Panda dataframe.corr() viene utilizzato per trovare la correlazione a coppie di tutte le colonne nel Pandas Dataframe in Python. Qualunque NaN i valori vengono automaticamente esclusi. Per ignorare eventuali valori non numerici, utilizzare il parametro numeric_only = True. In questo articolo impareremo il metodo DataFrame.corr() in Pitone .
Sintassi del metodo Pandas DataFrame corr()
Sintassi: DataFrame.corr(self, metodo='pearson', min_periods=1, numeric_only = False)
parametri:
- metodo :
- Pearson: coefficiente di correlazione standard
- kendall: coefficiente di correlazione Kendall Tau
- Spearman: correlazione tra i ranghi di Spearman
- periodi_min: Numero minimo di osservazioni richieste per coppia di colonne per ottenere un risultato valido. Attualmente disponibile solo per la correlazione Pearson e Spearman
- numeric_only: indica se si deve operare solo sui valori numerici o meno. È impostato su False per impostazione predefinita.
Ritorna: conteggio: y: DataFrame
Metodo corr() delle correlazioni dei dati di Pandas
Una buona correlazione dipende dall'uso, ma si può dire con certezza che ne hai almeno 0,6 (o -0,6) per definirla una buona correlazione. Un semplice esempio per mostrare come funziona la correlazione Pitone .
Python3
conversione di int in stringa in Java
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Produzione
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Creazione di un dataframe di esempio
Stampa delle prime 10 righe del Dataframe.
Nota: La correlazione di una variabile con se stessa è 1. Per un collegamento al file CSV utilizzato nel codice, fare clic su Qui
Python3
percorso impostato in Java
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Produzione

Esempi di metodi DataFrame corr() di Python Pandas
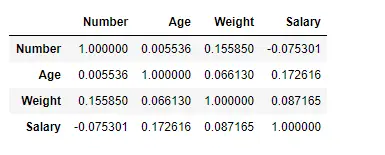
Trova la correlazione tra le colonne utilizzando il metodo Pearson
Qui, stiamo utilizzando la funzione corr() per trovare la correlazione tra le colonne nel Dataframe utilizzando il metodo 'Pearson'. Abbiamo solo quattro colonne numeriche nel Dataframe. Il Dataframe di output può essere interpretato come per qualsiasi cella, la correlazione della variabile di riga con la variabile di colonna è il valore della cella. Come accennato in precedenza, la correlazione di una variabile con se stessa è 1. Per questo motivo tutti i valori diagonali sono 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
strumento di cattura in Ubuntu
Produzione
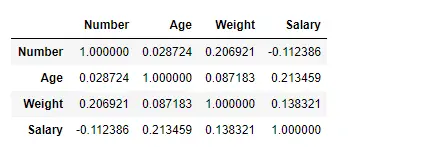
Trova la correlazione tra le colonne utilizzando il metodo Kendall
Utilizza la funzione Panda df.corr() per trovare la correlazione tra le colonne nel Dataframe utilizzando il metodo 'kendall'. Il Dataframe di output può essere interpretato come per qualsiasi cella, la correlazione della variabile di riga con la variabile di colonna è il valore della cella. Come accennato in precedenza, la correlazione di una variabile con se stessa è 1. Per questo motivo tutti i valori diagonali sono 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
coda in Java
>
>
Produzione