Un aspetto importante di Apprendimento automatico è la valutazione del modello. È necessario disporre di un meccanismo per valutare il modello. È qui che entrano in gioco questi parametri prestazionali che ci danno un'idea di quanto sia buono un modello. Se hai familiarità con alcune delle nozioni di base di Apprendimento automatico allora devi esserti imbattuto in alcune di queste metriche, come accuratezza, precisione, richiamo, auc-roc, ecc., che vengono generalmente utilizzate per compiti di classificazione. In questo articolo esploreremo in modo approfondito una di queste metriche, ovvero la curva AUC-ROC.
Tabella dei contenuti
- Cos'è la curva AUC-ROC?
- Termini chiave utilizzati nella curva AUC e ROC
- Relazione tra sensibilità, specificità, FPR e soglia.
- Come funziona l'AUC-ROC?
- Quando dovremmo utilizzare la metrica di valutazione AUC-ROC?
- Ipotesi sulle prestazioni del modello
- Comprensione della curva AUC-ROC
- Implementazione utilizzando due modelli diversi
- Come utilizzare ROC-AUC per un modello multiclasse?
- Domande frequenti sulla curva AUC ROC nell'apprendimento automatico
Cos'è la curva AUC-ROC?
La curva AUC-ROC, o curva delle caratteristiche operative dell'area sotto la ricevente, è una rappresentazione grafica delle prestazioni di un modello di classificazione binaria a varie soglie di classificazione. Viene comunemente utilizzato nell'apprendimento automatico per valutare la capacità di un modello di distinguere tra due classi, tipicamente la classe positiva (ad esempio, presenza di una malattia) e la classe negativa (ad esempio, assenza di una malattia).
Comprendiamo innanzitutto il significato dei due termini ROC E AUC .
- ROC : Caratteristiche operative del ricevitore
- AUC : Area sotto la curva
Curva delle caratteristiche operative del ricevitore (ROC).
ROC sta per Receiver Operating Characteristics e la curva ROC è la rappresentazione grafica dell'efficacia del modello di classificazione binaria. Traccia il tasso di veri positivi (TPR) rispetto al tasso di falsi positivi (FPR) a diverse soglie di classificazione.
Area sotto curva (AUC) Curva:
AUC sta per Area sotto la curva e la curva AUC rappresenta l'area sotto la curva ROC. Misura la prestazione complessiva del modello di classificazione binaria. Poiché sia TPR che FPR variano tra 0 e 1, l'area sarà sempre compresa tra 0 e 1 e un valore maggiore di AUC denota prestazioni migliori del modello. Il nostro obiettivo principale è massimizzare quest'area per avere il TPR più alto e l'FPR più basso alla soglia data. L'AUC misura la probabilità che il modello assegni a un'istanza positiva scelta casualmente una probabilità prevista più elevata rispetto a un'istanza negativa scelta casualmente.
Rappresenta il probabilità con cui il nostro modello può distinguere tra le due classi presenti nel nostro target.
Metrica di valutazione della classificazione ROC-AUC
Termini chiave utilizzati nella curva AUC e ROC
1. TPR e FPR
Questa è la definizione più comune che avresti incontrato quando avessi cercato su Google AUC-ROC. Fondamentalmente, la curva ROC è un grafico che mostra le prestazioni di un modello di classificazione a tutte le soglie possibili (la soglia è un valore particolare oltre il quale si dice che un punto appartiene a una classe particolare). La curva viene tracciata tra due parametri
- TPR – Tasso vero positivo
- FPR – Tasso di falsi positivi
Prima di comprendere, TPR e FPR diamo una rapida occhiata a matrice di confusione .
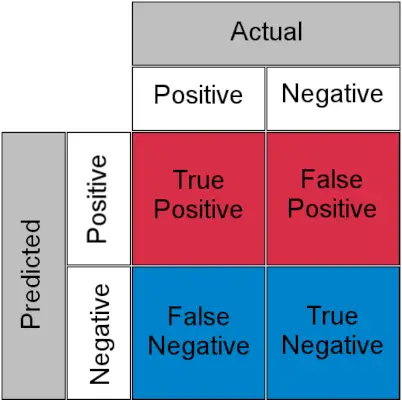
Matrice di confusione per un compito di classificazione
- Vero positivo : Positivo effettivo e previsto come positivo
- Vero negativo : Negativo effettivo e previsto come negativo
- Falso positivo (errore di tipo I) : Effettivo negativo ma previsto come positivo
- Falso negativo (errore di tipo II) : Positivo effettivo ma previsto come negativo
In termini semplici, puoi chiamare Falso Positivo a falso allarme e falso negativo a mancare . Vediamo ora cosa sono TPR e FPR.
2. Sensibilità/Tasso di veri positivi/Richiamo
Fondamentalmente, TPR/Richiamo/Sensibilità è il rapporto tra esempi positivi correttamente identificati. Rappresenta la capacità del modello di identificare correttamente le istanze positive e si calcola come segue:

Sensibilità/Richiamo/TPR misura la percentuale di casi positivi effettivi correttamente identificati dal modello come positivi.
3. Tasso di falsi positivi
FPR è il rapporto di esempi negativi classificati in modo errato.

4. Specificità
La specificità misura la percentuale di casi negativi effettivi correttamente identificati dal modello come negativi. Rappresenta la capacità del modello di identificare correttamente le istanze negative

E come detto prima, il ROC non è altro che il grafico tra TPR e FPR attraverso tutte le possibili soglie e l'AUC è l'intera area al di sotto di questa curva ROC.
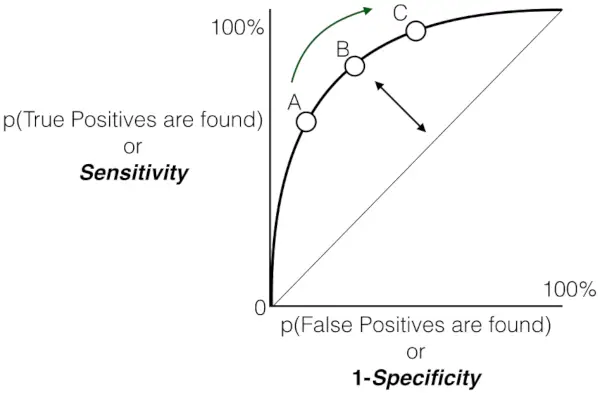
Grafico della sensibilità rispetto al tasso di falsi positivi
Relazione tra sensibilità, specificità, FPR e soglia .
Sensibilità e specificità:
- Relazione inversa: sensibilità e specificità hanno una relazione inversa. Quando uno aumenta, l’altro tende a diminuire. Ciò riflette il compromesso intrinseco tra tassi veri positivi e veri negativi.
- Sintonizzazione tramite soglia: Regolando il valore soglia, possiamo controllare l'equilibrio tra sensibilità e specificità. Soglie più basse portano a una sensibilità più elevata (più veri positivi) a scapito della specificità (più falsi positivi). Al contrario, l’aumento della soglia aumenta la specificità (meno falsi positivi) ma sacrifica la sensibilità (più falsi negativi).
Soglia e tasso di falsi positivi (FPR):
- Connessione FPR e specificità: Il tasso di falsi positivi (FPR) è semplicemente il complemento della specificità (FPR = 1 – specificità). Ciò indica la relazione diretta tra loro: una maggiore specificità si traduce in un FPR inferiore e viceversa.
- Modifiche FPR con TPR: Allo stesso modo, come hai osservato, anche il tasso di vero positivo (TPR) e il FPR sono collegati. Un aumento del TPR (più veri positivi) porta generalmente ad un aumento del FPR (più falsi positivi). Al contrario, un calo del TPR (meno veri positivi) si traduce in un calo del FPR (meno falsi positivi)
Come funziona l'AUC-ROC?
Abbiamo esaminato l'interpretazione geometrica, ma immagino che non sia ancora sufficiente per sviluppare l'intuizione dietro cosa significhi effettivamente 0,75 AUC, ora guardiamo AUC-ROC da un punto di vista probabilistico. Parliamo prima di cosa fa l'AUC e poi svilupperemo la nostra comprensione su questo
L'AUC misura quanto bene un modello è in grado di distinguere tra classi.
Un AUC di 0,75 significherebbe in realtà che supponiamo di prendere due punti dati appartenenti a classi separate, quindi c'è una probabilità del 75% che il modello sia in grado di separarli o ordinarli correttamente, ovvero il punto positivo ha una probabilità di previsione maggiore rispetto a quello negativo classe. (supponendo che una probabilità di previsione più elevata significhi che il punto apparterrebbe idealmente alla classe positiva). Ecco un piccolo esempio per rendere le cose più chiare.
Indice | Classe | Probabilità |
|---|---|---|
P1 | 1 array di strutture in linguaggio c | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Qui abbiamo 6 punti in cui P1, P2 e P5 appartengono alla classe 1 e P3, P4 e P6 appartengono alla classe 0 e stiamo corrispondendo alle probabilità previste nella colonna Probabilità, come abbiamo detto se prendiamo due punti appartenenti a separare classi, qual è la probabilità che il rango del modello le ordini correttamente.
Prenderemo tutte le coppie possibili in modo tale che un punto appartenga alla classe 1 e l'altro alla classe 0, avremo un totale di 9 coppie di questo tipo: di seguito sono tutte queste 9 coppie possibili.
Paio | è corretta |
|---|---|
(P1,P3) | SÌ |
(P1,P4) | SÌ |
(P1,P6) | SÌ |
(P2,P3) | SÌ |
(P2,P4) | SÌ |
(P2,P6) | SÌ |
(P3,P5) | NO |
(P4,P5) | NO |
(P5,P6) | SÌ |
Qui la colonna Corretto indica se la coppia menzionata è correttamente ordinata in base alla probabilità prevista, ovvero il punto di classe 1 ha una probabilità maggiore del punto di classe 0, in 7 di queste 9 possibili coppie la classe 1 è classificata più in alto della classe 0, oppure possiamo dire che c'è una probabilità del 77% che se si scelgono una coppia di punti appartenenti a classi separate il modello sia in grado di distinguerli correttamente. Ora, penso che potresti avere un po' di intuito dietro questo numero AUC, solo per chiarire ogni ulteriore dubbio convalidiamolo utilizzando Scikit impara l'implementazione AUC-ROC.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Produzione:
AUC for our sample data is 0.778>
Quando dovremmo utilizzare la metrica di valutazione AUC-ROC?
Esistono alcune aree in cui l'utilizzo di ROC-AUC potrebbe non essere l'ideale. Nei casi in cui il set di dati è fortemente sbilanciato, la curva ROC può fornire una valutazione eccessivamente ottimistica delle prestazioni del modello . Questa distorsione dell’ottimismo nasce perché il tasso di falsi positivi (FPR) della curva ROC può diventare molto piccolo quando il numero di negativi effettivi è elevato.
Osservando la formula FPR,

osserviamo ,
- La classe Negativa è maggioritaria, il denominatore di FPR è dominato dai Veri Negativi, per cui FPR diventa meno sensibile ai cambiamenti nelle previsioni relative alla classe minoritaria (classe positiva).
- Le curve ROC possono essere appropriate quando il costo dei falsi positivi e dei falsi negativi è bilanciato e il set di dati non è fortemente sbilanciato.
In questi casi, Curve di richiamo di precisione possono essere utilizzati che forniscono una metrica di valutazione alternativa più adatta a set di dati sbilanciati, concentrandosi sulle prestazioni del classificatore rispetto alla classe positiva (minoritaria).
Ipotesi sulle prestazioni del modello
- Un'AUC elevata (vicino a 1) indica un eccellente potere discriminante. Ciò significa che il modello è efficace nel distinguere tra le due classi e le sue previsioni sono affidabili.
- Una AUC bassa (prossima a 0) suggerisce una prestazione scarsa. In questo caso, il modello fatica a distinguere tra classi positive e negative e le sue previsioni potrebbero non essere affidabili.
- Un AUC intorno a 0,5 implica che il modello sta essenzialmente facendo ipotesi casuali. Non mostra alcuna capacità di separare le classi, indicando che il modello non sta apprendendo alcun modello significativo dai dati.
Comprensione della curva AUC-ROC
In una curva ROC, l'asse x rappresenta tipicamente il tasso di falsi positivi (FPR) e l'asse y rappresenta il tasso di veri positivi (TPR), noto anche come sensibilità o richiamo. Pertanto, un valore più alto dell'asse x (verso destra) sulla curva ROC indica un tasso di falsi positivi più alto, mentre un valore più alto dell'asse y (verso l'alto) indica un tasso di veri positivi più alto. La curva ROC è un grafico rappresentazione del compromesso tra tasso di veri positivi e tasso di falsi positivi a varie soglie. Mostra le prestazioni di un modello di classificazione a diverse soglie di classificazione. L'AUC (Area sotto la curva) è una misura sintetica dell'andamento della curva ROC. La scelta della soglia dipende dai requisiti specifici del problema che si sta cercando di risolvere e dal compromesso tra falsi positivi e falsi negativi che è accettabile nel tuo contesto.
- Se vuoi dare priorità alla riduzione dei falsi positivi (minimizzando le possibilità di etichettare qualcosa come positivo quando non lo è), potresti scegliere una soglia che si traduca in un tasso di falsi positivi inferiore.
- Se vuoi dare la priorità all'aumento dei veri positivi (acquisendo il maggior numero possibile di veri positivi), potresti scegliere una soglia che si traduca in un tasso di veri positivi più elevato.
Consideriamo un esempio per illustrare come vengono generate le curve ROC per diversi soglie e come una particolare soglia corrisponde a una matrice di confusione. Supponiamo di avere a problema di classificazione binaria con un modello che prevede se un'e-mail è spam (positivo) o non spam (negativo).
Consideriamo i dati ipotetici,
Etichette vere: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Probabilità previste: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Caso 1: Soglia = 0,5
Etichette vere | Probabilità previste | Etichette previste |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrice di confusione basata sulle previsioni di cui sopra
| Pronostico = 0 | Pronostico = 1 |
|---|---|---|
Effettivo = 0 | PT=4 | FN=1 |
Effettivo = 1 Lettore multimediale vlc scarica youtube | FP=0 | TN=5 |
Di conseguenza,
- Tasso di veri positivi (TPR) :
La proporzione dei positivi effettivi correttamente identificati dal classificatore è

- Tasso di falsi positivi (FPR) :
Proporzione di effettivi negativi erroneamente classificati come positivi



Quindi, alla soglia di 0,5:
- Tasso di veri positivi (sensibilità): 0,8
- Tasso di falsi positivi: 0
L’interpretazione è che il modello, a questa soglia, identifica correttamente l’80% dei positivi effettivi (TPR) ma classifica erroneamente lo 0% dei negativi effettivi come positivi (FPR).
Di conseguenza per soglie diverse otterremo ,
Caso 2: Soglia = 0,7
Etichette vere | Probabilità previste | Etichette previste |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Matrice di confusione basata sulle previsioni di cui sopra
| Pronostico = 0 | Pronostico = 1 |
|---|---|---|
Effettivo = 0 | TP=5 | FN=0 |
Effettivo = 1 | PQ=2 | TN=3 |
Di conseguenza,
- Tasso di veri positivi (TPR) :
La proporzione dei positivi effettivi correttamente identificati dal classificatore è

- Tasso di falsi positivi (FPR) :
Proporzione di effettivi negativi erroneamente classificati come positivi



Caso 3: Soglia = 0,4
Etichette vere | Probabilità previste | Etichette previste |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0.9 | 1 comando di esecuzione di Linux |
| 0 | 0.4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrice di confusione basata sulle previsioni di cui sopra
| Pronostico = 0 | Pronostico = 1 |
|---|---|---|
Effettivo = 0 | PT=4 | FN=1 |
Effettivo = 1 | FP=0 | TN=5 |
Di conseguenza,
- Tasso di veri positivi (TPR) :
La proporzione dei positivi effettivi correttamente identificati dal classificatore è
- Tasso di falsi positivi (FPR) :
Proporzione di effettivi negativi erroneamente classificati come positivi
Caso 4: Soglia = 0,2
Etichette vere | Probabilità previste | Etichette previste |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrice di confusione basata sulle previsioni di cui sopra
| Pronostico = 0 | Pronostico = 1 |
|---|---|---|
Effettivo = 0 | PT=2 | FN=3 |
Effettivo = 1 | FP=0 | TN=5 |
Di conseguenza,
- Tasso di veri positivi (TPR) :
La proporzione dei positivi effettivi correttamente identificati dal classificatore è

- Tasso di falsi positivi (FPR) :
Proporzione di effettivi negativi erroneamente classificati come positivi

Caso 5: Soglia = 0,85
Etichette vere | Probabilità previste | Etichette previste |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Matrice di confusione basata sulle previsioni di cui sopra
| Pronostico = 0 | Pronostico = 1 algoritmo di Kruskal |
|---|---|---|
Effettivo = 0 | TP=5 | FN=0 |
Effettivo = 1 | PQ=4 | TN=1 |
Di conseguenza,
- Tasso di veri positivi (TPR) :
La proporzione dei positivi effettivi correttamente identificati dal classificatore è
- Tasso di falsi positivi (FPR) :
Proporzione di effettivi negativi erroneamente classificati come positivi


Sulla base del risultato sopra, tracceremo la curva ROC
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Produzione:
Dal grafico è implicito che:
- La linea tratteggiata grigia rappresenta lo scenario peggiore, in cui le previsioni del modello, ovvero TPR e FPR, sono le stesse. Questa linea diagonale è considerata lo scenario peggiore, indicando un'eguale probabilità di falsi positivi e falsi negativi.
- Man mano che i punti si discostano dalla linea di ipotesi casuale verso l'angolo in alto a sinistra, le prestazioni del modello migliorano.
- L’Area Sotto la Curva (AUC) è una misura quantitativa della capacità discriminativa del modello. Un valore AUC più alto, più vicino a 1,0, indica prestazioni superiori. Il miglior valore AUC possibile è 1,0, corrispondente a un modello che raggiunge il 100% di sensibilità e il 100% di specificità.
Nel complesso, la curva ROC (Receiver Operating Characteristic) funge da rappresentazione grafica del compromesso tra il tasso di veri positivi (sensibilità) e il tasso di falsi positivi di un modello di classificazione binaria a varie soglie decisionali. Mentre la curva sale con grazia verso l’angolo in alto a sinistra, indica la lodevole capacità del modello di discriminare tra istanze positive e negative attraverso una gamma di soglie di confidenza. Questa traiettoria ascendente indica prestazioni migliorate, con una sensibilità più elevata ottenuta riducendo al minimo i falsi positivi. Le soglie annotate, indicate come A, B, C, D ed E, offrono preziose informazioni sul comportamento dinamico del modello a diversi livelli di confidenza.
Implementazione utilizzando due modelli diversi
Installazione delle librerie
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Per addestrare il Foresta casuale E Regressione logistica modelli e per presentare le loro curve ROC con punteggi AUC, l'algoritmo crea dati di classificazione binaria artificiale.
Generazione di dati e suddivisione dei dati
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Utilizzando un rapporto di suddivisione 80-20, l'algoritmo crea dati di classificazione binaria artificiale con 20 caratteristiche, li divide in set di addestramento e test e assegna un seme casuale per garantire la riproducibilità.
Formazione dei diversi modelli
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Utilizzando un seme casuale fisso per garantire la ripetibilità, il metodo inizializza e addestra un modello di regressione logistica sul set di addestramento. In modo simile, utilizza i dati di training e lo stesso seed casuale per inizializzare e addestrare un modello di foresta casuale con 100 alberi.
Predizioni
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Utilizzando i dati del test e un esperto Regressione logistica modello, il codice prevede la probabilità della classe positiva. In modo simile, utilizzando i dati del test, utilizza il modello Random Forest addestrato per produrre probabilità previste per la classe positiva.
Creazione di un frame di dati
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Utilizzando i dati del test, il codice crea un DataFrame chiamato test_df con colonne etichettate True, Logistic e RandomForest, aggiungendo etichette true e probabilità previste dai modelli Random Forest e Logistic Regression.
Traccia la curva ROC per i modelli
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Produzione:

Il codice genera un grafico con figure da 8 x 6 pollici. Calcola la curva AUC e ROC per ciascun modello (foresta casuale e regressione logistica), quindi traccia la curva ROC. IL Curva ROC per l'ipotesi casuale è rappresentato anche da una linea rossa tratteggiata e le etichette, un titolo e una legenda sono impostati per la visualizzazione.
Come utilizzare ROC-AUC per un modello multiclasse?
Per un ambiente multiclasse, possiamo semplicemente utilizzare la metodologia uno contro tutti e avrai una curva ROC per ogni classe. Supponiamo che tu abbia quattro classi A, B, C e D, quindi ci sarebbero curve ROC e valori AUC corrispondenti per tutte e quattro le classi, ovvero una volta A sarebbe una classe e B, C e D combinati sarebbero le altre classi , allo stesso modo, B è una classe e A, C e D combinati come altre classi, ecc.
I passaggi generali per l'utilizzo di AUC-ROC nel contesto di un modello di classificazione multiclasse sono:
Metodologia uno contro tutti:
- Per ogni classe del tuo problema multiclasse, trattala come la classe positiva mentre combini tutte le altre classi nella classe negativa.
- Addestra il classificatore binario per ogni classe rispetto al resto delle classi.
Calcola AUC-ROC per ciascuna classe:
- Qui tracciamo la curva ROC per la classe data rispetto al resto.
- Traccia le curve ROC per ciascuna classe sullo stesso grafico. Ciascuna curva rappresenta la prestazione di discriminazione del modello per una classe specifica.
- Esaminare i punteggi AUC per ciascuna classe. Un punteggio AUC più alto indica una migliore discriminazione per quella particolare classe.
Implementazione dell'AUC-ROC nella classificazione multiclasse
Importazione di librerie
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Il programma crea dati multiclasse artificiali, li divide in set di training e test e quindi utilizza il file Classificatore uno-vs-rest tecnica per addestrare classificatori sia per la foresta casuale che per la regressione logistica. Infine, traccia le curve ROC multiclasse dei due modelli per dimostrare quanto bene discriminano tra le varie classi.
Generazione di dati e suddivisione
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Tre classi e venti funzionalità costituiscono i dati multiclasse sintetici prodotti dal codice. Dopo la binarizzazione delle etichette, i dati vengono suddivisi in set di training e test in un rapporto 80-20.
Modelli di formazione
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Il programma addestra due modelli multiclasse: un modello Random Forest con 100 stimatori e un modello di Regressione Logistica con il Approccio uno contro resto . Con il set di dati di addestramento, vengono adattati entrambi i modelli.
Tracciare la curva AUC-ROC
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Produzione:

Le curve ROC e i punteggi AUC dei modelli Random Forest e Regressione logistica vengono calcolati dal codice per ciascuna classe. Vengono quindi tracciate le curve ROC multiclasse, che mostrano le prestazioni di discriminazione di ciascuna classe e presentano una linea che rappresenta l'ipotesi casuale. Il grafico risultante offre una valutazione grafica delle prestazioni di classificazione dei modelli.
Conclusione
Nell'apprendimento automatico, le prestazioni dei modelli di classificazione binaria vengono valutate utilizzando una metrica cruciale chiamata Area Under the Receiver Operating Characteristic (AUC-ROC). Attraverso varie soglie decisionali, mostra come sensibilità e specificità vengono compromesse. Una maggiore discriminazione tra istanze positive e negative è tipicamente esibita da un modello con un punteggio AUC più alto. Mentre 0,5 denota possibilità, 1 rappresenta prestazioni impeccabili. L’ottimizzazione e la selezione del modello sono aiutate dalle informazioni utili che la curva AUC-ROC offre sulla capacità di un modello di discriminare tra le classi. Quando si lavora con set di dati non bilanciati o applicazioni in cui falsi positivi e falsi negativi hanno costi diversi, è particolarmente utile come misura globale.
Domande frequenti sulla curva AUC ROC nell'apprendimento automatico
1. Cos'è la curva AUC-ROC?
Per varie soglie di classificazione, il compromesso tra tasso di veri positivi (sensibilità) e tasso di falsi positivi (specificità) è rappresentato graficamente dalla curva AUC-ROC.
2. Che aspetto ha una curva AUC-ROC perfetta?
Un'area pari a 1 su una curva AUC-ROC ideale significherebbe che il modello raggiunge sensibilità e specificità ottimali a tutte le soglie.
3. Cosa significa un valore AUC pari a 0,5?
Un’AUC pari a 0,5 indica che la prestazione del modello è paragonabile a quella del caso casuale. Suggerisce una mancanza di capacità discriminante.
4. È possibile utilizzare AUC-ROC per la classificazione multiclasse?
L'AUC-ROC viene spesso applicato a questioni che coinvolgono la classificazione binaria. Variazioni come l’AUC macromedia o micromedia possono essere prese in considerazione per la classificazione multiclasse.
5. In che modo la curva AUC-ROC è utile nella valutazione del modello?
La capacità di un modello di discriminare tra classi è riassunta in modo esaustivo dalla curva AUC-ROC. Quando si lavora con set di dati non bilanciati, è particolarmente utile.