- L'algoritmo del vettore della distanza è un algoritmo dinamico.
- Viene utilizzato principalmente in ARPANET e RIP.
- Ogni router mantiene una tabella delle distanze nota come Vettore .
Tre chiavi per comprendere il funzionamento dell'algoritmo di routing vettoriale a distanza:
Algoritmo di routing del vettore di distanza
Sia dX(y) essere il costo del percorso meno costoso dal nodo x al nodo y. I costi minimi sono legati dall’equazione di Bellman-Ford,
d<sub>x</sub>(y) = min<sub>v</sub>{c(x,v) + d<sub>v</sub>(y)} Dove il minv è l'equazione presa per tutti gli x vicini. Dopo aver viaggiato da x a v, se consideriamo il percorso a costo minimo da v a y, il costo del percorso sarà c(x,v)+dIn(y). Il costo minimo da x a y è il minimo di c(x,v)+dIn(y) ha rilevato tutti i vicini.
Con l'algoritmo Distance Vector Routing, il nodo x contiene le seguenti informazioni di routing:
- Per ciascun vicino v, il costo c(x,v) è il costo del percorso da x al vicino direttamente collegato, v.
- Il vettore distanza x, cioè DX= [DX(y) : y in N ], contenente il suo costo per tutte le destinazioni, y, in N.
- Il vettore distanza di ciascuno dei suoi vicini, cioè DIn= [DIn(y) : y in N ] per ogni vicino v di x.
Il routing del vettore distanza è un algoritmo asincrono in cui il nodo x invia la copia del suo vettore distanza a tutti i suoi vicini. Quando il nodo x riceve il nuovo vettore distanza da uno dei suoi vettori vicini, v, salva il vettore distanza di v e utilizza l'equazione di Bellman-Ford per aggiornare il proprio vettore distanza. L'equazione è riportata di seguito:
scaricare video da youtube con vlc
d<sub>x</sub>(y) = min<sub>v</sub>{ c(x,v) + d<sub>v</sub>(y)} for each node y in N Il nodo x ha aggiornato la propria tabella dei vettori di distanza utilizzando l'equazione precedente e invia la tabella aggiornata a tutti i suoi vicini in modo che possano aggiornare i propri vettori di distanza.
Algoritmo
At each node x, <p> <strong>Initialization</strong> </p> for all destinations y in N: D<sub>x</sub>(y) = c(x,y) // If y is not a neighbor then c(x,y) = ∞ for each neighbor w D<sub>w</sub>(y) = ? for all destination y in N. for each neighbor w send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to w <strong>loop</strong> <strong>wait</strong> (until I receive any distance vector from some neighbor w) for each y in N: D<sub>x</sub>(y) = minv{c(x,v)+D<sub>v</sub>(y)} If D<sub>x</sub>(y) is changed for any destination y Send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to all neighbors <strong>forever</strong> Nota: nell'algoritmo del vettore di distanza, il nodo x aggiorna la sua tabella quando vede qualsiasi cambiamento di costo in un nodo direttamente collegato o riceve qualsiasi aggiornamento del vettore da qualche vicino.
Capiamo attraverso un esempio:
Condividere informazioni
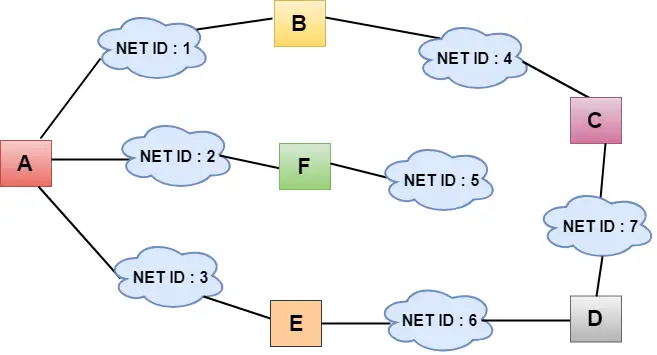
- Nella figura sopra, ogni nuvola rappresenta la rete e il numero all'interno della nuvola rappresenta l'ID di rete.
- Tutte le LAN sono connesse tramite router e sono rappresentate in caselle etichettate come A, B, C, D, E, F.
- L'algoritmo di routing del vettore di distanza semplifica il processo di routing presupponendo che il costo di ogni collegamento sia un'unità. Pertanto, l'efficienza della trasmissione può essere misurata dal numero di collegamenti per raggiungere la destinazione.
- Nel routing del vettore di distanza, il costo è basato sul conteggio dei hop.

Nella figura sopra osserviamo che il router invia la conoscenza ai vicini immediati. I vicini aggiungono questa conoscenza alla propria conoscenza e inviano la tabella aggiornata ai propri vicini. In questo modo, i router ottengono le proprie informazioni oltre alle nuove informazioni sui vicini.
Tabella di instradamento
Si verificano due processi:
- Creazione della tabella
- Aggiornamento della tabella
Creazione della tabella
Inizialmente, per ciascun router viene creata la tabella di routing che contiene almeno tre tipi di informazioni come ID di rete, costo e hop successivo.


- Nella figura sopra sono mostrate le tabelle di routing originali di tutti i router. In una tabella di routing, la prima colonna rappresenta l'ID di rete, la seconda colonna rappresenta il costo del collegamento e la terza colonna è vuota.
- Queste tabelle di routing vengono inviate a tutti i vicini.
Per esempio:
A sends its routing table to B, F & E. B sends its routing table to A & C. C sends its routing table to B & D. D sends its routing table to E & C. E sends its routing table to A & D. F sends its routing table to A.
Aggiornamento della tabella
- Quando A riceve una tabella di routing da B, utilizza le sue informazioni per aggiornare la tabella.
- La tabella di instradamento di B mostra come i pacchetti possono spostarsi verso le reti 1 e 4.
- Il router B è un vicino al router A, i pacchetti da A a B possono raggiungerlo in un salto. Quindi, a tutti i costi indicati nella tabella B viene aggiunto 1 e la somma sarà il costo per raggiungere una determinata rete.

- Dopo la regolazione, A combina questa tabella con la propria tabella per creare una tabella combinata.

- La tabella combinata potrebbe contenere alcuni dati duplicati. Nella figura sopra, la tabella combinata del router A contiene i dati duplicati, quindi conserva solo i dati che hanno il costo più basso. Ad esempio, A può inviare i dati alla rete 1 in due modi. Il primo, che non utilizza il router successivo, quindi costa un hop. Il secondo richiede due hop (da A a B, quindi da B alla rete 1). La prima opzione ha il costo più basso, pertanto viene mantenuta e la seconda viene abbandonata.

- Il processo di creazione della tabella di routing continua per tutti i router. Ogni router riceve le informazioni dai vicini e aggiorna la tabella di routing.
Di seguito sono riportate le tabelle finali di routing di tutti i router:
