Sin dall'invenzione dei computer, le persone hanno utilizzato il termine ' Dati ' per fare riferimento alle informazioni del computer, trasmesse o archiviate. Tuttavia, esistono dati anche nei tipi di ordine. I dati possono essere numeri o testi scritti su un pezzo di carta, sotto forma di bit e byte archiviati nella memoria di dispositivi elettronici, oppure fatti archiviati nella mente di una persona. Con l'inizio della modernizzazione del mondo, questi dati sono diventati un aspetto significativo della vita quotidiana di tutti e varie implementazioni hanno consentito di archiviarli in modo diverso.
Dati è una raccolta di fatti e cifre o un insieme di valori o valori di un formato specifico che si riferisce a un singolo insieme di valori di elementi. Gli elementi di dati vengono quindi classificati in sottoelementi, ovvero il gruppo di elementi che non sono noti come forma primaria semplice dell'elemento.
Consideriamo un esempio in cui il nome di un dipendente può essere suddiviso in tre sottoelementi: Primo, Secondo e Ultimo. Tuttavia, un ID assegnato a un dipendente verrà generalmente considerato un singolo elemento.
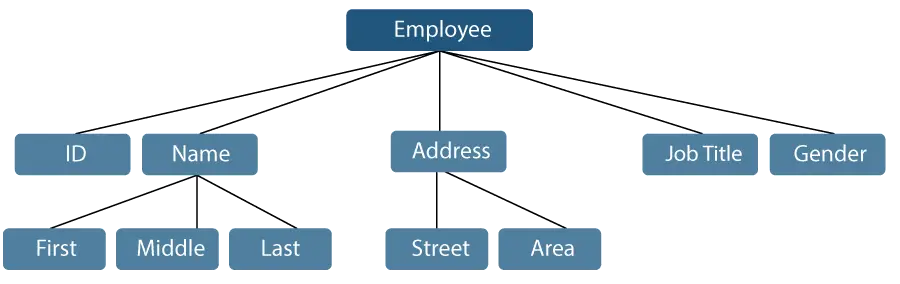
Figura 1: Rappresentazione dei dati
Nell'esempio sopra menzionato, elementi come ID, Età, Sesso, Nome, Secondo, Cognome, Via, Località, ecc., sono elementi di dati elementari. Al contrario, il Nome e l'Indirizzo sono elementi di dati di gruppo.
Cos'è la struttura dei dati?
Struttura dati è una branca dell'informatica. Lo studio della struttura dei dati ci consente di comprendere l'organizzazione dei dati e la gestione del flusso di dati al fine di aumentare l'efficienza di qualsiasi processo o programma. La struttura dei dati è un modo particolare di archiviare e organizzare i dati nella memoria del computer in modo che questi dati possano essere facilmente recuperati e utilizzati in modo efficiente in futuro quando richiesto. I dati possono essere gestiti in vari modi, ad esempio il modello logico o matematico per una specifica organizzazione dei dati è noto come struttura dati.
L'ambito di un particolare modello di dati dipende da due fattori:
- Innanzitutto, deve essere caricato nella struttura in modo tale da riflettere la correlazione definita dei dati con un oggetto del mondo reale.
- In secondo luogo, la formazione dovrebbe essere così semplice da poter essere adattata per elaborare i dati in modo efficiente ogni volta che è necessario.
Alcuni esempi di strutture dati sono array, elenchi collegati, stack, code, alberi, ecc. Le strutture dati sono ampiamente utilizzate in quasi tutti gli aspetti dell'informatica, ad esempio progettazione di compilatori, sistemi operativi, grafica, intelligenza artificiale e molti altri.
Le strutture dati sono la parte principale di molti algoritmi informatici poiché consentono ai programmatori di gestire i dati in modo efficace. Svolge un ruolo cruciale nel migliorare le prestazioni di un programma o software, poiché l'obiettivo principale del software è archiviare e recuperare i dati dell'utente il più velocemente possibile.
polimorfismo di Java
Terminologie di base relative alle strutture dati
Le strutture dati sono gli elementi costitutivi di qualsiasi software o programma. Selezionare la struttura dati adatta per un programma è un compito estremamente impegnativo per un programmatore.
Di seguito sono riportate alcune terminologie fondamentali utilizzate ogni volta che sono coinvolte le strutture dati:
| Attributi | ID | Nome | Genere | Titolo di lavoro |
|---|---|---|---|---|
| Valori | 1234 | Stacey M. Hill | Femmina | Sviluppatore di software |
Entità con attributi simili formano un Insieme di entità . Ogni attributo di un insieme di entità ha un intervallo di valori, l'insieme di tutti i possibili valori che potrebbero essere assegnati all'attributo specifico.
Il termine 'informazione' viene talvolta utilizzato per dati con determinati attributi di dati significativi o elaborati.
Comprendere la necessità di strutture dati
Poiché le applicazioni stanno diventando sempre più complesse e la quantità di dati aumenta ogni giorno, il che può portare a problemi con la ricerca dei dati, la velocità di elaborazione, la gestione di richieste multiple e molto altro. Le strutture dati supportano diversi metodi per organizzare, gestire e archiviare i dati in modo efficiente. Con l'aiuto delle strutture dati, possiamo facilmente attraversare gli elementi dati. Le strutture dati forniscono efficienza, riusabilità e astrazione.
Perché dovremmo imparare le strutture dati?
- Le strutture dati e gli algoritmi sono due degli aspetti chiave dell'informatica.
- Le strutture dati ci consentono di organizzare e archiviare i dati, mentre gli algoritmi ci consentono di elaborarli in modo significativo.
- Imparare le strutture dati e gli algoritmi ci aiuterà a diventare programmatori migliori.
- Saremo in grado di scrivere codice più efficace e affidabile.
- Saremo anche in grado di risolvere i problemi in modo più rapido ed efficiente.
Comprendere gli obiettivi delle strutture dati
Le strutture dati soddisfano due obiettivi complementari:
Comprensione di alcune caratteristiche chiave delle strutture dati
Alcune delle caratteristiche significative delle strutture dati sono:
Classificazione delle strutture dati
Una struttura dati fornisce un insieme strutturato di variabili correlate tra loro in vari modi. Costituisce la base di uno strumento di programmazione che indica la relazione tra gli elementi dei dati e consente ai programmatori di elaborare i dati in modo efficiente.
Possiamo classificare le strutture dati in due categorie:
- Struttura dei dati primitivi
- Struttura dei dati non primitivi
La figura seguente mostra le diverse classificazioni delle strutture dati.
numero casuale gen java

Figura 2: Classificazioni delle strutture dati
Strutture dati primitive
- Queste strutture dati possono essere manipolate o gestite direttamente da istruzioni a livello macchina.
- Tipi di dati di base come Intero, Virgola mobile, Carattere , E Booleano rientrano nelle strutture dati primitive.
- Questi tipi di dati vengono anche chiamati Tipi di dati semplici , poiché contengono caratteri che non possono essere ulteriormente suddivisi
Strutture dati non primitive
- Queste strutture dati non possono essere manipolate o gestite direttamente da istruzioni a livello macchina.
- L'obiettivo di queste strutture dati è quello di formare un insieme di elementi dati omogeneo (stesso tipo di dati) o eterogeneo (diversi tipi di dati).
- In base alla struttura e alla disposizione dei dati, possiamo dividere queste strutture di dati in due sottocategorie:
- Strutture dati lineari
- Strutture dati non lineari
Strutture dati lineari
Una struttura dati che preserva una connessione lineare tra i suoi elementi dati è nota come struttura dati lineare. La disposizione dei dati viene eseguita in modo lineare, dove ciascun elemento è costituito dai successori e dai predecessori tranne il primo e l'ultimo elemento di dati. Tuttavia, ciò non è necessariamente vero nel caso della memoria, poiché la disposizione potrebbe non essere sequenziale.
In base all'allocazione della memoria, le strutture dati lineari sono ulteriormente classificate in due tipologie:
IL Vettore è il miglior esempio di struttura dati statica in quanto hanno una dimensione fissa e i suoi dati possono essere modificati successivamente.
Elenchi collegati, pile , E Code sono esempi comuni di strutture dati dinamiche
Tipi di strutture dati lineari
Di seguito è riportato l'elenco delle strutture di dati lineari che generalmente utilizziamo:
1. Array
UN Vettore è una struttura dati utilizzata per raccogliere più elementi di dati dello stesso tipo di dati in un'unica variabile. Invece di memorizzare più valori degli stessi tipi di dati in nomi di variabili separati, potremmo memorizzarli tutti insieme in un'unica variabile. Questa affermazione non implica che dovremo unire tutti i valori dello stesso tipo di dati in qualsiasi programma in un array di quel tipo di dati. Ma ci saranno spesso momenti in cui alcune variabili specifiche degli stessi tipi di dati sono tutte correlate tra loro in modo appropriato per un array.
Un Array è un elenco di elementi in cui ogni elemento ha una posizione univoca nell'elenco. Gli elementi dati dell'array condividono lo stesso nome di variabile; tuttavia, ciascuno porta un numero di indice diverso chiamato pedice. Possiamo accedere a qualsiasi elemento di dati dall'elenco con l'aiuto della sua posizione nell'elenco. Pertanto, la caratteristica chiave degli array da comprendere è che i dati vengono archiviati in posizioni di memoria contigue, consentendo agli utenti di spostarsi attraverso gli elementi di dati dell'array utilizzando i rispettivi indici.

Figura 3. Un array
Gli array possono essere classificati in diversi tipi:
Alcune applicazioni dell'array:
- Possiamo memorizzare un elenco di elementi di dati appartenenti allo stesso tipo di dati.
- L'array funge da memoria ausiliaria per altre strutture dati.
- L'array aiuta anche a memorizzare gli elementi di dati di un albero binario del conteggio fisso.
- L'array funge anche da archivio di matrici.
2. Elenchi collegati
UN Lista collegata è un altro esempio di struttura dati lineare utilizzata per archiviare dinamicamente una raccolta di elementi di dati. Gli elementi dati in questa struttura dati sono rappresentati dai Nodi, collegati tramite collegamenti o puntatori. Ogni nodo contiene due campi, il campo informazioni è costituito dai dati effettivi e il campo puntatore è costituito dall'indirizzo dei nodi successivi nell'elenco. Il puntatore dell'ultimo nodo della lista concatenata è costituito da un puntatore nullo, poiché non punta a nulla. A differenza degli array, l'utente può regolare dinamicamente la dimensione di un elenco collegato secondo i requisiti.

Figura 4. Una lista collegata
Disconnettersi dall'account Google su Android
Le liste collegate possono essere classificate in diverse tipologie:
Alcune applicazioni delle liste collegate:
- Le liste collegate ci aiutano a implementare stack, code, alberi binari e grafici di dimensioni predefinite.
- Possiamo anche implementare la funzione del sistema operativo per la gestione dinamica della memoria.
- Le liste collegate consentono anche l'implementazione polinomiale per operazioni matematiche.
- Possiamo utilizzare la Circular Linked List per implementare sistemi operativi o funzioni applicative per l'esecuzione Round Robin di attività.
- L'elenco collegato circolare è utile anche in una presentazione in cui un utente richiede di tornare alla prima diapositiva dopo la presentazione dell'ultima diapositiva.
- La Doubly Linked List viene utilizzata per implementare i pulsanti avanti e indietro in un browser per spostarsi avanti e indietro nelle pagine aperte di un sito Web.
3. Pile
UN Pila è una struttura di dati lineare che segue il LIFO (Last In, First Out) che consente operazioni di inserimento e cancellazione da un'estremità dello Stack, ovvero Top. Gli stack possono essere implementati con l'aiuto della memoria contigua, un Array, e della memoria non contigua, una Linked List. Esempi reali di pile sono pile di libri, un mazzo di carte, pile di soldi e molti altri.

Figura 5. Un esempio reale di Stack
La figura sopra rappresenta l'esempio reale di una pila in cui le operazioni vengono eseguite solo da un'estremità, come l'inserimento e la rimozione di nuovi libri dalla parte superiore della pila. Ciò implica che l'inserimento e la cancellazione nello Stack possono essere effettuati solo dall'alto dello Stack. Possiamo accedere solo ai vertici dello Stack in qualsiasi momento.
Le operazioni principali nello Stack sono le seguenti:

Figura 6. Una pila
Alcune applicazioni degli stack:
- Lo Stack viene utilizzato come struttura di archiviazione temporanea per operazioni ricorsive.
- Lo stack viene utilizzato anche come struttura di archiviazione ausiliaria per chiamate di funzioni, operazioni annidate e funzioni differite/posticipate.
- Possiamo gestire le chiamate di funzione utilizzando Stacks.
- Gli stack vengono utilizzati anche per valutare le espressioni aritmetiche in diversi linguaggi di programmazione.
- Gli stack sono utili anche per convertire le espressioni infisse in espressioni postfisse.
- Gli stack ci consentono di verificare la sintassi dell'espressione nell'ambiente di programmazione.
- Possiamo abbinare le parentesi usando Stacks.
- Gli stack possono essere utilizzati per invertire una stringa.
- Gli stack sono utili per risolvere problemi basati sul backtracking.
- Possiamo utilizzare Stacks per effettuare prima una ricerca approfondita nell'attraversamento di grafici e alberi.
- Gli stack vengono utilizzati anche nelle funzioni del sistema operativo.
- Gli stack vengono utilizzati anche nelle funzioni UNDO e REDO in un montaggio.
4. Code
UN Coda è una struttura dati lineare simile ad uno Stack con alcune limitazioni sull'inserimento e cancellazione degli elementi. L'inserimento di un elemento in una Queue avviene ad un'estremità, e la rimozione avviene ad un'altra estremità o all'estremità opposta. Pertanto, possiamo concludere che la struttura dei dati della coda segue il principio FIFO (First In, First Out) per manipolare gli elementi dei dati. L'implementazione delle code può essere eseguita utilizzando array, elenchi collegati o stack. Alcuni esempi reali di code sono una fila alla biglietteria, una scala mobile, un autolavaggio e molti altri.

Figura 7. Un esempio di coda nella vita reale
L'immagine sopra è un'illustrazione reale di una biglietteria del cinema che può aiutarci a capire la coda in cui il cliente che arriva per primo viene sempre servito per primo. Il cliente che arriva per ultimo verrà sicuramente servito per ultimo. Entrambe le estremità della coda sono aperte e possono eseguire operazioni diverse. Un altro esempio è una linea di ristorazione in cui il cliente viene inserito dalla parte posteriore mentre il cliente viene rimosso dalla parte anteriore dopo aver fornito il servizio richiesto.
Di seguito sono riportate le operazioni principali della coda:
scarica video da youtube vlc

Figura 8. Coda
Alcune applicazioni delle code:
- Le code vengono generalmente utilizzate nell'operazione di ricerca in ampiezza nei grafici.
- Le code vengono utilizzate anche nelle operazioni di pianificazione dei lavori dei sistemi operativi, come una coda del buffer della tastiera per memorizzare i tasti premuti dagli utenti e una coda del buffer di stampa per memorizzare i documenti stampati dalla stampante.
- Le code sono responsabili della pianificazione della CPU, della pianificazione dei lavori e della pianificazione del disco.
- Le code prioritarie vengono utilizzate nelle operazioni di download di file in un browser.
- Le code vengono utilizzate anche per trasferire dati tra i dispositivi periferici e la CPU.
- Le code sono anche responsabili della gestione degli interrupt generati dalle applicazioni utente per la CPU.
Strutture dati non lineari
Le strutture dati non lineari sono strutture dati in cui gli elementi dati non sono disposti in ordine sequenziale. In questo caso l'inserimento e la rimozione dei dati non sono possibili in modo lineare. Esiste una relazione gerarchica tra i singoli dati.
Tipi di strutture dati non lineari
Di seguito è riportato l'elenco delle strutture dati non lineari che generalmente utilizziamo:
1. Alberi
Un albero è una struttura di dati non lineare e una gerarchia contenente una raccolta di nodi in modo tale che ciascun nodo dell'albero memorizzi un valore e un elenco di riferimenti ad altri nodi (i 'figli').
La struttura dati ad albero è un metodo specializzato per organizzare e raccogliere dati nel computer per essere utilizzati in modo più efficace. Contiene un nodo centrale, nodi strutturali e sottonodi collegati tramite bordi. Possiamo anche dire che la struttura dati dell'albero è composta da radici, rami e foglie collegate.

Figura 9. Un albero
Gli alberi possono essere classificati in diverse tipologie:
Alcune applicazioni degli alberi:
- Gli alberi implementano strutture gerarchiche nei sistemi informatici come directory e file system.
- Gli alberi vengono utilizzati anche per implementare la struttura di navigazione di un sito web.
- Possiamo generare codice come il codice di Huffman utilizzando Trees.
- Gli alberi sono utili anche nel processo decisionale nelle applicazioni di gioco.
- Gli alberi sono responsabili dell'implementazione delle code di priorità per le funzioni di pianificazione del sistema operativo basate sulla priorità.
- Gli alberi sono anche responsabili dell'analisi di espressioni e istruzioni nei compilatori di diversi linguaggi di programmazione.
- Possiamo utilizzare gli alberi per archiviare le chiavi dei dati per l'indicizzazione per il sistema di gestione dei database (DBMS).
- Gli Spanning Trees ci consentono di instradare le decisioni nelle reti di computer e di comunicazione.
- Gli alberi vengono utilizzati anche nell'algoritmo di ricerca del percorso implementato nelle applicazioni di intelligenza artificiale (AI), robotica e videogiochi.
2. Grafici
Un grafico è un altro esempio di struttura dati non lineare comprendente un numero finito di nodi o vertici e gli spigoli che li collegano. I grafici vengono utilizzati per affrontare i problemi del mondo reale in cui denota l'area problematica come una rete come social network, reti di circuiti e reti telefoniche. Ad esempio, i nodi o vertici di un grafico possono rappresentare un singolo utente in una rete telefonica, mentre i bordi rappresentano il collegamento tra loro tramite telefono.
La struttura dei dati del grafico, G, è considerata una struttura matematica composta da un insieme di vertici, V e un insieme di bordi, E, come mostrato di seguito:
G = (V,E)

Figura 10. Un grafico
La figura sopra rappresenta un grafico avente sette vertici A, B, C, D, E, F, G e dieci bordi [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] e [E, G].
A seconda della posizione dei vertici e degli spigoli, i Grafici possono essere classificati in diverse tipologie:
Alcune applicazioni dei grafici:
- I grafici ci aiutano a rappresentare percorsi e reti nelle applicazioni di trasporto, viaggio e comunicazione.
- I grafici vengono utilizzati per visualizzare i percorsi nel GPS.
- I grafici ci aiutano anche a rappresentare le interconnessioni nei social network e in altre applicazioni basate sulla rete.
- I grafici vengono utilizzati nelle applicazioni di mappatura.
- I grafici sono responsabili della rappresentazione delle preferenze dell'utente nelle applicazioni di e-commerce.
- I grafici vengono utilizzati anche nelle reti di servizi pubblici per identificare i problemi posti agli enti locali o municipali.
- I grafici aiutano anche a gestire l'utilizzo e la disponibilità delle risorse in un'organizzazione.
- I grafici vengono utilizzati anche per creare mappe di collegamento dei documenti dei siti Web al fine di visualizzare la connettività tra le pagine tramite collegamenti ipertestuali.
- I grafici vengono utilizzati anche nei movimenti robotici e nelle reti neurali.
Operazioni di base delle strutture dati
Nella sezione seguente, discuteremo i diversi tipi di operazioni che possiamo eseguire per manipolare i dati in ogni struttura dati:
- In fase di compilazione
- Tempo di esecuzione
Ad esempio, il malloc() la funzione viene utilizzata nel linguaggio C per creare una struttura dati.
Comprendere il tipo di dati astratti
Secondo il Istituto nazionale di standard e tecnologia (NIST) , una struttura dati è una disposizione di informazioni, generalmente nella memoria, per una migliore efficienza dell'algoritmo. Le strutture dati includono elenchi collegati, pile, code, alberi e dizionari. Potrebbero anche essere un'entità teorica, come il nome e l'indirizzo di una persona.
Dalla definizione sopra menzionata, possiamo concludere che le operazioni nella struttura dei dati includono:
- Un alto livello di astrazioni come l'aggiunta o l'eliminazione di un elemento da un elenco.
- Ricerca e ordinamento di un elemento in un elenco.
- Accesso all'elemento con la priorità più alta in un elenco.
Ogni volta che la struttura dati esegue tali operazioni, è nota come an Tipo di dati astratti (ADT) .
Possiamo definirlo come un insieme di elementi di dati insieme alle operazioni sui dati. Il termine 'astratto' si riferisce al fatto che i dati e le operazioni fondamentali definite su di essi vengono studiati indipendentemente dalla loro implementazione. Comprende cosa possiamo fare con i dati, non come possiamo farlo.
Un'implementazione ADI contiene una struttura di archiviazione per archiviare gli elementi di dati e gli algoritmi per le operazioni fondamentali. Tutte le strutture dati, come un array, un elenco collegato, una coda, uno stack, ecc., sono esempi di ADT.
carattere Java in numero intero
Comprendere i vantaggi dell'utilizzo degli ADT
Nel mondo reale, i programmi si evolvono come conseguenza di nuovi vincoli o requisiti, quindi la modifica di un programma generalmente richiede un cambiamento in una o più strutture dati. Ad esempio, supponiamo di voler inserire un nuovo campo nel record di un dipendente per tenere traccia di maggiori dettagli su ciascun dipendente. In tal caso possiamo migliorare l'efficienza del programma sostituendo un Array con una struttura Linked. In una situazione del genere, riscrivere ogni procedura che utilizza la struttura modificata non è adatta. Quindi, un'alternativa migliore è separare una struttura dati dalle sue informazioni di implementazione. Questo è il principio alla base dell'utilizzo dei tipi di dati astratti (ADT).
Alcune applicazioni delle strutture dati
Di seguito sono riportate alcune applicazioni delle strutture dati:
- Le strutture dati aiutano nell'organizzazione dei dati nella memoria di un computer.
- Le strutture dati aiutano anche a rappresentare le informazioni nei database.
- Le strutture dati consentono l'implementazione di algoritmi per la ricerca tra i dati (ad esempio, motore di ricerca).
- Possiamo utilizzare le strutture dati per implementare gli algoritmi per manipolare i dati (ad esempio, elaboratori di testo).
- Possiamo anche implementare gli algoritmi per analizzare i dati utilizzando strutture di dati (ad esempio, data miner).
- Le strutture dati supportano algoritmi per generare i dati (ad esempio, un generatore di numeri casuali).
- Le strutture dati supportano anche algoritmi per comprimere e decomprimere i dati (ad esempio, un'utilità zip).
- Possiamo anche utilizzare strutture dati per implementare algoritmi per crittografare e decrittografare i dati (ad esempio, un sistema di sicurezza).
- Con l'aiuto delle strutture dati, possiamo creare software in grado di gestire file e directory (ad esempio, un file manager).
- Possiamo anche sviluppare software in grado di eseguire il rendering della grafica utilizzando strutture dati. (Ad esempio, un browser Web o un software di rendering 3D).
Oltre a queste, come accennato in precedenza, ci sono molte altre applicazioni di strutture dati che possono aiutarci a costruire qualsiasi software desiderato.