Regressione logistica è un algoritmo di apprendimento automatico supervisionato usato per compiti di classificazione dove l'obiettivo è prevedere la probabilità che un'istanza appartenga o meno a una determinata classe. La regressione logistica è un algoritmo statistico che analizza la relazione tra due fattori di dati. L'articolo esplora i fondamenti della regressione logistica, i suoi tipi e le sue implementazioni.
Tabella dei contenuti
funzione freccia dattiloscritta
- Cos'è la regressione logistica?
- Funzione logistica – Funzione sigmoidea
- Tipi di regressione logistica
- Presupposti di regressione logistica
- Come funziona la regressione logistica?
- Implementazione del codice per la regressione logistica
- Compromesso precisione-richiamo nell'impostazione della soglia di regressione logistica
- Come valutare il modello di regressione logistica?
- Differenze tra regressione lineare e logistica
Cos'è la regressione logistica?
La regressione logistica viene utilizzata per il binario classificazione dove usiamo funzione sigmoidea , che prende input come variabili indipendenti e produce un valore di probabilità compreso tra 0 e 1.
Ad esempio, abbiamo due classi Classe 0 e Classe 1 se il valore della funzione logistica per un input è maggiore di 0,5 (valore soglia) allora appartiene alla Classe 1 altrimenti appartiene alla Classe 0. Si chiama regressione perché è l'estensione di regressione lineare ma viene utilizzato principalmente per problemi di classificazione.
Punti chiave:
- La regressione logistica prevede l'output di una variabile dipendente categoriale. Pertanto, il risultato deve essere un valore categorico o discreto.
- Può essere Sì o No, 0 o 1, vero o falso, ecc. Ma invece di fornire il valore esatto come 0 e 1, fornisce i valori probabilistici compresi tra 0 e 1.
- Nella regressione logistica, invece di adattare una linea di regressione, adattiamo una funzione logistica a forma di S, che prevede due valori massimi (0 o 1).
Funzione logistica – Funzione sigmoidea
- La funzione sigmoide è una funzione matematica utilizzata per mappare i valori previsti alle probabilità.
- Mappa qualsiasi valore reale in un altro valore entro un intervallo compreso tra 0 e 1. Il valore della regressione logistica deve essere compreso tra 0 e 1, che non può andare oltre questo limite, quindi forma una curva come la forma S.
- La curva a forma di S è chiamata funzione sigmoide o funzione logistica.
- Nella regressione logistica, utilizziamo il concetto di valore di soglia, che definisce la probabilità di 0 o 1. Ad esempio, i valori al di sopra del valore di soglia tendono a 1 e un valore al di sotto dei valori di soglia tende a 0.
Tipi di regressione logistica
In base alle categorie, la regressione logistica può essere classificata in tre tipologie:
- Binomiale: Nella regressione logistica binomiale, ci possono essere solo due tipi possibili di variabili dipendenti, come 0 o 1, Pass o Fail, ecc.
- Multinomiale: Nella regressione logistica multinomiale, possono esserci 3 o più possibili tipi non ordinati della variabile dipendente, ad esempio gatto, cane o pecora
- Ordinale: Nella regressione logistica ordinale possono essere presenti 3 o più tipi ordinati di variabili dipendenti, ad esempio Basso, Medio o Alto.
Presupposti di regressione logistica
Esploreremo i presupposti della regressione logistica poiché comprendere questi presupposti è importante per garantire che stiamo utilizzando un'applicazione appropriata del modello. Le ipotesi includono:
- Osservazioni indipendenti: ogni osservazione è indipendente dall'altra. il che significa che non esiste alcuna correlazione tra le variabili di input.
- Variabili dipendenti binarie: si presuppone che la variabile dipendente debba essere binaria o dicotomica, il che significa che può assumere solo due valori. Per più di due categorie vengono utilizzate le funzioni SoftMax.
- Relazione di linearità tra variabili indipendenti e probabilità logaritmiche: la relazione tra le variabili indipendenti e le probabilità logaritmiche della variabile dipendente dovrebbe essere lineare.
- Nessun valore anomalo: non devono essere presenti valori anomali nel set di dati.
- Grande dimensione del campione: la dimensione del campione è sufficientemente grande
Terminologie coinvolte nella regressione logistica
Ecco alcuni termini comuni coinvolti nella regressione logistica:
- Variabili indipendenti: Le caratteristiche di input o i fattori predittivi applicati alle previsioni della variabile dipendente.
- Variabile dipendente: La variabile target in un modello di regressione logistica, che stiamo cercando di prevedere.
- Funzione logistica: La formula utilizzata per rappresentare la relazione tra le variabili indipendenti e dipendenti. La funzione logistica trasforma le variabili di input in un valore di probabilità compreso tra 0 e 1, che rappresenta la probabilità che la variabile dipendente sia 1 o 0.
- Probabilità: È il rapporto tra qualcosa che accade e qualcosa che non accade. è diverso dalla probabilità poiché la probabilità è il rapporto tra qualcosa che accade e tutto ciò che potrebbe accadere.
- Quote di registro: Il log-odds, noto anche come funzione logit, è il logaritmo naturale delle probabilità. Nella regressione logistica, le probabilità logaritmiche della variabile dipendente sono modellate come una combinazione lineare delle variabili indipendenti e dell'intercetta.
- Coefficiente: I parametri stimati del modello di regressione logistica mostrano come le variabili indipendenti e dipendenti si relazionano tra loro.
- Intercettare: Un termine costante nel modello di regressione logistica, che rappresenta le probabilità logaritmiche quando tutte le variabili indipendenti sono uguali a zero.
- Stima di massima verosimiglianza : Il metodo utilizzato per stimare i coefficienti del modello di regressione logistica, che massimizza la probabilità di osservare i dati dato il modello.
Come funziona la regressione logistica?
Il modello di regressione logistica trasforma il regressione lineare funzione output di valore continuo in output di valore categoriale utilizzando una funzione sigmoide, che mappa qualsiasi insieme di variabili indipendenti a valore reale immesso in un valore compreso tra 0 e 1. Questa funzione è nota come funzione logistica.
Sia le caratteristiche di input indipendenti:
e la variabile dipendente è Y che ha solo valore binario, ovvero 0 o 1.
quindi, applica la funzione multilineare alle variabili di input X.
Qui
tutto ciò di cui abbiamo discusso sopra è il regressione lineare .
Funzione sigmoidea
Ora usiamo il funzione sigmoidea dove l'input sarà z e troviamo la probabilità compresa tra 0 e 1, ovvero y previsto.
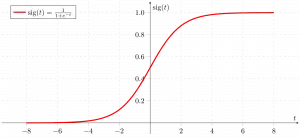
Funzione sigmoidea
Come mostrato sopra, la funzione figura sigmoide converte i dati della variabile continua in probabilità cioè tra 0 e 1.
sigma(z) tende verso 1 asz ightarrowinfty sigma(z) tende verso 0 comez ightarrow-infty sigma(z) è sempre compreso tra 0 e 1
dove la probabilità di essere una classe può essere misurata come:
Equazione di regressione logistica
La disparità è il rapporto tra qualcosa che accade e qualcosa che non accade. è diverso dalla probabilità poiché la probabilità è il rapporto tra qualcosa che accade e tutto ciò che potrebbe accadere. così strano sarà:
Applicazione del log naturale su dispari. quindi il log dispari sarà:
quindi l'equazione finale della regressione logistica sarà:
Funzione di verosimiglianza per la regressione logistica
Le probabilità previste saranno:
elenco Java nell'array
- per y=1 Le probabilità previste saranno: p(X;b,w) = p(x)
- per y = 0 Le probabilità previste saranno: 1-p(X;b,w) = 1-p(x)
Prendendo tronchi naturali su entrambi i lati
Gradiente della funzione di verosimiglianza
Per trovare le stime di massima verosimiglianza, differenziamo w.r.t w,
Implementazione del codice per la regressione logistica
Regressione logistica binomiale:
La variabile target può avere solo 2 tipi possibili: 0 o 1 che possono rappresentare vittoria/perdita, passaggio/fallimento, morto/vivo, ecc., in questo caso vengono utilizzate le funzioni sigmoidali, già discusse sopra.
Importazione delle librerie necessarie in base ai requisiti del modello. Questo codice Python mostra come utilizzare il set di dati sul cancro al seno per implementare un modello di regressione logistica per la classificazione.
Python3 # import the necessary libraries from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # load the breast cancer dataset X, y = load_breast_cancer(return_X_y=True) # split the train and test dataset X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=23) # LogisticRegression clf = LogisticRegression(random_state=0) clf.fit(X_train, y_train) # Prediction y_pred = clf.predict(X_test) acc = accuracy_score(y_test, y_pred) print('Logistic Regression model accuracy (in %):', acc*100)> Produzione :
Precisione del modello di regressione logistica (in %): 95,6140350877193
Regressione logistica multinomiale:
La variabile target può avere 3 o più tipi possibili che non sono ordinati (ovvero i tipi non hanno significato quantitativo) come la malattia A rispetto alla malattia B rispetto alla malattia C.
In questo caso, la funzione softmax viene utilizzata al posto della funzione sigmoidea. Funzione Softmax per le classi K sarà:
Qui, K rappresenta il numero di elementi nel vettore z e i, j esegue un'iterazione su tutti gli elementi nel vettore.
Allora la probabilità per la classe c sarà:
Nella regressione logistica multinomiale, la variabile di output può avere più di due possibili uscite discrete . Consideriamo il set di dati Digit.
Python3 from sklearn.model_selection import train_test_split from sklearn import datasets, linear_model, metrics # load the digit dataset digits = datasets.load_digits() # defining feature matrix(X) and response vector(y) X = digits.data y = digits.target # splitting X and y into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1) # create logistic regression object reg = linear_model.LogisticRegression() # train the model using the training sets reg.fit(X_train, y_train) # making predictions on the testing set y_pred = reg.predict(X_test) # comparing actual response values (y_test) # with predicted response values (y_pred) print('Logistic Regression model accuracy(in %):', metrics.accuracy_score(y_test, y_pred)*100)> Produzione:
Precisione del modello di regressione logistica (in %): 96,52294853963839
Come valutare il modello di regressione logistica?
Possiamo valutare il modello di regressione logistica utilizzando le seguenti metriche:
- Precisione: Precisione fornisce la proporzione di istanze classificate correttamente.
Accuracy = frac{True , Positives + True , Negatives}{Total}
- Precisione: Precisione si concentra sull’accuratezza delle previsioni positive.
Precision = frac{True , Positives }{True, Positives + False , Positives}
- Richiamo (sensibilità o tasso di vero positivo): Richiamare misura la proporzione di casi positivi correttamente previsti tra tutti i casi positivi effettivi.
Recall = frac{ True , Positives}{True, Positives + False , Negatives}
- Punteggio F1: Punteggio F1 è la media armonica di precisione e richiamo.
F1 , Score = 2 * frac{Precision * Recall}{Precision + Recall}
- Area sotto la curva caratteristica operativa del ricevitore (AUC-ROC): La curva ROC traccia il tasso di veri positivi rispetto al tasso di falsi positivi a varie soglie. AUC-ROC misura l’area sotto questa curva, fornendo una misura aggregata delle prestazioni di un modello attraverso diverse soglie di classificazione.
- Area sotto la curva di richiamo di precisione (AUC-PR): Simile a AUC-ROC, AUC-PR misura l'area sotto la curva di richiamo della precisione, fornendo un riepilogo delle prestazioni di un modello attraverso diversi compromessi in termini di richiamo della precisione.
Compromesso precisione-richiamo nell'impostazione della soglia di regressione logistica
La regressione logistica diventa una tecnica di classificazione solo quando viene introdotta una soglia decisionale. L'impostazione del valore di soglia è un aspetto molto importante della regressione logistica e dipende dal problema di classificazione stesso.
La decisione per il valore del valore di soglia è influenzata principalmente dai valori di precisione e richiamo. Idealmente, vogliamo che sia la precisione che il ricordo siano pari a 1, ma questo è raramente il caso.
Nel caso di a Compromesso precisione-richiamo , utilizziamo i seguenti argomenti per decidere sulla soglia:
mappa iterativa Java
- Bassa precisione/Richiamo elevato: Nelle applicazioni in cui vogliamo ridurre il numero di falsi negativi senza necessariamente ridurre il numero di falsi positivi, scegliamo un valore decisionale che abbia un valore basso di Precisione o un valore alto di Recall. Ad esempio, in un'applicazione per la diagnosi del cancro, non vogliamo che nessun paziente affetto venga classificato come non affetto senza prestare molta attenzione se al paziente viene erroneamente diagnosticato un cancro. Questo perché l'assenza di cancro può essere rilevata da altre malattie mediche, ma la presenza della malattia non può essere rilevata in un candidato già rifiutato.
- Alta precisione/Richiamo basso: Nelle applicazioni in cui vogliamo ridurre il numero di falsi positivi senza necessariamente ridurre il numero di falsi negativi, scegliamo un valore decisionale che abbia un valore alto di Precisione o un valore basso di Recall. Ad esempio, se classifichiamo i clienti se reagiranno positivamente o negativamente a un annuncio pubblicitario personalizzato, vogliamo essere assolutamente sicuri che il cliente reagirà positivamente all'annuncio perché altrimenti una reazione negativa può causare una perdita di vendite potenziali da parte del cliente. cliente.
Differenze tra regressione lineare e logistica
La differenza tra regressione lineare e regressione logistica è che l'output della regressione lineare è il valore continuo che può essere qualsiasi cosa, mentre la regressione logistica prevede la probabilità che un'istanza appartenga o meno a una determinata classe.
Regressione lineare | Regressione logistica |
|---|---|
La regressione lineare viene utilizzata per prevedere la variabile dipendente continua utilizzando un dato insieme di variabili indipendenti. | La regressione logistica viene utilizzata per prevedere la variabile dipendente categoriale utilizzando un dato insieme di variabili indipendenti. |
La regressione lineare viene utilizzata per risolvere il problema di regressione. | Viene utilizzato per risolvere problemi di classificazione. |
In questo prevediamo il valore delle variabili continue | In questo prevediamo i valori delle variabili categoriali |
In questa troviamo la linea più adatta. | In questo troviamo la curva a S. |
Il metodo di stima dei minimi quadrati viene utilizzato per la stima dell'accuratezza. | Il metodo di stima della massima verosimiglianza viene utilizzato per la stima dell'accuratezza. |
L’output deve essere un valore continuo, come prezzo, età, ecc. | L'output deve essere un valore categorico come 0 o 1, Sì o no e così via. |
Richiedeva una relazione lineare tra variabili dipendenti e indipendenti. | Non è richiesta una relazione lineare. Java e altalena |
Potrebbe esserci collinearità tra le variabili indipendenti. | Non dovrebbe esserci collinearità tra variabili indipendenti. |
Regressione logistica – Domande frequenti (FAQ)
Cos'è la regressione logistica nell'apprendimento automatico?
La regressione logistica è un metodo statistico per lo sviluppo di modelli di machine learning con variabili dipendenti binarie, ovvero binarie. La regressione logistica è una tecnica statistica utilizzata per descrivere i dati e la relazione tra una variabile dipendente e una o più variabili indipendenti.
Quali sono i tre tipi di regressione logistica?
La regressione logistica è classificata in tre tipi: binaria, multinomiale e ordinale. Differiscono nell'esecuzione e nella teoria. La regressione binaria riguarda due possibili risultati: sì o no. La regressione logistica multinomiale viene utilizzata quando sono presenti tre o più valori.
Perché la regressione logistica viene utilizzata per il problema di classificazione?
La regressione logistica è più facile da implementare, interpretare e addestrare. Classifica i record sconosciuti molto rapidamente. Quando il set di dati è separabile linearmente, funziona bene. I coefficienti del modello possono essere interpretati come indicatori dell'importanza delle caratteristiche.
Cosa distingue la regressione logistica dalla regressione lineare?
Mentre la regressione lineare viene utilizzata per prevedere risultati continui, la regressione logistica viene utilizzata per prevedere la probabilità che un'osservazione rientri in una categoria specifica. La regressione logistica utilizza una funzione logistica a forma di S per mappare i valori previsti tra 0 e 1.
Che ruolo gioca la funzione logistica nella regressione logistica?
La regressione logistica si basa sulla funzione logistica per convertire l'output in un punteggio di probabilità. Questo punteggio rappresenta la probabilità che un'osservazione appartenga ad una particolare classe. La curva a forma di S aiuta a definire soglie e classificare i dati in risultati binari.