La regressione lineare e la regressione logistica sono i due famosi algoritmi di apprendimento automatico che rientrano nella tecnica di apprendimento supervisionato. Poiché entrambi gli algoritmi sono di natura supervisionata, questi algoritmi utilizzano set di dati etichettati per fare previsioni. Ma la differenza principale tra loro è il modo in cui vengono utilizzati. La regressione lineare viene utilizzata per risolvere i problemi di regressione mentre la regressione logistica viene utilizzata per risolvere i problemi di classificazione. La descrizione di entrambi gli algoritmi è fornita di seguito insieme alla tabella delle differenze.
Regressione lineare:
- La regressione lineare è uno degli algoritmi di apprendimento automatico più semplici che rientrano nella tecnica di apprendimento supervisionato e utilizzato per risolvere problemi di regressione.
- Viene utilizzato per prevedere la variabile dipendente continua con l'aiuto di variabili indipendenti.
- L'obiettivo della regressione lineare è trovare la linea di adattamento migliore in grado di prevedere con precisione l'output per la variabile dipendente continua.
- Se per la previsione viene utilizzata una singola variabile indipendente, allora viene chiamata regressione lineare semplice e se sono presenti più di due variabili indipendenti, tale regressione viene chiamata regressione lineare multipla.
- Trovando la linea di adattamento migliore, l'algoritmo stabilisce la relazione tra la variabile dipendente e la variabile indipendente. E la relazione dovrebbe essere di natura lineare.
- L'output per la regressione lineare dovrebbe essere solo valori continui come prezzo, età, stipendio, ecc. La relazione tra la variabile dipendente e la variabile indipendente può essere mostrata nell'immagine seguente:

Nell'immagine sopra la variabile dipendente è sull'asse Y (stipendio) e la variabile indipendente è sull'asse x (esperienza). La retta di regressione può essere scritta come:
y= a<sub>0</sub>+a<sub>1</sub>x+ ε
Dove un0e un1sono i coefficienti e ε è il termine di errore.
Regressione logistica:
- La regressione logistica è uno degli algoritmi di apprendimento automatico più popolari che rientra nelle tecniche di apprendimento supervisionato.
- Può essere utilizzato sia per problemi di classificazione che per problemi di regressione, ma principalmente per problemi di classificazione.
- La regressione logistica viene utilizzata per prevedere la variabile dipendente categoriale con l'aiuto di variabili indipendenti.
- L'output del problema di regressione logistica può essere solo compreso tra 0 e 1.
- La regressione logistica può essere utilizzata quando è richiesta la probabilità tra due classi. Ad esempio se pioverà oggi o no, 0 o 1, vero o falso, ecc.
- La regressione logistica si basa sul concetto di stima della massima verosimiglianza. Secondo questa stima, i dati osservati dovrebbero essere più probabili.
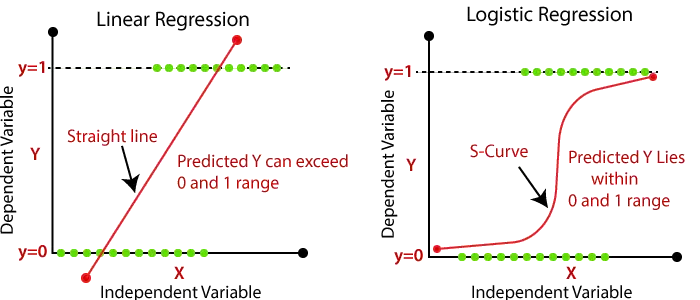
- Nella regressione logistica, passiamo la somma ponderata degli input attraverso una funzione di attivazione che può mappare valori compresi tra 0 e 1. Tale funzione di attivazione è nota come funzione sigmoidea e la curva ottenuta è chiamata curva sigmoidea o curva a S. Considera l'immagine qui sotto:

- L’equazione per la regressione logistica è:

Differenza tra regressione lineare e regressione logistica:
| Regressione lineare | Regressione logistica |
|---|---|
| La regressione lineare viene utilizzata per prevedere la variabile dipendente continua utilizzando un dato insieme di variabili indipendenti. | La regressione logistica viene utilizzata per prevedere la variabile dipendente categoriale utilizzando un determinato insieme di variabili indipendenti. |
| La regressione lineare viene utilizzata per risolvere il problema della regressione. | La regressione logistica viene utilizzata per risolvere problemi di classificazione. |
| Nella regressione lineare, prevediamo il valore delle variabili continue. | Nella regressione logistica, prevediamo i valori delle variabili categoriali. |
| Nella regressione lineare, troviamo la linea più adatta, con la quale possiamo facilmente prevedere l'output. | Nella regressione logistica troviamo la curva a S con la quale possiamo classificare i campioni. |
| Il metodo di stima dei minimi quadrati viene utilizzato per la stima dell'accuratezza. | Il metodo di stima della massima verosimiglianza viene utilizzato per la stima dell'accuratezza. |
| L'output per la regressione lineare deve essere un valore continuo, come prezzo, età, ecc. | L'output della regressione logistica deve essere un valore categoriale come 0 o 1, Sì o No, ecc. |
| Nella regressione lineare, è necessario che la relazione tra la variabile dipendente e la variabile indipendente sia lineare. | Nella regressione logistica non è necessario avere una relazione lineare tra la variabile dipendente e quella indipendente. |
| Nella regressione lineare, può esserci collinearità tra le variabili indipendenti. | Nella regressione logistica, non dovrebbe esserci collinearità tra la variabile indipendente. |