Il comando Linux uniq viene utilizzato per rimuovere tutte le righe ripetute da un file. Inoltre, può essere utilizzato per visualizzare il conteggio di qualsiasi parola, solo righe ripetute, ignorare caratteri e confrontare campi specifici. È uno dei comandi più utilizzati in il Linux sistema. Viene spesso utilizzato con il comando di ordinamento perché confronta i caratteri adiacenti. Scarta tutte le righe identiche e scrive l'output.
Sintassi:
uniq [OPTION]... [INPUT [OUTPUT]]
Opzioni:
Alcune utili opzioni della riga di comando del comando uniq sono le seguenti:
-c, --count: prefissa le righe in base al numero di occorrenze.
-d, --ripetuto: viene utilizzato per stampare righe doppie, una per ciascun gruppo.
-D: Viene utilizzato per stampare tutte le righe duplicate.
--all-repeated[=METODO]: È abbastanza simile all'opzione '-D', la differenza tra entrambe le opzioni è che consente la separazione dei gruppi con una riga vuota.
-f, --skip-fields=N: Viene utilizzato per evitare il confronto dei primi N campi.
--group[=METODO]: Viene utilizzato per visualizzare tutti gli elementi e separa i gruppi con una riga vuota.
-i, --ignore-case: Viene utilizzato per ignorare le differenze durante il confronto.
-s, --skip-chars=N: Viene utilizzato per evitare il confronto dei primi N caratteri.
-u, --unique: viene utilizzato per stampare linee univoche.
-z, --zero-terminato: Viene utilizzato per il delimitatore di riga NUL e non per la modalità nuova riga.
data e ora del dattiloscritto
-w, --check-cars=N: Viene utilizzato per confrontare non più di N caratteri nelle righe.
--aiuto: Viene utilizzato per visualizzare la documentazione della guida.
--versione: Viene utilizzato per visualizzare le informazioni sulla versione.
Esempi di comando uniq
Vediamo i seguenti esempi del comando uniq:
- Rimuovi le righe ripetute
- contare il numero di occorrenze di una parola
- Visualizza le righe ripetute
- Visualizza le linee uniche
- Ignora i caratteri nel confronto
- Ignora i campi nel confronto
Rimuovi le righe ripetute
Per rimuovere righe ripetute da un file, esegui il comando uniq di base come segue:
sort dupli.txt | uniq
Il comando precedente rimuoverà le righe duplicate dal file 'dupli.txt'. Considera l'output seguente:
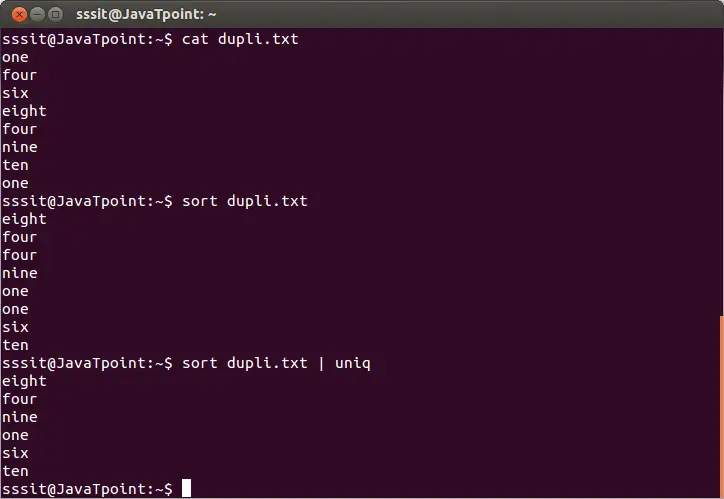
Dall'output precedente, le parole ripetute vengono ignorate.
Contare il numero di occorrenze di una parola
Possiamo contare il numero di occorrenze di una parola usando il comando uniq. L'opzione '-c' viene utilizzata per contare la parola. Eseguirlo come segue:
sort dupli.txt | uniq -c
Il comando precedente conterà le parole presenti in 'dupli.txt'. Considera l'output seguente:

Dall'output precedente, il comando 'sort dupli.txt | uniq -c' conta il numero di volte in cui una parola si ripete.
Visualizza le righe ripetute
L'opzione '-d' viene utilizzata per visualizzare solo le righe ripetute. Visualizzerà solo le righe che saranno più di una volta in un file e scriverà l'output sullo standard output. Considera il comando seguente:
sort dupli.txt | uniq -d
Il comando precedente mostrerà solo le righe ripetute. Considera l'output seguente:

Visualizza le linee uniche
L'opzione '-u' viene utilizzata per visualizzare solo le righe univoche (che non vengono ripetute). Visualizzerà solo le righe che si verificano una sola volta e scriverà il risultato sullo standard output. Considera il comando seguente:
sort dupli.txt | uniq -u
Il comando precedente visualizzerà solo le righe univoche dal file 'dupli.txt'. Considera l'output seguente:

Ignora i caratteri nel confronto
L'opzione '-s' viene utilizzata per ignorare i caratteri nel confronto. Ignorerà il numero di caratteri specificato e visualizzerà il risultato sullo standard output. Considera il comando seguente:
sort dupli.txt | uniq -s 2
Il comando precedente ignorerà i primi due caratteri rispetto al file 'dupli.txt'. Considera l'output seguente:

Ignora i campi nel confronto
L'opzione '-f' viene utilizzata per ignorare i campi. Considera il comando seguente:
uniq -f 2 dupli2.txt
Il comando precedente non confronterà i primi due campi del file 'dupli2.txt'. Considera l'output seguente:

Dall'output precedente, i primi due campi vengono saltati e il resto di tutti i campi viene confrontato dal file 'dupli2.txt'.