Nella sezione precedente abbiamo fatto una breve introduzione su Apache Kafka, sul sistema di messaggistica e sul processo di streaming. Qui discuteremo i concetti di base e il ruolo di Kafka.
Temi
Generalmente, un argomento si riferisce a un titolo particolare o a un nome dato ad alcune idee specifiche correlate. In Kafka, la parola argomento si riferisce a una categoria o a un nome comune utilizzato per archiviare e pubblicare un particolare flusso di dati. Fondamentalmente, gli argomenti in Kafka sono simili alle tabelle del database, ma non contengono tutti i vincoli. In Kafka possiamo creare n numero di argomenti come vogliamo. È identificato dal suo nome, che dipende dalla scelta dell'utente. Un produttore pubblica i dati negli argomenti e un consumatore legge i dati dall'argomento iscrivendosi.
Partizioni
Un argomento è suddiviso in più parti note come partizioni dell'argomento. Queste partizioni sono separate in un ordine. Il contenuto dei dati viene archiviato nelle partizioni all'interno dell'argomento. Pertanto, durante la creazione di un argomento, dobbiamo specificare il numero di partizioni (il numero è arbitrario e può essere modificato in seguito). Ogni messaggio viene archiviato in partizioni con un ID incrementale noto come valore Offset. L'ordine del valore di compensazione è garantito solo all'interno della partizione e non al suo interno. Gli offset per una partizione sono infiniti.
Nota:I dati una volta scritti su una partizione non possono mai essere modificati. È immutabile. Il valore di offset rimane sempre in uno stato incrementale, non torna mai in uno spazio vuoto. Inoltre, i dati vengono conservati in una partizione solo per un periodo limitato.
Vediamo un esempio per comprendere un argomento con le sue partizioni.
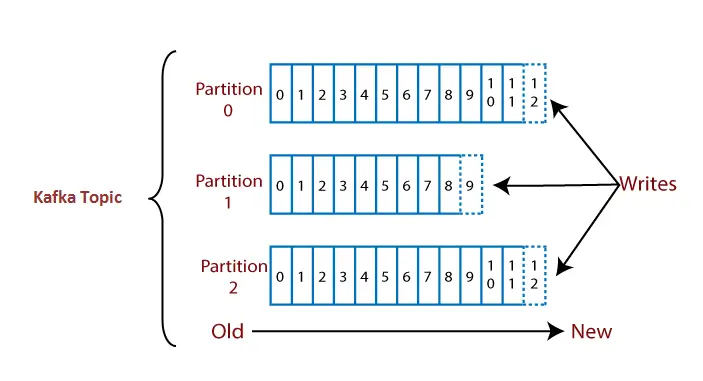
Supponiamo che un argomento contenga tre partizioni 0,1 e 2. Ogni partizione ha numeri di offset diversi. I dati vengono distribuiti tra ciascun offset in ciascuna partizione in cui i dati nell'offset 1 della Partizione 0 non hanno alcuna relazione con i dati nell'offset 1 della Partizione 1. Tuttavia, i dati nell'offset 1 della Partizione 0 sono correlati ai dati contenuti nell'offset 2 della Partizione 0.
Broker
Qui entra in gioco il ruolo di Apache Kafka.
Un cluster Kafka è composto da uno o più server noti come broker o broker Kafka. Un broker è un contenitore che contiene diversi argomenti con le relative partizioni multiple. I broker nel cluster sono identificati solo da un ID intero. I broker Kafka sono anche conosciuti come Broker bootstrap perché la connessione con un qualsiasi broker significa connessione con l'intero cluster. Sebbene un broker non contenga dati interi, ciascun broker nel cluster conosce tutti gli altri broker, le partizioni e gli argomenti.

Ecco come appare un broker nella figura contenente un argomento con n numero di partizioni.
Esempio: Broker e argomenti
Supponiamo che un cluster Kafka sia composto da tre broker, vale a dire Broker 1, Broker 2 e Broker 3.

Ogni broker contiene un argomento, vale a dire Topic-x con tre partizioni 0,1 e 2. Ricorda, tutte le partizioni non appartengono a un solo broker, sono sempre distribuite tra ciascun broker (dipende dalla quantità). Broker 1 e Broker 2 contengono un altro topic-y con due partizioni 0 e 1. Pertanto, Broker 3 non contiene alcun dato da Topic-y. Si conclude inoltre che non esiste mai alcuna relazione tra il numero del broker e il numero della partizione.