Multiprocessori sono classificati in tre tipi di modelli di memoria condivisa: UMA (Accesso uniforme alla memoria), NUMA (Accesso alla memoria non uniforme) e COMA (Accesso alla memoria solo cache) . I modelli differiscono in base alla modalità di allocazione della memoria e delle risorse hardware. La memoria fisica è condivisa uniformemente tra i processori nel modello UMA, che ha anche la stessa latenza per ogni parola di memoria. Al contrario, NUMA fornisce un tempo di accesso variabile affinché la CPU possa accedere alla memoria.
In questo articolo imparerai la differenza tra il UNO E IN . Ma prima di discutere le differenze, devi conoscere UMA e NUMA.
leggi di equivalenza
Cos'è l'UMA?
UNO è un'abbreviazione di 'Accesso uniforme alla memoria' . È un'architettura di memoria condivisa multiprocessore. In questo modello tutti i processori del sistema multiprocessore utilizzano e accedono alla stessa memoria con l'aiuto della rete di interconnessione.
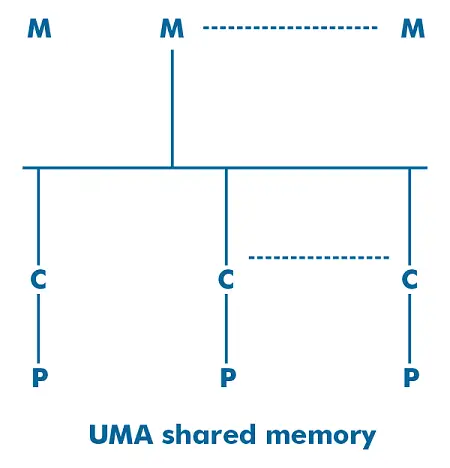
La latenza e la velocità di accesso di ciascuno processore è la stessa. Può avvalersi di a commutatore a traversa, un commutatore di bus singolo o un commutatore di bus multipli . Viene anche indicato come SMP (multiprocessore simmetrico) sistema perché offre un accesso equilibrato alla memoria condivisa. È adatto per applicazioni time-sharing e per scopi generali.
Cos'è la NUMA?
IN è un'abbreviazione di 'Accesso alla memoria non uniforme' . È anche un modello multiprocessore con memoria dedicata collegata a ciascuna CPU. Ma questi piccoli componenti della memoria si uniscono per formare un unico spazio di indirizzi. Il tempo di accesso alla memoria è determinato dalla distanza tra la CPU e la memoria, risultando in tempi di accesso alla memoria variabili. Fornisce l'accesso a qualsiasi luogo di memoria utilizzando l'indirizzo fisico.

IL Architettura NUMA è progettato per massimizzare la larghezza di banda della memoria disponibile utilizzando diversi controller di memoria. Integra molti nuclei della macchina in 'nodi' , con ciascun core dotato del proprio controller di memoria. In un IN sistema, il core riceve la memoria gestita dal controller di memoria tramite il suo nodo per accedere alla memoria locale. Il core trasmette la richiesta di memoria attraverso i collegamenti di interconnessione per accedere alla memoria distante, che l'altro controller di memoria elabora. L'architettura NUMA utilizza reti di bus gerarchiche e ad albero per connettere i blocchi di memoria e le CPU. Alcuni esempi dell'architettura NUMA sono BBN, SGI Origin 3000, TC-2000 e Cray .
Differenze chiave tra UMA e NUMA

Ci sono varie differenze chiave tra UNO E IN . Alcune delle differenze chiave tra UMA e NUMA sono le seguenti:
- L'UMA (Uniform Memory Access) contiene un singolo controller di memoria. Al contrario, il NUMA (Non-Uniform Memory Access) può utilizzare diversi controller di memoria per accedere alla memoria.
- Il tempo di accesso alla memoria per ciascuna CPU in UMA è lo stesso. Al contrario, il tempo di accesso alla memoria in NUMA varia con la distanza della memoria dalla CPU.
- UMA viene utilizzato in una varietà di app generiche e di condivisione del tempo. D'altro canto, la NUMA viene utilizzata nelle app in tempo reale e con criticità temporale.
- L'architettura UMA utilizza bus singoli, multipli e trasversali. D'altro canto, la NUMA impiega bus e connessioni di rete gerarchici e strutturati ad albero.
- In termini di larghezza di banda, l'architettura UMA ha una larghezza di banda limitata. D'altra parte, la NUMA ha una larghezza di banda maggiore rispetto all'UMA.
- L'accesso alla memoria in UMA è lento. D'altra parte, l'accesso alla memoria NUMA è più veloce dell'accesso alla memoria UMA.
Confronto testa a testa tra UMA e NUMA
Qui imparerai i confronti diretti tra UMA e NUMA. Le principali differenze tra UMA e NUMA sono le seguenti:
finestra javascript.open
| Caratteristiche | UNO | IN |
|---|---|---|
| Moduli completi | UMA è l'abbreviazione di Uniform Memory Access. | NUMA è l'abbreviazione di Non-Uniform Memory Access. |
| Controllore della memoria | Contiene un singolo controller di memoria. | Contiene diversi controller di memoria. |
| Tempo di accesso alla memoria | Contiene un tempo di accesso alla memoria bilanciato o uguale. | Il suo tempo di accesso alla memoria cambia in base alla distanza del microprocessore. |
| Accesso alla memoria | L'accesso alla memoria è lento. | L'accesso alla memoria è più veloce. |
| adeguatezza | Viene utilizzato principalmente in applicazioni time-sharing e per scopi generali. | Viene utilizzato principalmente in app time-critical e in tempo reale. |
| Larghezza di banda | Ha una larghezza di banda limitata. | Ha più larghezza di banda. |
| Tipo di autobus | Impiega bus singoli, multipli e trasversali. | Impiega bus e connessioni di rete gerarchici e strutturati ad albero. |
Conclusione
L'architettura UMA offre la stessa latenza complessiva per i processori che accedono alla memoria e non è particolarmente utile quando si accede alla memoria locale perché il ritardo sarebbe uniforme. Al contrario, in NUMA, ogni processore ha la propria memoria dedicata, che elimina il ritardo durante l'accesso alla memoria locale. Le modifiche alla latenza dipendono dalla distanza tra la CPU e le modifiche della memoria. Tuttavia, rispetto al design UMA, NUMA offre prestazioni migliori.