Il comando cut in Linux è un comando per ritagliare le sezioni da ogni riga di file e scrivere il risultato sullo standard output. Può essere utilizzato per tagliare parti di una riga in base alla posizione del byte, al carattere e al campo. Il comando taglia taglia una linea ed estrae il testo. E' necessario specificare un'opzione con un comando altrimenti restituisce un errore. Se viene fornito più di un nome file, i dati di ciascun file non sono preceduti dal relativo nome file.
Tabella dei contenuti
- Sintassi del comando cut
- Opzioni disponibili nel comando di taglio
- Esempi pratici di comando di taglio
- Estrai byte specifici (-b) utilizzando il comando cut
- Taglia per carattere (-c) Utilizzando il comando taglia
- Taglia per campo (-f) Utilizzo del comando di taglio
- Complementa l'output (–complement) utilizzando il comando cut
- Delimitatore di output (–output-delimiter) Utilizzo del comando cut
- Visualizza versione (–version) utilizzando il comando cut
- Come utilizzare tail con pipe(|) nel comando cut
- Domande frequenti sul comando cut in Linux – Domande frequenti
Sintassi del comando cut
La sintassi di base dicut>il comando è:
cut OPTION... [FILE]...>
Dove
`OPTION`> specifica il comportamento desiderato
` FILE> `>rappresenta il file di input.
Nota : SeFILE>non è specificato, ` cut`> legge dall'input standard (stdin).
Opzioni disponibili nel comando di taglio
Di seguito è riportato un elenco delle opzioni più comunemente utilizzate con l'estensione ` cut`> comando:
| Opzione | Descrizione |
|---|---|
| -b, –byte=ELENCO | Seleziona solo i byte specificati in |
| -c, –caratteri=ELENCO | Seleziona solo i caratteri specificati in |
| -d, –delimitatore=DIVIDE | Usi |
| -f, –campi=LIS | Seleziona solo i campi specificati in |
| -N | Non dividere i caratteri multibyte (nessun effetto a meno che |
| -complemento | Invertire la selezione di campi/caratteri. Stampa i campi/caratteri non selezionati. |
Esempi pratici di comando di taglio
Consideriamo due file con nome stato.txt E capitale.txt contiene rispettivamente 5 nomi degli stati e delle capitali indiani.
$ cat state.txt Andhra Pradesh Arunachal Pradesh Assam Bihar Chhattisgarh>
Senza alcuna opzione specificata viene visualizzato un errore.
$ cut state.txt cut: you must specify a list of bytes, characters, or fields Try 'cut --help' for more information.>
Estrai byte specifici (-b>) Utilizzando il comando taglia
-b(byte): Per estrarre i byte specifici, è necessario seguire l'opzione -b con l'elenco dei numeri di byte separati da virgola. L'intervallo di byte può essere specificato anche utilizzando il trattino (-). È necessario specificare l'elenco dei numeri di byte altrimenti viene restituito un errore.
Tabulazioni e backspace vengono trattati come un carattere di 1 byte.
Elenco senza intervalli :
cut -b 1,2,3 state.txt>
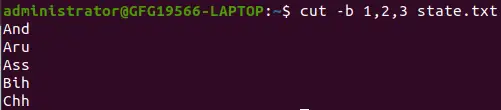
elenco senza intervallo
Elenco con intervalli:
cut -b 1-3,5-7 state.txt>
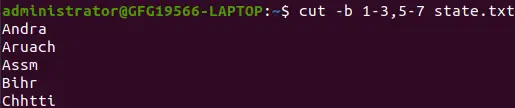
elenco con intervallo
Utilizza un formato speciale per selezionare i byte dall'inizio fino alla fine della riga:
Forma speciale: selezione dei byte dall'inizio alla fine della riga
In questo, 1- indica dal primo byte al byte finale di una riga
cut -b 1- state.txt>
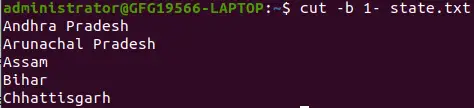
forma speciale con l'opzione -b
In questo, -3 indica dal 1° al 3° byte di una riga
cut -b -3 state.txt>
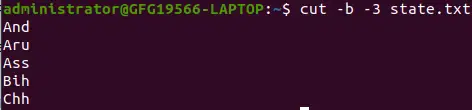
forma speciale -b opzione
Taglia per carattere (-c>) Utilizzando il comando taglia
-c (colonna): Per tagliare per carattere utilizzare l'opzione -c. Questo seleziona i caratteri dati all'opzione -c. Può trattarsi di un elenco di numeri separati da virgole o di un intervallo di numeri separati da un trattino (-).
Tabulazioni e backspace vengono trattati come un personaggio. È necessario specificare l'elenco dei numeri dei caratteri altrimenti verrà visualizzato un errore con questa opzione.
Sintassi:
cut -c [(k)-(n)/(k),(n)/(n)] filename>
Qui, K denota la posizione iniziale del carattere e N denota la posizione finale del carattere in ogni riga, se K E N sono separati da - altrimenti rappresentano solo la posizione del carattere in ciascuna riga del file presa come input.
Estrai caratteri specifici:
cut -c 2,5,7 state.txt>
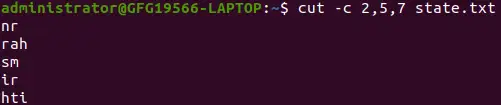
Estrai caratteri specifici
Il comando di taglio sopra stampa il secondo, il quinto e il settimo carattere di ciascuna riga del file.
Estrai i primi sette caratteri:
cut -c 1-7 state.txt>
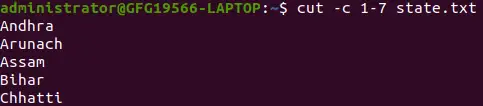
Estrai i primi sette caratteri
Il comando cut sopra stampa i primi sette caratteri di ogni riga del file. Taglia utilizza un modulo speciale per selezionare i caratteri dall'inizio alla fine della riga:
Forma speciale: selezione dei caratteri dall'inizio alla fine della riga
cut -c 1- state.txt>
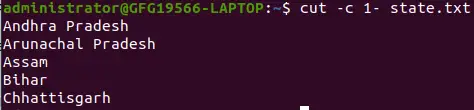
selezionando i caratteri dall'inizio alla fine della riga utilizzando l'opzione -c
Il comando precedente stampa partendo dal primo carattere fino alla fine. Qui nel comando viene specificata solo la posizione iniziale e la posizione finale viene omessa.
cut -c -5 state.txt>
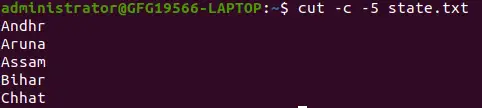
selezionando i caratteri dall'inizio alla fine della riga utilizzando l'opzione -c
Il comando precedente stampa la posizione iniziale al quinto carattere. Qui la posizione iniziale viene omessa e viene specificata la posizione finale.
Taglia per campo (-f>) Utilizzando il comando taglia
-f (campo): -c l'opzione è utile per le linee a lunghezza fissa. La maggior parte dei file Unix non ha linee a lunghezza fissa. Per estrarre le informazioni utili è necessario tagliare per campi anziché per colonne. L'elenco dei campi numero specificato deve essere separato da virgola. Gli intervalli non sono descritti con l'opzione -f . taglio usi scheda come delimitatore di campo predefinito ma può funzionare anche con altri delimitatori utilizzando -D opzione.
Nota: Lo spazio non è considerato delimitatore in UNIX.
Sintassi:
cut -d 'delimiter' -f (field number) file.txt>
Estrai il primo campo:
Come nel fascicolo stato.txt i campi sono separati da uno spazio se l'opzione -d non viene utilizzata, viene stampata l'intera riga:
cut -f 1 state.txt>
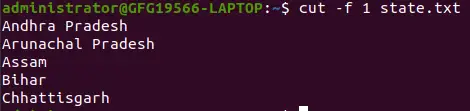
Estrai il primo campo utilizzando l'opzione -f
Se ` -d` viene utilizzata l'opzione quindi viene considerato lo spazio come separatore o delimitatore di campo:
cut -d ' ' -f 1 state.txt>
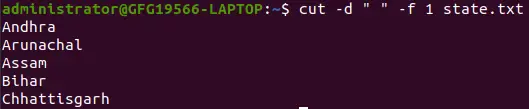
spazio come separatore o delimitatore di campo
Estrai i campi da 1 a 4:
Il comando stampa il campo dalla prima alla quarta di ogni riga del file.
cut -d ' ' -f 1-4 state.txt>

Il comando stampa il campo dal primo al quarto
Uscita complemento (--complement>) Utilizzando il comando taglia
-complemento: Come suggerisce il nome, completa l'output. Questa opzione può essere utilizzata in combinazione con altre opzioni o con -F o con -C .
cut --complement -d ' ' -f 1 state.txt>

-complemento
cut --complement -c 5 state.txt>

-complemento
Delimitatore di uscita (--output-delimiter>) Utilizzando il comando taglia
–delimitatore di output: Per impostazione predefinita, il delimitatore di output è uguale al delimitatore di input con cui specifichiamo nel taglio -D opzione. Per modificare il delimitatore di output utilizzare l'opzione –delimitatore-output=delimitatore .
cut -d ' ' -f 1,2 state.txt --output-delimiter='%'>

Qui il comando cut modifica il delimitatore (%) nell'output standard tra i campi specificati utilizzando l'opzione -f.
Versione di visualizzazione (--version>) Utilizzando il comando taglia
-versione: Questa opzione viene utilizzata per visualizzare la versione di cut attualmente in esecuzione sul tuo sistema.
cut --version>

visualizza la versione del comando di taglio
Come utilizzare tail con pipe(|) nel comando cut
Il comando cut può essere convogliato con molti altri comandi di UNIX. Nell'esempio seguente l'output di gatto il comando viene fornito come input al file taglio comandare con -F opzione per ordinare i nomi degli stati provenienti dal file state.txt nell'ordine inverso.
cat state.txt | cut -d ' ' -f 1 | sort -r>

utilizzando tail with pipe (|) nel comando cut
Può anche essere collegato con uno o più filtri per un'ulteriore elaborazione. Come nell'esempio seguente, stiamo utilizzando i comandi cat, head e cut e il cui output è memorizzato nel nome file list.txt utilizzando direttiva(>).
cat state.txt | head -n 3 | cut -d ' ' -f 1>list.txt>
cat list.txt>

Shilpa Shetty
reindirizzare l'output in un file diverso
Domande frequenti sul comando cut in Linux – Domande frequenti
Come utilizzo il cut> comando per estrarre colonne specifiche da un file?
Esempio: per estrarre la prima e la terza colonna da un file CSV denominato ` data.csv`> .
cut -d',' -f1,3 data.csv>
Posso usare cut> estrarre una serie di caratteri da ogni riga?
Si, puoi. Per estrarre i caratteri da 5 a 10 da ciascuna riga di un file denominatotext.txt>.
cut -c5-10 text.txt>
Come posso modificare il delimitatore utilizzato dal file cut> comando?
Utilizzare il ` -d`> opzione seguita dal carattere delimitatore. Ad esempio, per utilizzare i due punti (:>) come delimitatore.
cut -d':' -f1,3 data.txt>
È possibile utilizzare cut> estrarre i campi in base alla posizione del carattere?
Sì, puoi specificare le posizioni dei caratteri con il comando ` -c`> opzione. Ad esempio, per estrarre i caratteri da 1 a 5 e da 10 a 15 da ciascuna riga.
cut -c1-5,10-15 data.txt>
Come si usa cut> estrarre i campi in base a un delimitatore specifico e memorizzarli in un nuovo file?
Per estrarre i campi separati da virgole e memorizzarli in un nuovo file denominato ` output.tx> t`>
cut -d',' -f1,3 data.csv>output.txt>
Conclusione
In questo articolo abbiamo discusso di ` cut`> comando in Linux che è uno strumento versatile per estrarre sezioni specifiche da file in base alla posizione del byte, al carattere o al campo. Suddivide righe di testo e restituisce i dati estratti. Mancata specifica di un'opzione con il filecut>il comando genera un errore. È possibile elaborare più file, ma l'output non include i nomi dei file. Opzioni come ` -b`> , ` -c`> e ' -f`> consentire l'estrazione rispettivamente per byte, carattere e campo. IL--complement>l'opzione inverte la selezione, stampando ciò che non è selezionato, e--output-delimiter>modifica il delimitatore di output. Il comando include anche opzioni per la visualizzazione della versione e può essere utilizzato in combinazione con altri comandi tramite pipe per un'ulteriore elaborazione.
?list=PLqM7alHXFySFc4KtwEZTANgmyJm3NqS_L