Python è un ottimo linguaggio per l'analisi dei dati, principalmente a causa del fantastico ecosistema incentrato sui dati Pitone Pacchetti. Panda è uno di quei pacchetti e rende l'importazione e l'analisi dei dati molto più semplice.
Panda DataFrame significa()
Panda dataframe.media() la funzione restituisce la media dei valori per l'asse richiesto. Se il metodo viene applicato su un oggetto della serie panda, il metodo restituisce un valore scalare che è il valore medio di tutte le osservazioni nell'oggetto Panda Dataframe . Se il metodo viene applicato a un oggetto Pandas Dataframe, il metodo restituisce a Serie Panda oggetto che contiene la media dei valori sull'asse specificato.
Sintassi: DataFrame.mean(axis=0, skipna=True, level=Nessuno, numeric_only=False, **kwargs)
Parametri:
- asse: {indice (0), colonne (1)}
- ordine : Escludere valori NA/nulli durante il calcolo del risultato
- livello: Se l'asse è un MultiIndice (gerarchico), conta lungo un particolare livello, collassando in una Serie
- solo_numerico: Include solo colonne float, int e booleane. Se Nessuno, tenterà di utilizzare tutto, quindi utilizzerà solo dati numerici. Non implementato per le serie.
Ritorna : significa: serie o DataFrame (se il livello specificato)
array di stringhe in linguaggio c
Esempi di Panda DataFrame.mean()
Esempio 1:
Utilizzare la funzione mean() per trovare la media di tutte le osservazioni sull'asse dell'indice.
Pitone # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 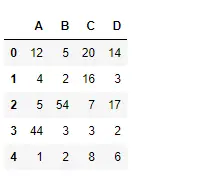
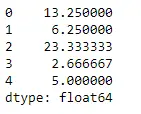
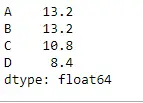
Usiamo la funzione Dataframe.mean() per trovare la media sull'asse dell'indice.
Pitone # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Produzione:
Esempio 2:
Utilizzare la funzione mean() su un Dataframe con valori None. Inoltre, trova la media sull'asse della colonna.
Pitone # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Produzione: