Nel sistema operativo, dovevamo fornire l'input alla CPU e la CPU esegue le istruzioni e infine fornisce l'output. Ma c’era un problema con questo approccio. In una situazione normale, abbiamo a che fare con molti processi, e sappiamo che il tempo impiegato nell'operazione di I/O è molto grande rispetto al tempo impiegato dalla CPU per l'esecuzione delle istruzioni. Quindi, nel vecchio approccio, un processo fornirà l'input con l'aiuto di un dispositivo di input e durante questo periodo la CPU è in uno stato inattivo.
xor in C++
Quindi la CPU esegue l'istruzione e l'output viene nuovamente fornito a qualche dispositivo di output e, in questo momento, anche la CPU è in uno stato inattivo. Dopo aver mostrato l'output, il processo successivo inizia la sua esecuzione. Quindi, per la maggior parte del tempo, la CPU è inattiva, che è la condizione peggiore che possiamo avere nei sistemi operativi. Qui entra in gioco il concetto di Spooling.
Cos'è lo spooling
Lo spooling è un processo in cui i dati vengono temporaneamente conservati per essere utilizzati ed eseguiti da un dispositivo, programma o sistema. I dati vengono inviati e archiviati nella memoria o in un altro dispositivo di archiviazione volatile finché il programma o il computer non ne richiede l'esecuzione.
SPOOL è l'acronimo di operazioni periferiche simultanee online . In genere, lo spool viene mantenuto nella memoria fisica del computer, nei buffer o negli interrupt specifici del dispositivo I/O. Lo spool viene elaborato in ordine crescente, lavorando in base a un algoritmo FIFO (first-in, first-out).
Lo spooling si riferisce all'inserimento dei dati di vari lavori I/O in un buffer. Questo buffer è un'area speciale nella memoria o nel disco rigido accessibile ai dispositivi I/O. Un sistema operativo svolge le seguenti attività legate all'ambiente distribuito:
- Gestisce lo spooling dei dati del dispositivo I/O poiché i dispositivi hanno velocità di accesso ai dati diverse.
- Mantiene il buffer di spooling, che fornisce una stazione di attesa in cui i dati possono riposare mentre il dispositivo più lento li raggiunge.
- Mantiene il calcolo parallelo grazie al processo di spooling poiché un computer può eseguire I/O in ordine parallelo. Diventa possibile fare in modo che il computer legga i dati da un nastro, scriva i dati su disco e li scriva su una stampante a nastro mentre sta eseguendo il suo compito di elaborazione.
Come funziona lo spooling nel sistema operativo
In un sistema operativo, lo spooling funziona nei seguenti passaggi, come ad esempio:
- Lo spooling implica la creazione di un buffer chiamato SPOOL, che viene utilizzato per trattenere lavori e dati finché il dispositivo in cui viene creato SPOOL non è pronto per utilizzare ed eseguire quel lavoro o operare sui dati.
- Quando un dispositivo più veloce invia dati a un dispositivo più lento per eseguire alcune operazioni, utilizza l'eventuale memoria secondaria collegata come buffer SPOOL. Questi dati vengono mantenuti nello SPOOL finché il dispositivo più lento non è pronto a operare su questi dati. Quando il dispositivo più lento è pronto, allora i dati presenti nello SPOOL vengono caricati nella memoria principale per le operazioni richieste.
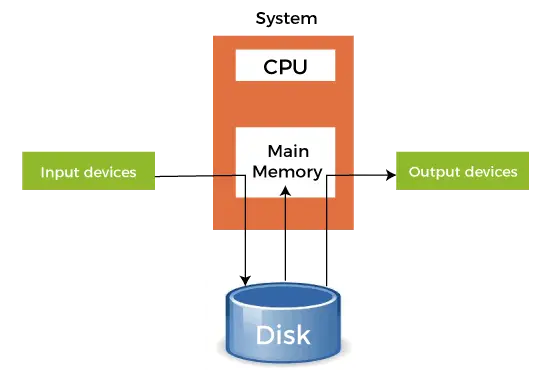
- Lo spooling considera l'intera memoria secondaria come un enorme buffer in grado di archiviare molti lavori e dati per molte operazioni. Il vantaggio dello spooling è che può creare una coda di lavori che vengono eseguiti in ordine FIFO per eseguire i lavori uno per uno.
- Un dispositivo può connettersi a molti dispositivi di input, che potrebbero richiedere alcune operazioni sui relativi dati. Quindi, tutti questi dispositivi di input possono inserire i propri dati nella memoria secondaria (SPOOL), che può poi essere eseguita uno per uno dal dispositivo. Ciò assicurerà che la CPU non sia mai inattiva. Quindi, possiamo dire che lo spooling è una combinazione di buffering e accodamento.
- Dopo che la CPU ha generato un output, questo output viene prima salvato nella memoria principale. Questa uscita viene trasferita dalla memoria principale alla memoria secondaria e da lì l'uscita viene inviata ai rispettivi dispositivi di uscita.

Esempio di spooling
Il più grande esempio di spooling è stampa . I documenti da stampare vengono memorizzati nello SPOOL e poi aggiunti alla coda per la stampa. Durante questo periodo, molti processi possono eseguire le proprie operazioni e utilizzare la CPU senza attendere che la stampante esegua il processo di stampa sui documenti uno per uno.

Molte funzionalità possono anche essere aggiunte al processo di stampa in spooling, come l'impostazione delle priorità o la notifica quando il processo di stampa è stato completato o la selezione dei diversi tipi di carta su cui stampare in base alla scelta dell'utente.
Vantaggi dello spooling
Ecco i seguenti vantaggi dello spooling in un sistema operativo, come ad esempio:
- Il numero di dispositivi o operazioni I/O non ha importanza. Molti dispositivi I/O possono funzionare insieme simultaneamente senza alcuna interferenza o interruzione reciproca.
- Nello spooling non c'è interazione tra i dispositivi I/O e la CPU. Ciò significa che non è necessario che la CPU attenda l'esecuzione delle operazioni di I/O. Tali operazioni richiedono molto tempo per terminare l'esecuzione, quindi la CPU non aspetterà che finiscano.
- La CPU nello stato inattivo non è considerata molto efficiente. La maggior parte dei protocolli viene creata per utilizzare la CPU in modo efficiente nel minor tempo possibile. Nello spooling, la CPU viene tenuta occupata per la maggior parte del tempo e passa allo stato inattivo solo quando la coda è esaurita. Pertanto, tutte le attività vengono aggiunte alla coda e la CPU le completerà e poi entrerà nello stato di inattività.
- Consente alle applicazioni di funzionare alla velocità della CPU mentre i dispositivi I/O funzionano alla massima velocità.
Svantaggi dello spooling
In un sistema operativo, lo spooling presenta i seguenti svantaggi, quali:
- Lo spooling richiede una grande quantità di spazio di archiviazione a seconda del numero di richieste effettuate dall'input e del numero di dispositivi di input collegati.
- Poiché lo SPOOL viene creato nella memoria secondaria, il fatto che molti dispositivi di input funzionino simultaneamente potrebbe occupare molto spazio nella memoria secondaria e quindi aumentare il traffico su disco. Ciò fa sì che il disco diventi sempre più lento man mano che il traffico aumenta sempre di più.
- Lo spooling viene utilizzato per copiare ed eseguire dati da un dispositivo più lento a un dispositivo più veloce. Il dispositivo più lento crea uno SPOOL per memorizzare i dati su cui operare in una coda e la CPU lavora su di esso. Questo processo di per sé rende inutile lo spooling da utilizzare in ambienti in tempo reale in cui sono necessari risultati in tempo reale dalla CPU. Questo perché il dispositivo di input è più lento e quindi produce i dati a un ritmo più lento mentre la CPU può funzionare più velocemente, quindi passa al processo successivo nella coda. Questo è il motivo per cui il risultato finale o l'output viene prodotto in un secondo momento anziché in tempo reale.
Differenza tra spooling e buffering
Lo spooling e il buffering sono i due modi in cui i sottosistemi I/O migliorano le prestazioni e l'efficienza del computer utilizzando uno spazio di archiviazione nella memoria principale o sul disco.
modello di progettazione Java

La differenza fondamentale tra lo spooling e il buffering è che lo spooling sovrappone l'I/O di un lavoro all'esecuzione di un altro lavoro. In confronto, il buffering sovrappone l'I/O di un lavoro all'esecuzione dello stesso lavoro. Di seguito sono riportate alcune ulteriori differenze tra spooling e buffering, ad esempio:
| Termini | Avvolgimento | Bufferizzazione |
|---|---|---|
| Definizione | Lo spooling, acronimo di Simultaneous Peripheral Operation Online (SPOOL), inserisce i dati in un'area di lavoro temporanea per consentire l'accesso e l'elaborazione da parte di un altro programma o risorsa. | Il buffering è l'atto di archiviare temporaneamente i dati nel buffer. Aiuta a far corrispondere la velocità del flusso di dati tra mittente e destinatario. |
| Requisito di risorse | Lo spooling richiede una minore gestione delle risorse poiché diverse risorse gestiscono il processo per lavori specifici. | Il buffering richiede una maggiore gestione delle risorse poiché la stessa risorsa gestisce il processo dello stesso lavoro suddiviso. |
| Implementazione interna | Lo spooling sovrappone l'input e l'output di un lavoro al calcolo di un altro lavoro. | Il buffering sovrappone l'input e l'output di un lavoro al calcolo dello stesso lavoro. |
| Efficiente | Lo spooling è più efficiente del buffering. | Il buffering è meno efficiente dello spooling. |
| Processore | Lo spooling può anche elaborare i dati in siti remoti. Lo spooler deve solo avvisare quando un processo viene completato nel sito remoto per eseguire lo spooling del processo successivo sul dispositivo lato remoto. | Il buffering non supporta l'elaborazione remota. |
| Dimensioni in memoria | Considera il disco come un enorme spool o buffer. | Il buffer è un'area limitata nella memoria principale. |