- Redshift è un servizio di data warehouse nel cloud veloce e potente, completamente gestito e su scala petabyte.
- I clienti possono utilizzare Redshift per soli 0,25 dollari l'ora senza impegni o costi iniziali e scalare fino a un petabyte o più per 1.000 dollari per terabyte all'anno.
OLAP
OLAP è un Sistema di elaborazione di analisi online utilizzato dal Spostamento verso il rosso .
Transazione OLAP Esempio:
Supponiamo di voler calcolare l'utile netto per l'area EMEA e Pacifico per il prodotto radio digitale. Ciò richiede il pull di un gran numero di record. Di seguito sono riportati i record necessari per calcolare un utile netto:
- Somma delle radio vendute nell'area EMEA.
- Somma delle radio vendute nel Pacifico.
- Costo unitario della radio in ciascuna regione.
- Prezzo di vendita di ogni radio
- Prezzo di vendita - costo unitario
Le query complesse sono necessarie per recuperare i record indicati sopra. I database di data warehousing utilizzano architetture di tipo diverso sia dal punto di vista del database che dal livello dell'infrastruttura.
Configurazione del redshift
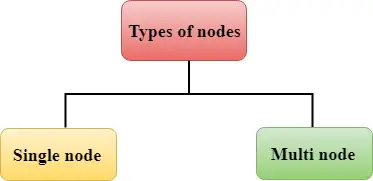
Redshift è costituito da due tipi di nodi:
Singolo nodo: Un singolo nodo memorizza fino a 160 GB.
Multinodo: Il multinodo è un nodo costituito da più di un nodo. È di due tipi:
Gestisce le connessioni client e riceve le query. Un nodo leader riceve le query dalle applicazioni client, le analizza e sviluppa i piani di esecuzione. Si coordina con l'esecuzione parallela di questi piani con il nodo di calcolo e combina i risultati intermedi di tutti i nodi, per poi restituire il risultato finale all'applicazione client.
Un nodo di calcolo esegue i piani di esecuzione, quindi i risultati intermedi vengono inviati al nodo leader per l'aggregazione prima di essere rinviati all'applicazione client. Può avere fino a 128 nodi di calcolo.
Comprendiamo il concetto di nodo leader e di nodo di calcolo attraverso un esempio.
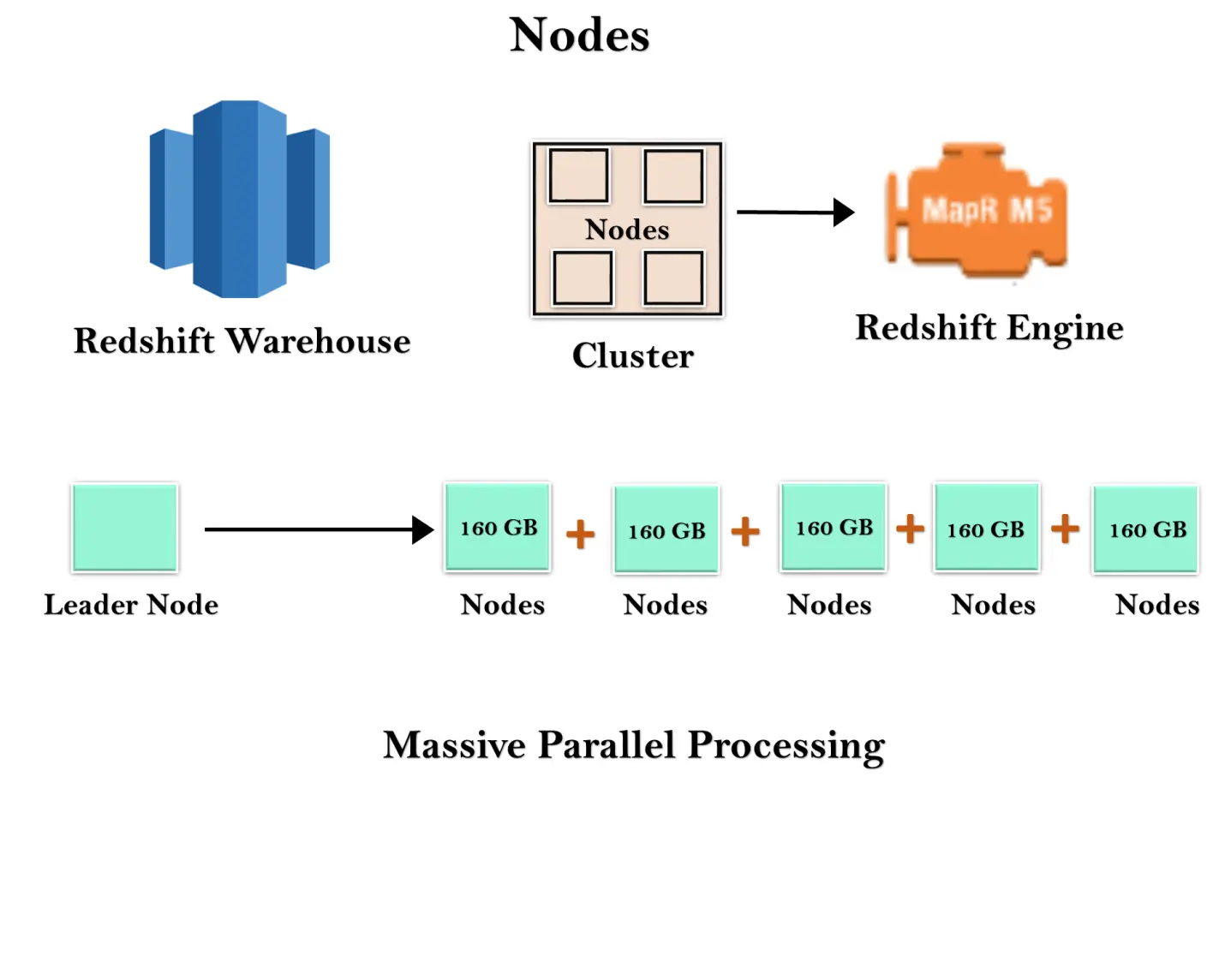
Il magazzino Redshift è una raccolta di risorse informatiche note come nodi e questi nodi sono organizzati in un gruppo noto come cluster. Ogni cluster viene eseguito in un motore Redshift che contiene uno o più database.
Quando avvii un'istanza Redshift, inizia con un singolo nodo di dimensioni 160 GB. Quando vuoi crescere, puoi aggiungere ulteriori nodi per sfruttare l'elaborazione parallela. Hai un nodo leader che gestisce più nodi. Il nodo leader gestisce la connessione client e i nodi di calcolo. Memorizza i dati nei nodi di calcolo ed esegue la query.
Perché Redshift è 10 volte più veloce
Il Redshift è 10 volte più veloce per i seguenti motivi:
Invece di archiviare i dati come serie di righe, Amazon Redshift li organizza per colonne. I sistemi basati su righe sono ideali per l'elaborazione delle transazioni, mentre i sistemi basati su colonne sono ideali per il data warehousing e l'analisi, dove le query spesso coinvolgono aggregati eseguiti su set di dati di grandi dimensioni. Poiché vengono elaborate solo le colonne coinvolte nelle query e i dati colonnari vengono archiviati in un supporto di memorizzazione in sequenza, i sistemi basati su colonne richiedono meno I/O, migliorando così le prestazioni delle query.
Gli archivi dati a colonne possono essere compressi molto più degli archivi dati basati su righe perché dati simili vengono archiviati in sequenza sul disco. Amazon Redshift utilizza più tecniche di compressione e spesso può ottenere una compressione significativa rispetto ai tradizionali archivi dati relazionali.
Amazon Redshift non richiede indici o viste materializzate, quindi richiede meno spazio rispetto ai tradizionali sistemi di database relazionali. Quando carichi i dati in una tabella vuota, Amazon Redshift campiona automaticamente i dati e seleziona la tecnica di compressione più appropriata.
Amazon Redshift distribuisce automaticamente i dati e carica la query su vari nodi. Amazon Redshift semplifica l'aggiunta di nuovi nodi al tuo data warehouse e questo ci consente di ottenere prestazioni di query più veloci man mano che il tuo data warehouse cresce.
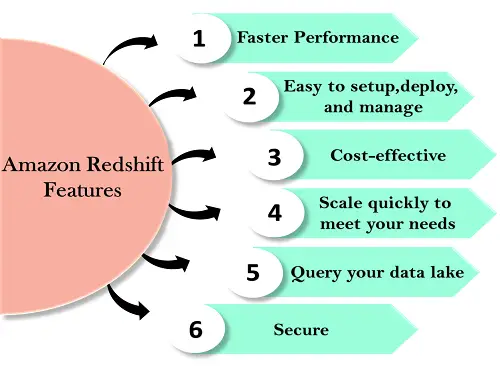
Funzionalità del redshift
Le caratteristiche di Redshift sono riportate di seguito:
regex Java
Redshift è semplice da configurare e utilizzare. Puoi distribuire un nuovo data warehouse con pochi clic nella console AWS e Redshift effettua automaticamente il provisioning dell'infrastruttura per te. In AWS, tutte le attività amministrative sono automatizzate, come backup e replica, devi concentrarti sui tuoi dati, non sull'amministrazione.
Redshift esegue automaticamente il backup dei tuoi dati su S3. Puoi anche replicare gli snapshot in S3 in un'altra regione per qualsiasi ripristino di emergenza.
Amazon Redshift è il servizio di data warehouse più conveniente in quanto devi pagare solo per ciò che utilizzi.
I suoi costi partono da 0,25 dollari l'ora senza impegno né costi iniziali e possono arrivare fino a 250 dollari per terabyte all'anno.
Amazon Redshift è l'unico servizio di data warehouse che offre prezzi on demand senza costi iniziali e offre anche prezzi per istanze riservate che consentono di risparmiare fino al 75% fornendo una durata di 1-3 anni.
Puoi scegliere uno dei due nodi per ottimizzare il Redshift.
Il nodo di calcolo denso può creare data warehouse ad alte prestazioni utilizzando CPU veloci, una grande quantità di RAM e dischi a stato solido.
Se desideri ridurre i costi, puoi utilizzare il nodo di archiviazione denso. Crea un data warehouse conveniente utilizzando un disco rigido più grande.
Amazon Redshift aumenta o riduce automaticamente i nodi in base alle modifiche delle necessità. Con pochi clic nella console AWS o una singola chiamata API puoi modificare facilmente il numero di nodi in un data warehouse.
È una funzionalità di Redshift che ti consente di eseguire query su exabyte di dati in Amazon S3. Amazon S3 è un sistema sicuro ed economico per archiviare dati illimitati in un formato aperto.
È una funzionalità di Redshift che consente a più query di accedere agli stessi dati in Amazon S3. Ti consente di eseguire query su più nodi indipendentemente dalla complessità di una query o dalla quantità di dati.
Amazon Redshift è l'unico data warehouse utilizzato per eseguire query sul data Lake Amazon S3 senza caricare dati. Ciò garantisce flessibilità archiviando i dati ad accesso frequente in Redshift e i dati non strutturati o ad accesso poco frequente in Amazon S3.
Con un paio di impostazioni dei parametri, puoi impostare Redshift per utilizzare SSL per proteggere i tuoi dati. Puoi anche abilitare la crittografia, tutti i dati scritti sul disco verranno crittografati.
Amazon Redshift fornisce storage di dati colonnari, compressione ed elaborazione parallela per ridurre la quantità di I/O necessaria per eseguire query. Ciò migliora le prestazioni delle query.