La regressione logistica nella programmazione R è un algoritmo di classificazione utilizzato per trovare la probabilità di successo e di fallimento dell'evento. La regressione logistica viene utilizzata quando la variabile dipendente è di natura binaria (0/1, vero/falso, sì/no). La funzione logit viene utilizzata come funzione di collegamento in una distribuzione binomiale.
La probabilità di una variabile di risultato binaria può essere prevista utilizzando la tecnica di modellazione statistica nota come regressione logistica. È ampiamente utilizzato in molti settori diversi, tra cui marketing, finanza, scienze sociali e ricerca medica.
La funzione logistica, comunemente chiamata funzione sigmoidea, è l'idea di base alla base della regressione logistica. Questa funzione sigmoidea viene utilizzata nella regressione logistica per descrivere la correlazione tra le variabili predittive e la probabilità del risultato binario.

Regressione logistica nella programmazione R
La regressione logistica è anche nota come Regressione logistica binomiale . Si basa sulla funzione sigmoide in cui l'output è la probabilità e l'input può variare da -infinito a +infinito.
Teoria
La regressione logistica è anche nota come modello lineare generalizzato. Poiché viene utilizzato come tecnica di classificazione per prevedere una risposta qualitativa, il valore di y varia da 0 a 1 e può essere rappresentato dalla seguente equazione:
Regressione logistica nella programmazione R
P è la probabilità della caratteristica di interesse. L'odds ratio è definito come la probabilità di successo rispetto alla probabilità di fallimento. È una rappresentazione chiave dei coefficienti di regressione logistica e può assumere valori compresi tra 0 e infinito. Il rapporto di probabilità di 1 è quando la probabilità di successo è uguale alla probabilità di fallimento. L'odds ratio di 2 è quando la probabilità di successo è il doppio della probabilità di fallimento. L'odds ratio di 0,5 è quando la probabilità di fallimento è il doppio della probabilità di successo.
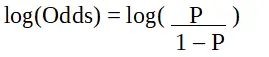
Regressione logistica nella programmazione R
Poiché stiamo lavorando con una distribuzione binomiale (variabile dipendente), dobbiamo scegliere una funzione di collegamento più adatta a questa distribuzione.
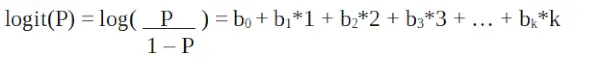
Regressione logistica nella programmazione R
È un funzione logit . Nell'equazione sopra, la parentesi viene scelta per massimizzare la probabilità di osservare i valori del campione piuttosto che ridurre al minimo la somma degli errori quadrati (come la regressione ordinaria). Il logit è noto anche come registro delle probabilità. La funzione logit deve essere correlata linearmente alle variabili indipendenti. Questo deriva dall'equazione A, dove il lato sinistro è una combinazione lineare di x. Ciò è simile all'ipotesi OLS secondo cui y è linearmente correlato a x. Le variabili b0, b1, b2… ecc sono sconosciute e devono essere stimate sui dati di addestramento disponibili. In un modello di regressione logistica, moltiplicando b1 per un'unità si modifica il logit di b0. Le variazioni di P dovute ad una variazione di una unità dipenderanno dal valore moltiplicato. Se b1 è positivo allora P aumenterà mentre se b1 è negativo allora P diminuirà.
Il set di dati
mtcars (test su strada per auto di tendenza) comprende il consumo di carburante, le prestazioni e 10 aspetti della progettazione automobilistica per 32 automobili. Viene preinstallato con dplyr pacchetto in R.
R
# Installing the package> install.packages>(>'dplyr'>)> # Loading package> library>(dplyr)> # Summary of dataset in package> summary>(mtcars)> |
>
>
Esecuzione di una regressione logistica su un set di dati
La regressione logistica viene implementata in R utilizzando glm() addestrando il modello utilizzando funzionalità o variabili nel set di dati.
R
array Java ordinato
# Installing the package> # For Logistic regression> install.packages>(>'caTools'>)> # For ROC curve to evaluate model> install.packages>(>'ROCR'>)> > # Loading package> library>(caTools)> library>(ROCR)> |
>
>
Suddivisione dei dati
R
# Splitting dataset> split <->sample.split>(mtcars, SplitRatio = 0.8)> split> train_reg <->subset>(mtcars, split ==>'TRUE'>)> test_reg <->subset>(mtcars, split ==>'FALSE'>)> # Training model> logistic_model <->glm>(vs ~ wt + disp,> >data = train_reg,> >family =>'binomial'>)> logistic_model> # Summary> summary>(logistic_model)> |
>
>
Produzione:
Call: glm(formula = vs ~ wt + disp, family = 'binomial', data = train_reg) Deviance Residuals: Min 1Q Median 3Q Max -1.6552 -0.4051 0.4446 0.6180 1.9191 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercetta) 1,58781 2,60087 0,610 0,5415 wt 1,36958 1,60524 0,853 0,3936 disp -0,02969 0,01577 -1,882 0,0598 . --- Signif. codici: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Parametro di dispersione per famiglia binomiale considerato pari a 1) Devianza nulla: 34.617 su 24 gradi di libertà Devianza residua: 20.212 su 22 gradi di libertà AIC: 26.212 Numero di iterazioni del punteggio Fisher: 6>
- Chiamata: viene visualizzata la chiamata della funzione utilizzata per adattare il modello di regressione logistica, insieme alle informazioni sulla famiglia, sulla formula e sui dati. Residui di devianza: questi sono i residui di devianza, che misurano il grado di bontà di adattamento del modello. Rappresentano discrepanze tra le risposte effettive e la probabilità prevista dal modello di regressione logistica. Coefficienti: questi coefficienti nella regressione logistica rappresentano le probabilità di log o logit della variabile di risposta. Gli errori standard relativi ai coefficienti stimati sono riportati nella tabella Std. Colonna Errore. Codici di significatività: il livello di significatività di ciascuna variabile predittrice è indicato dai codici di significatività. Parametro di dispersione: nella regressione logistica, il parametro di dispersione funge da parametro di ridimensionamento per la distribuzione binomiale. In questo caso è impostato su 1, indicando che la dispersione presunta è 1. Devianza nulla: la devianza nulla calcola la deviazione del modello quando viene presa in considerazione solo l'intercetta. Simboleggia la deviazione che risulterebbe da un modello senza predittori. Devianza residua: la devianza residua calcola la deviazione del modello dopo l'adattamento dei predittori. Rappresenta la deviazione residua dopo aver preso in considerazione i predittori. AIC: l’Akaike Information Criterion (AIC), che tiene conto del numero di predittori, è un indicatore della bontà di adattamento di un modello. Penalizza i modelli più complessi per evitare un overfitting. I modelli con adattamento migliore sono indicati da valori AIC inferiori. Numero di iterazioni del punteggio Fisher: il numero di iterazioni necessarie alla procedura del punteggio Fisher per stimare i parametri del modello è indicato dal numero di iterazioni.
Prevedere i dati dei test in base al modello
R
predict_reg <->predict>(logistic_model,> >test_reg, type =>'response'>)> predict_reg> |
>
>
Produzione:
Hornet Sportabout Merc 280C Merc 450SE Chrysler Imperial 0.01226166 0.78972164 0.26380531 0.01544309 AMC Javelin Camaro Z28 Ford Pantera L 0.06104267 0.02807992 0.01107943>
R
# Changing probabilities> predict_reg <->ifelse>(predict_reg>0.5, 1, 0)> # Evaluating model accuracy> # using confusion matrix> table>(test_reg$vs, predict_reg)> missing_classerr <->mean>(predict_reg != test_reg$vs)> print>(>paste>(>'Accuracy ='>, 1 - missing_classerr))> # ROC-AUC Curve> ROCPred <->prediction>(predict_reg, test_reg$vs)> ROCPer <->performance>(ROCPred, measure =>'tpr'>,> >x.measure =>'fpr'>)> auc <->performance>(ROCPred, measure =>'auc'>)> auc <- [email protected][[1]]> auc> # Plotting curve> plot>(ROCPer)> plot>(ROCPer, colorize =>TRUE>,> >print.cutoffs.at =>seq>(0.1, by = 0.1),> >main =>'ROC CURVE'>)> abline>(a = 0, b = 1)> auc <->round>(auc, 4)> legend>(.6, .4, auc, title =>'AUC'>, cex = 1)> |
>
>
Produzione:
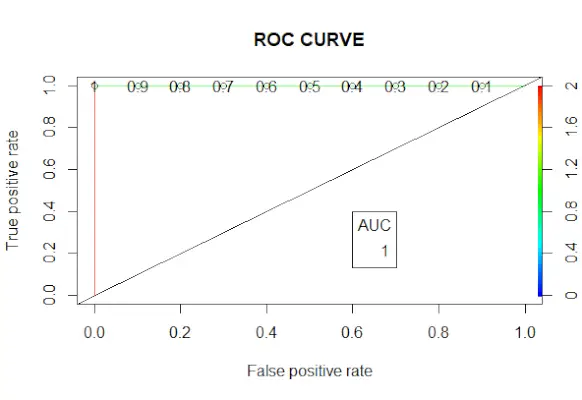
Curva ROC
Esempio 2:
Possiamo eseguire un modello di regressione logistica Titanic Data Set in R.
R
# Load the dataset> data>(Titanic)> # Convert the table to a data frame> data <->as.data.frame>(Titanic)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # View the summary of the model> summary>(model)> |
>
>
Produzione:
Call: glm(formula = Survived ~ Class + Sex + Age, family = binomial, data = data) Deviance Residuals: Min 1Q Median 3Q Max -1.177 -1.177 0.000 1.177 1.177 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercetta) 4.022e-16 8.660e-01 0 1 Classe2nd -9.762e-16 1.000e+00 0 1 Classe3rd -4.699e-16 1.000e+00 0 1 ClassCrew -5.551e-16 1.000e+ 00 0 1 SexFemale -3.140e-16 7.071e-01 0 1 AgeAdult 5.103e-16 7.071e-01 0 1 (Parametro di dispersione per la famiglia binomiale considerato pari a 1) Devianza nulla: 44.361 su 31 gradi di libertà Devianza residua: 44.361 su 26 gradi di libertà AIC: 56.361 Numero di iterazioni del punteggio Fisher: 2>
Traccia la curva ROC per il set di dati del Titanic
R
# Install and load the required packages> install.packages>(>'ROCR'>)> library>(ROCR)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # Make predictions on the dataset> predictions <->predict>(model, type =>'response'>)> # Create a prediction object for ROCR> prediction_objects <->prediction>(predictions, titanic_df$Survived)> # Create an ROC curve object> roc_object <->performance>(prediction_obj, measure =>'tpr'>, x.measure =>'fpr'>)> # Plot the ROC curve> plot>(roc_object, main =>'ROC Curve'>, col =>'blue'>, lwd = 2)> # Add labels and a legend to the plot> legend>(>'bottomright'>, legend => >paste>(>'AUC ='>,>round>(>performance>(prediction_objects, measure =>'auc'>)> >@y.values[[1]], 2)), col =>'blue'>, lwd = 2)> |
>
>
Produzione:
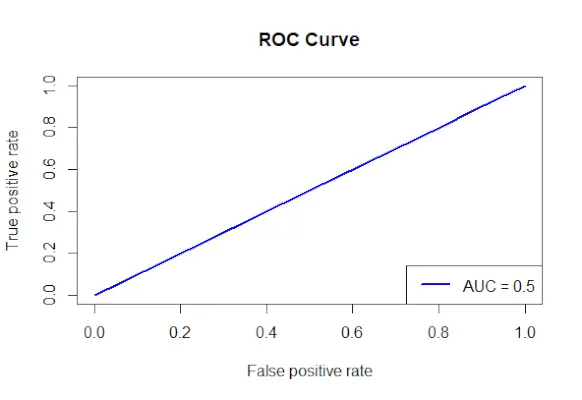
Curva ROC
- Vengono specificati i fattori utilizzati per prevedere i sopravvissuti e la formula Classe sopravvissuta + Sesso + Età viene utilizzata per creare un modello di regressione logistica.
- Utilizzando la funzione predit(), le previsioni vengono effettuate sul set di dati utilizzando il modello adattato.
- Le probabilità previste vengono combinate con i valori dei risultati effettivi per creare un oggetto di previsione utilizzando il metodo predizione() del pacchetto ROCR.
- Vengono specificate la misura del tasso di veri positivi (tpr) e la misura dell'asse x del tasso di falsi positivi (fpr) e viene creato un oggetto curva ROC utilizzando la funzione performance() del pacchetto ROCR.
- L'oggetto curva ROC (roc_obj), che specifica il titolo principale, il colore e la larghezza della linea, viene tracciato utilizzando la funzione plot().
- Utilizza la funzione performance() con Measure = auc per determinare il valore AUC (area sotto la curva) e aggiunge etichette e una legenda al grafico.