Le mappe hash sono strutture dati indicizzate. Una mappa hash utilizza a funzione hash per calcolare un indice con una chiave in un array di bucket o slot. Il suo valore è mappato sul bucket con l'indice corrispondente. La chiave è unica e immutabile. Pensa a una mappa hash come a un armadietto dotato di cassetti con etichette per le cose conservate al loro interno. Ad esempio, memorizzando le informazioni dell'utente: considera l'e-mail come chiave e possiamo mappare i valori corrispondenti a quell'utente come il nome, il cognome ecc. su un bucket.
La funzione hash è il fulcro dell'implementazione di una mappa hash. Prende la chiave e la traduce nell'indice di un bucket nell'elenco dei bucket. L'hashing ideale dovrebbe produrre un indice diverso per ciascuna chiave. Tuttavia possono verificarsi collisioni. Quando l'hashing fornisce un indice esistente, possiamo semplicemente utilizzare un bucket per più valori aggiungendo un elenco o eseguendo nuovamente l'hashing.
In Python, i dizionari sono esempi di mappe hash. Vedremo l'implementazione della mappa hash da zero per imparare come costruire e personalizzare tali strutture di dati per ottimizzare la ricerca.
ordina l'arraylist in Java
Il design della mappa hash includerà le seguenti funzioni:
- set_val(chiave, valore): Inserisce una coppia chiave-valore nella mappa hash. Se il valore esiste già nella mappa hash, aggiorna il valore.
- get_val(chiave): Restituisce il valore a cui è mappata la chiave specificata oppure Nessun record trovato se questa mappa non contiene alcuna mappatura per la chiave.
- delete_val(chiave): Rimuove la mappatura per la chiave specifica se la mappa hash contiene la mappatura per la chiave.
Di seguito è riportata l'implementazione.
Python3
convertire la stringa in json in Java
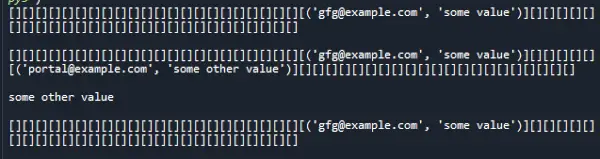
class> HashTable:> ># Create empty bucket list of given size> >def> __init__(>self>, size):> >self>.size>=> size> >self>.hash_table>=> self>.create_buckets()> >def> create_buckets(>self>):> >return> [[]>for> _>in> range>(>self>.size)]> ># Insert values into hash map> >def> set_val(>self>, key, val):> > ># Get the index from the key> ># using hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be inserted> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key to be inserted,> ># Update the key value> ># Otherwise append the new key-value pair to the bucket> >if> found_key:> >bucket[index]>=> (key, val)> >else>:> >bucket.append((key, val))> ># Return searched value with specific key> >def> get_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key being searched> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key being searched,> ># Return the value found> ># Otherwise indicate there was no record found> >if> found_key:> >return> record_val> >else>:> >return> 'No record found'> ># Remove a value with specific key> >def> delete_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be deleted> >if> record_key>=>=> key:> >found_key>=> True> >break> >if> found_key:> >bucket.pop(index)> >return> ># To print the items of hash map> >def> __str__(>self>):> >return> ''.join(>str>(item)>for> item>in> self>.hash_table)> hash_table>=> HashTable(>50>)> # insert some values> hash_table.set_val(>'[email protected]'>,>'some value'>)> print>(hash_table)> print>()> hash_table.set_val(>'[email protected]'>,>'some other value'>)> print>(hash_table)> print>()> # search/access a record with key> print>(hash_table.get_val(>'[email protected]'>))> print>()> # delete or remove a value> hash_table.delete_val(>'[email protected]'>)> print>(hash_table)> |
>
>
Produzione:
mysql elenca tutti gli utenti
Complessità temporale:
iterando un elenco in Java
L'accesso all'indice di memoria richiede tempo costante e l'hashing richiede tempo costante. Quindi, anche la complessità della ricerca di una mappa hash è tempo costante, ovvero O(1).
Vantaggi delle HashMap
● Accesso rapido e casuale alla memoria tramite funzioni hash
● È possibile utilizzare valori negativi e non interi per accedere ai valori.
● Le chiavi possono essere memorizzate in ordine ordinato quindi possono scorrere facilmente le mappe.
Svantaggi delle HashMap
carattere gimp
● Le collisioni possono causare gravi penalità e rendere lineare la complessità temporale.
● Quando il numero di chiavi è elevato, una singola funzione hash spesso provoca collisioni.
Applicazioni di HashMap
● Hanno applicazioni nelle implementazioni di Cache in cui le posizioni di memoria sono mappate su piccoli insiemi.
● Vengono utilizzati per indicizzare le tuple nei sistemi di gestione dei database.
● Vengono utilizzati anche in algoritmi come il pattern match di Rabin Karp