UN Rete neurale convoluzionale (CNN) è un tipo di architettura di rete neurale Deep Learning comunemente utilizzata nella visione artificiale. La visione artificiale è un campo dell'intelligenza artificiale che consente a un computer di comprendere e interpretare l'immagine o i dati visivi.
Quando si parla di Machine Learning, Reti neurali artificiali comportarsi davvero bene. Le reti neurali vengono utilizzate in vari set di dati come immagini, audio e testo. Diversi tipi di reti neurali vengono utilizzate per scopi diversi, ad esempio per prevedere la sequenza delle parole che utilizziamo Reti neurali ricorrenti più precisamente un LSTM , analogamente per la classificazione delle immagini utilizziamo le reti neurali di convoluzione. In questo blog costruiremo un elemento base per la CNN.
In una normale rete neurale ci sono tre tipi di strati:
- Livelli di input: È il livello in cui diamo input al nostro modello. Il numero di neuroni in questo strato è uguale al numero totale di caratteristiche nei nostri dati (numero di pixel nel caso di un'immagine).
- Livello nascosto: L'input dal livello Input viene quindi inserito nel livello nascosto. Possono esserci molti livelli nascosti a seconda del modello e della dimensione dei dati. Ogni strato nascosto può avere un numero diverso di neuroni che generalmente è maggiore del numero di caratteristiche. L'output di ciascun livello viene calcolato mediante moltiplicazione matriciale dell'output dello strato precedente con i pesi apprendibili di quello strato e quindi mediante l'aggiunta di bias apprendibili seguiti dalla funzione di attivazione che rende la rete non lineare.
- Livello di uscita: L'output dello strato nascosto viene quindi inserito in una funzione logistica come sigmoid o softmax che converte l'output di ciascuna classe nel punteggio di probabilità di ciascuna classe.
I dati vengono inseriti nel modello e viene chiamato l'output di ciascun livello ottenuto dal passaggio precedente feedforward , calcoliamo quindi l'errore utilizzando una funzione di errore, alcune funzioni di errore comuni sono l'entropia incrociata, l'errore di perdita quadrata, ecc. La funzione di errore misura le prestazioni della rete. Successivamente, eseguiamo la retropropagazione nel modello calcolando le derivate. Questo passaggio si chiama La rete neurale convoluzionale (CNN) è la versione estesa di reti neurali artificiali (ANN) che viene utilizzato prevalentemente per estrarre la funzionalità dal set di dati a matrice simile a una griglia. Ad esempio set di dati visivi come immagini o video in cui i modelli di dati svolgono un ruolo importante.
mylivericket
Architettura della CNN
La rete neurale convoluzionale è costituita da più livelli come il livello di input, il livello convoluzionale, il livello di pooling e i livelli completamente connessi.

Architettura semplice della CNN
Il livello convoluzionale applica filtri all'immagine di input per estrarre le funzionalità, il livello di pooling esegue il downsampling dell'immagine per ridurre il calcolo e il livello completamente connesso effettua la previsione finale. La rete apprende i filtri ottimali attraverso la backpropagation e la discesa del gradiente.
Come funzionano i livelli convoluzionali
Le reti neurali a convoluzione o covnet sono reti neurali che condividono i loro parametri. Immagina di avere un'immagine. Può essere rappresentato come un cuboide avente la sua lunghezza, larghezza (dimensione dell'immagine) e altezza (ovvero il canale poiché le immagini generalmente hanno canali rosso, verde e blu).
quante città negli Stati Uniti
Ora immagina di prendere una piccola porzione di questa immagine e di eseguire su di essa una piccola rete neurale, chiamata filtro o kernel, con, ad esempio, K output e di rappresentarli verticalmente. Ora fai scorrere quella rete neurale sull'intera immagine, di conseguenza otterremo un'altra immagine con larghezze, altezze e profondità diverse. Invece dei soli canali R, G e B ora abbiamo più canali ma larghezza e altezza minori. Questa operazione si chiama Convoluzione . Se la dimensione della patch è uguale a quella dell'immagine si tratterà di una normale rete neurale. A causa di questa piccola patch, abbiamo meno pesi.
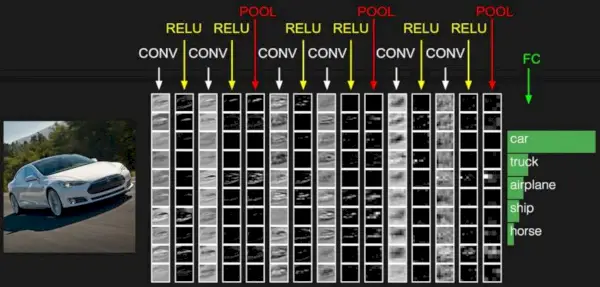
Fonte immagine: Deep Learning Udacity
Ora parliamo un po’ della matematica coinvolta nell’intero processo di convoluzione.
- I livelli di convoluzione sono costituiti da una serie di filtri apprendibili (o kernel) aventi larghezze e altezze ridotte e la stessa profondità di quella del volume di input (3 se il livello di input è un input di immagine).
- Se ad esempio dobbiamo eseguire la convoluzione su un'immagine di dimensioni 34x34x3. La dimensione possibile dei filtri può essere axax3, dove 'a' può essere qualcosa come 3, 5 o 7 ma più piccola rispetto alla dimensione dell'immagine.
- Durante il passaggio in avanti, facciamo scorrere ciascun filtro sull'intero volume di input passo dopo passo dove viene chiamato ogni passaggio passo (che può avere un valore di 2, 3 o anche 4 per immagini ad alta dimensione) e calcola il prodotto scalare tra i pesi del kernel e la patch dal volume di input.
- Mentre facciamo scorrere i nostri filtri otterremo un output 2-D per ciascun filtro e li impileremo insieme di conseguenza, otterremo un volume di output con una profondità pari al numero di filtri. La rete imparerà tutti i filtri.
Livelli utilizzati per creare ConvNet
Un'architettura completa di reti neurali a convoluzione è anche nota come covnet. Un covnet è una sequenza di strati e ogni strato trasforma un volume in un altro attraverso una funzione differenziabile.
Tipi di strati: set di dati
Facciamo un esempio eseguendo un covnet su un'immagine di dimensione 32 x 32 x 3.
- Livelli di input: È il livello in cui diamo input al nostro modello. Nella CNN, generalmente, l'input sarà un'immagine o una sequenza di immagini. Questo livello contiene l'input grezzo dell'immagine con larghezza 32, altezza 32 e profondità 3.
- Strati convoluzionali: Questo è il livello utilizzato per estrarre la feature dal set di dati di input. Applica una serie di filtri apprendibili noti come kernel alle immagini di input. I filtri/kernel sono matrici più piccole, solitamente di forma 2×2, 3×3 o 5×5. scorre sui dati dell'immagine di input e calcola il prodotto scalare tra il peso del kernel e la corrispondente patch dell'immagine di input. L'output di questo livello viene indicato come mappe delle caratteristiche. Supponiamo di utilizzare un totale di 12 filtri per questo livello, otterremo un volume di output di dimensione 32 x 32 x 12.
- Livello di attivazione: Aggiungendo una funzione di attivazione all'output dello strato precedente, gli strati di attivazione aggiungono nonlinearità alla rete. applicherà una funzione di attivazione basata sugli elementi all'output dello strato di convoluzione. Alcune funzioni di attivazione comuni sono riprendere : massimo(0, x), Di pesce , RELU che perde , ecc. Il volume rimane invariato quindi il volume di uscita avrà dimensioni 32 x 32 x 12.
- Livello di raggruppamento: Questo strato viene periodicamente inserito nei covnet e la sua funzione principale è ridurre la dimensione del volume, il che rende veloce il calcolo, riduce la memoria e previene anche l'overfitting. Due tipi comuni di livelli di pooling sono raggruppamento massimo E raggruppamento medio . Se utilizziamo una piscina max con 2 x 2 filtri e falcata 2, il volume risultante sarà di dimensione 16x16x12.
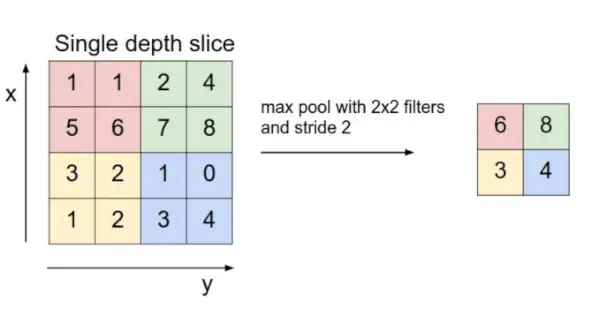
Fonte immagine: cs231n.stanford.edu
- Appiattimento: Le mappe delle caratteristiche risultanti vengono appiattite in un vettore unidimensionale dopo i livelli di convoluzione e di pooling in modo che possano essere passate a un livello completamente collegato per la categorizzazione o la regressione.
- Livelli completamente connessi: Prende l'input dal livello precedente e calcola la classificazione finale o l'attività di regressione.
Fonte immagine: cs231n.stanford.edu
- Livello di uscita: L'output degli strati completamente connessi viene quindi inserito in una funzione logistica per attività di classificazione come sigmoid o softmax che converte l'output di ciascuna classe nel punteggio di probabilità di ciascuna classe.
Esempio:
Consideriamo un'immagine e applichiamo l'operazione del livello di convoluzione, del livello di attivazione e del livello di pooling per estrarre la funzionalità interna.
c# dataora
Immagine in ingresso:
Immagine in ingresso
Fare un passo:
- importare le librerie necessarie
- impostare il parametro
- definire il kernel
- Carica l'immagine e stampala.
- Riformatta l'immagine
- Applicare l'operazione del livello di convoluzione e tracciare l'immagine di output.
- Applicare l'operazione del livello di attivazione e tracciare l'immagine di output.
- Applicare l'operazione del livello di pooling e tracciare l'immagine di output.
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
ordinare un elenco di array
>
Produzione :

Immagine originale in scala di grigi
Produzione
Vantaggi delle reti neurali convoluzionali (CNN):
- Ottimo nel rilevare modelli e caratteristiche in immagini, video e segnali audio.
- Robusto alla traslazione, alla rotazione e all'invarianza di scala.
- Formazione end-to-end, senza necessità di estrazione manuale delle funzionalità.
- Può gestire grandi quantità di dati e ottenere un'elevata precisione.
Svantaggi delle reti neurali convoluzionali (CNN):
- Computazionalmente costoso da addestrare e richiede molta memoria.
- Può essere soggetto a overfitting se non vengono utilizzati dati sufficienti o una regolarizzazione adeguata.
- Richiede grandi quantità di dati etichettati.
- L’interpretabilità è limitata, è difficile capire cosa abbia imparato la rete.
Domande frequenti (FAQ)
1: Cos'è una rete neurale convoluzionale (CNN)?
Una rete neurale convoluzionale (CNN) è un tipo di rete neurale di deep learning adatta per l'analisi di immagini e video. Le CNN utilizzano una serie di livelli di convoluzione e pooling per estrarre funzionalità da immagini e video, quindi utilizzare queste funzionalità per classificare o rilevare oggetti o scene.
2: Come funzionano le CNN?
Le CNN funzionano applicando una serie di livelli di convoluzione e pooling a un'immagine o un video di input. I livelli di convoluzione estraggono le caratteristiche dall'input facendo scorrere un piccolo filtro, o kernel, sull'immagine o sul video e calcolando il prodotto scalare tra il filtro e l'input. I livelli di pooling eseguono quindi il downsampling dell'output dei livelli di convoluzione per ridurre la dimensionalità dei dati e renderli più efficienti dal punto di vista computazionale.
3: Quali sono alcune funzioni di attivazione comuni utilizzate nelle CNN?
Alcune funzioni di attivazione comuni utilizzate nelle CNN includono:
lattice di dimensione carattere
- Unità lineare rettificata (ReLU): ReLU è una funzione di attivazione non saturante che è computazionalmente efficiente e facile da addestrare.
- Leaky Rectified Linear Unit (Leaky ReLU): Leaky ReLU è una variante di ReLU che consente a una piccola quantità di gradiente negativo di fluire attraverso la rete. Ciò può aiutare a evitare che la rete muoia durante l'addestramento.
- Unità lineare rettificata parametrica (PReLU): PReLU è una generalizzazione di Leaky ReLU che consente di apprendere la pendenza del gradiente negativo.
4: Qual è lo scopo dell'utilizzo di più livelli di convoluzione in una CNN?
L'utilizzo di più livelli di convoluzione in una CNN consente alla rete di apprendere funzionalità sempre più complesse dall'immagine o dal video in ingresso. I primi livelli di convoluzione apprendono caratteristiche semplici, come bordi e angoli. I livelli di convoluzione più profondi apprendono caratteristiche più complesse, come forme e oggetti.
5: Quali sono alcune tecniche di regolarizzazione comuni utilizzate nelle CNN?
Le tecniche di regolarizzazione vengono utilizzate per impedire alle CNN di sovradimensionare i dati di addestramento. Alcune tecniche di regolarizzazione comuni utilizzate nelle CNN includono:
- Dropout: Il dropout elimina casualmente i neuroni dalla rete durante l'allenamento. Ciò costringe la rete ad apprendere funzionalità più robuste che non dipendono da nessun singolo neurone.
- Regolarizzazione L1: La regolarizzazione L1 regolarizza il valore assoluto dei pesi nella rete. Ciò può aiutare a ridurre il numero di pesi e rendere la rete più efficiente.
- Regolarizzazione L2: La regolarizzazione L2 regolarizza il quadrato dei pesi nella rete. Ciò può anche aiutare a ridurre il numero di pesi e rendere la rete più efficiente.
6: Qual è la differenza tra uno strato di convoluzione e uno strato di pooling?
Un livello di convoluzione estrae le funzionalità da un'immagine o un video di input, mentre un livello di pooling esegue il downsampling dell'output dei livelli di convoluzione. I livelli di convoluzione utilizzano una serie di filtri per estrarre le funzionalità, mentre i livelli di pooling utilizzano una varietà di tecniche per sottocampionare i dati, come il pooling massimo e il pooling medio.