel passaggio di messaggi diretti , Il processo che vuole comunicare deve nominare esplicitamente il destinatario o il mittente della comunicazione.
per esempio. invia(p1, messaggio) significa inviare il messaggio a p1.
Allo stesso modo, ricevere(p2, messaggio) significa ricevere il messaggio da p2.
In questo metodo di comunicazione, il collegamento di comunicazione viene stabilito automaticamente, che può essere unidirezionale o bidirezionale, ma un collegamento può essere utilizzato tra una coppia di mittente e destinatario e una coppia di mittente e destinatario non deve possedere più di una coppia di collegamenti. È anche possibile implementare la simmetria e l'asimmetria tra l'invio e la ricezione, ovvero entrambi i processi si nomineranno a vicenda per inviare e ricevere i messaggi oppure solo il mittente nominerà il destinatario per l'invio del messaggio e non è necessario che il destinatario nomini il mittente per ricezione del messaggio. Il problema con questo metodo di comunicazione è che se cambia il nome di un processo, questo metodo non funzionerà.
Nel passaggio di messaggi indiretti , i processi utilizzano caselle di posta (chiamate anche porte) per inviare e ricevere messaggi. Ogni casella di posta ha un ID univoco e i processi possono comunicare solo se condividono una casella di posta. Collegamento stabilito solo se i processi condividono una casella di posta comune e un singolo collegamento può essere associato a molti processi. Ciascuna coppia di processi può condividere diversi collegamenti di comunicazione e questi collegamenti possono essere unidirezionali o bidirezionali. Supponiamo che due processi vogliano comunicare tramite il passaggio di messaggi indiretti, le operazioni richieste sono: creare una casella di posta, utilizzare questa casella di posta per inviare e ricevere messaggi, quindi distruggere la casella di posta. Le primitive standard utilizzate sono: mandare un messaggio) che significa inviare il messaggio alla casella di posta A. Anche la primitiva per ricevere il messaggio funziona allo stesso modo, ad es. ricevuto (A, messaggio) . Si è verificato un problema con l'implementazione di questa casella di posta. Supponiamo che ci siano più di due processi che condividono la stessa casella di posta e supponiamo che il processo p1 invii un messaggio alla casella di posta, quale processo sarà il destinatario? Questo può essere risolto imponendo che solo due processi possano condividere una singola casella di posta o imponendo che solo un processo sia autorizzato a eseguire la ricezione in un dato momento o selezionando qualsiasi processo in modo casuale e avvisando il mittente del destinatario. Una casella di posta può essere resa privata per una singola coppia mittente/destinatario e può anche essere condivisa tra più coppie mittente/destinatario. Port è un'implementazione di tale casella di posta che può avere più mittenti e un singolo destinatario. Viene utilizzato nelle applicazioni client/server (in questo caso il server è il ricevitore). La porta è di proprietà del processo ricevente e creata dal sistema operativo su richiesta del processo ricevente e può essere distrutta su richiesta dello stesso processore ricevente quando il ricevitore termina se stesso. È possibile imporre che solo un processo possa eseguire la ricezione utilizzando il concetto di mutua esclusione. Casella di posta mutex viene creato che è condiviso da n processo. Il mittente non è bloccante e invia il messaggio. Il primo processo che esegue la ricezione entrerà nella sezione critica e tutti gli altri processi si bloccheranno e aspetteranno.
Ora discutiamo del problema produttore-consumatore utilizzando il concetto di passaggio di messaggi. Il produttore inserisce gli elementi (all'interno dei messaggi) nella casella di posta e il consumatore può consumare un elemento quando è presente almeno un messaggio nella casella di posta. Il codice è riportato di seguito:
Codice produttore
C
void> Producer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Consumer, &m);> >item = produce();> >build_message(&m , item ) ;> >send(Consumer, &m);> >}> >}> |
>
>
Codice del Consumo
C
void> Consumer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Producer, &m);> >item = extracted_item();> >send(Producer, &m);> >consume_item(item);> >}> >}> |
>
>
Esempi di sistemi IPC
- Posix: utilizza il metodo della memoria condivisa.
- Mach: utilizza il passaggio di messaggi
- Windows XP: utilizza lo scambio di messaggi utilizzando chiamate procedurali locali
Comunicazione nell'architettura client/server:
Esistono vari meccanismi:
- Tubo
- PRESA
- Chiamate procedurali remote (RPC)
I tre metodi precedenti verranno discussi negli articoli successivi poiché sono tutti abbastanza concettuali e meritano articoli separati.
Riferimenti:
- Concetti del sistema operativo di Galvin et al.
- Dispense/ppt di Ariel J. Frank, Università Bar-Ilan
La comunicazione tra processi (IPC) è il meccanismo attraverso il quale processi o thread possono comunicare e scambiare dati tra loro su un computer o attraverso una rete. L'IPC è un aspetto importante dei moderni sistemi operativi, poiché consente a diversi processi di lavorare insieme e condividere risorse, portando a una maggiore efficienza e flessibilità.
Vantaggi dell'IPC:
- Consente ai processi di comunicare tra loro e condividere risorse, portando a una maggiore efficienza e flessibilità.
- Facilita il coordinamento tra più processi, portando a migliori prestazioni complessive del sistema.
- Consente la creazione di sistemi distribuiti che possono estendersi su più computer o reti.
- Può essere utilizzato per implementare vari protocolli di sincronizzazione e comunicazione, come semafori, pipe e socket.
Svantaggi dell'IPC:
- Aumenta la complessità del sistema, rendendone più difficile la progettazione, l'implementazione e il debug.
- Può introdurre vulnerabilità di sicurezza, poiché i processi potrebbero essere in grado di accedere o modificare i dati appartenenti ad altri processi.
- Richiede un'attenta gestione delle risorse di sistema, come memoria e tempo della CPU, per garantire che le operazioni IPC non degradino le prestazioni complessive del sistema.
Può portare a incoerenze nei dati se più processi tentano di accedere o modificare gli stessi dati contemporaneamente. - Nel complesso, i vantaggi dell’IPC superano gli svantaggi, poiché è un meccanismo necessario per i moderni sistemi operativi e consente ai processi di lavorare insieme e condividere le risorse in modo flessibile ed efficiente. Tuttavia, è necessario prestare attenzione nel progettare e implementare attentamente i sistemi IPC, al fine di evitare potenziali vulnerabilità della sicurezza e problemi di prestazioni.
Ulteriori riferimenti:
http://nptel.ac.in/courses/106108101/pdf/Lecture_Notes/Mod%207_LN.pdf
https://www.youtube.com/watch?v=lcRqHwIn5Dk