Un cursore in SQL Server è un d oggetto atabase che ci consente di recuperare ogni riga alla volta e manipolarne i dati . Un cursore non è altro che un puntatore a una riga. Viene sempre utilizzato insieme a un'istruzione SELECT. Di solito è una raccolta di SQL logica che scorre un numero predeterminato di righe una per una. Un semplice esempio del cursore si ha quando disponiamo di un ampio database di documenti dei lavoratori e desideriamo calcolare lo stipendio di ciascun lavoratore al netto delle tasse e delle ferie.
L'SQLServer lo scopo del cursore è aggiornare i dati riga per riga, modificarli o eseguire calcoli che non sono possibili quando recuperiamo tutti i record contemporaneamente . È utile anche per eseguire attività amministrative come i backup del database SQL Server in ordine sequenziale. I cursori vengono utilizzati principalmente nei processi di sviluppo, DBA ed ETL.
Questo articolo spiega tutto sul cursore di SQL Server, come il ciclo di vita del cursore, perché e quando viene utilizzato il cursore, come implementare i cursori, i suoi limiti e come possiamo sostituire un cursore.
Ciclo di vita del cursore
Possiamo descrivere il ciclo di vita di un cursore nel file cinque diverse sezioni come segue:
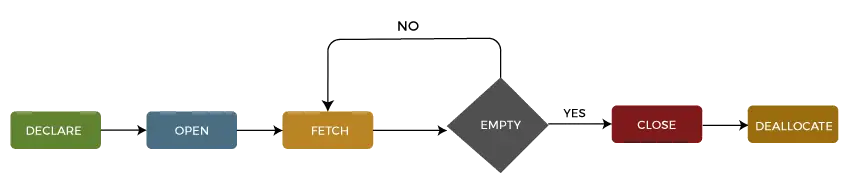
1: Dichiara cursore
Il primo passo è dichiarare il cursore utilizzando l'istruzione SQL seguente:
ascii di a in Java
DECLARE cursor_name CURSOR FOR select_statement;
Possiamo dichiarare un cursore specificandone il nome con il tipo di dati CURSOR dopo la parola chiave DECLARE. Quindi scriveremo l'istruzione SELECT che definisce l'output per il cursore.
2: Apri cursore
È un secondo passaggio in cui apriamo il cursore per memorizzare i dati recuperati dal set di risultati. Possiamo farlo utilizzando la seguente istruzione SQL:
OPEN cursor_name;
3: Recupera cursore
È un terzo passaggio in cui le righe possono essere recuperate una per una o in un blocco per eseguire operazioni di manipolazione dei dati come operazioni di inserimento, aggiornamento ed eliminazione sulla riga attualmente attiva nel cursore. Possiamo farlo utilizzando la seguente istruzione SQL:
FETCH NEXT FROM cursor INTO variable_list;
Possiamo anche usare il @@FETCHSTATUS funzione in SQL Server per ottenere lo stato del cursore dell'istruzione FETCH più recente eseguito rispetto al cursore. IL ANDARE A PRENDERE l'istruzione ha avuto esito positivo quando @@FETCHSTATUS fornisce un output pari a zero. IL MENTRE può essere utilizzata per recuperare tutti i record dal cursore. Il codice seguente lo spiega più chiaramente:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Chiudi cursore
È un quarto passaggio in cui il cursore dovrebbe essere chiuso dopo aver finito di lavorare con un cursore. Possiamo farlo utilizzando la seguente istruzione SQL:
CLOSE cursor_name;
5: Dealloca il cursore
È il quinto e ultimo passaggio in cui cancelleremo la definizione del cursore e rilasceremo tutte le risorse di sistema associate al cursore. Possiamo farlo utilizzando la seguente istruzione SQL:
DEALLOCATE cursor_name;
Usi del cursore di SQL Server
Sappiamo che i sistemi di gestione di database relazionali, incluso SQL Server, sono eccellenti nella gestione dei dati su un insieme di righe chiamato set di risultati. Per esempio , abbiamo un tavolo tabella_prodotto che contiene le descrizioni dei prodotti. Se vogliamo aggiornare il prezzo del prodotto, quindi il seguente ' AGGIORNAMENTO' la query aggiornerà tutti i record che corrispondono alla condizione nel campo ' DOVE' clausola:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
A volte l'applicazione deve elaborare le righe in modalità singleton, ovvero riga per riga anziché l'intero set di risultati in una volta. Possiamo eseguire questo processo utilizzando i cursori in SQL Server. Prima di utilizzare il cursore, dobbiamo sapere che i cursori hanno prestazioni pessime, quindi dovrebbero essere sempre utilizzati solo quando non c'è altra opzione tranne il cursore.
Il cursore utilizza la stessa tecnica con cui usiamo cicli come FOREACH, FOR, WHILE, DO WHILE per ripetere un oggetto alla volta in tutti i linguaggi di programmazione. Pertanto, potrebbe essere scelto perché applica la stessa logica del processo di looping del linguaggio di programmazione.
Tipi di cursori in SQL Server
Di seguito sono riportati i diversi tipi di cursori in SQL Server elencati di seguito:
- Cursori statici
- Cursori dinamici
- Cursori di solo inoltro
- Cursori del set di tasti

Cursori statici
Il set di risultati mostrato dal cursore statico è sempre lo stesso di quando il cursore è stato aperto per la prima volta. Poiché il cursore statico memorizzerà il risultato in tempdb , lo sono sempre sola lettura . Possiamo usare il cursore statico per spostarci sia avanti che indietro. A differenza di altri cursori, è più lento e consuma più memoria. Di conseguenza, possiamo usarlo solo quando è necessario lo scorrimento e altri cursori non sono adatti.
Questo cursore mostra le righe rimosse dal database dopo l'apertura. Un cursore statico non rappresenta alcuna operazione INSERT, UPDATE o DELETE (a meno che il cursore non venga chiuso e riaperto).
altezza kat timpf
Cursori dinamici
I cursori dinamici sono opposti ai cursori statici che ci consentono di eseguire le operazioni di aggiornamento, cancellazione e inserimento dei dati mentre il cursore è aperto. È scorrevole per impostazione predefinita . È in grado di rilevare tutte le modifiche apportate alle righe, all'ordine e ai valori nel set di risultati, indipendentemente dal fatto che le modifiche avvengano all'interno o all'esterno del cursore. Al di fuori del cursore, non possiamo vedere gli aggiornamenti finché non vengono confermati.
Cursori di solo inoltro
È il tipo di cursore predefinito e più veloce tra tutti i cursori. È chiamato cursore di solo inoltro perché si sposta solo in avanti attraverso il set di risultati . Questo cursore non supporta lo scorrimento. Può recuperare solo le righe dall'inizio alla fine del set di risultati. Ci consente di eseguire operazioni di inserimento, aggiornamento ed eliminazione. Qui, l'effetto delle operazioni di inserimento, aggiornamento ed eliminazione effettuate dall'utente che influiscono sulle righe nel set di risultati è visibile mentre le righe vengono recuperate dal cursore. Quando la riga è stata recuperata, non possiamo vedere le modifiche apportate alle righe tramite il cursore.
I cursori di solo inoltro sono suddivisi in tre tipi:
- Set di chiavi Solo_inoltro
- Inoltra_Solo statico
- Avanti veloce

Cursori guidati da keyset
Questa funzionalità del cursore si trova tra un cursore statico e uno dinamico per quanto riguarda la sua capacità di rilevare i cambiamenti. Non è sempre in grado di rilevare modifiche nell'appartenenza e nell'ordine del set di risultati come un cursore statico. Può rilevare le modifiche nei valori delle righe del set di risultati come un cursore dinamico. Può solo spostarsi dalla prima all'ultima e dall'ultima alla prima riga . L'ordine e l'appartenenza vengono fissi ogni volta che si apre questo cursore.
È gestito da una serie di identificatori univoci uguali alle chiavi nel set di chiavi. Il keyset è determinato da tutte le righe che hanno qualificato l'istruzione SELECT quando il cursore è stato aperto per la prima volta. Può anche rilevare eventuali modifiche all'origine dati, che supporta le operazioni di aggiornamento ed eliminazione. È scorrevole per impostazione predefinita.
Implementazione dell'esempio
Implementiamo l'esempio del cursore nel server SQL. Possiamo farlo creando prima una tabella denominata ' cliente ' utilizzando la seguente istruzione:
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Successivamente, inseriremo i valori nella tabella. Possiamo eseguire l'istruzione seguente per aggiungere dati in una tabella:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Possiamo verificare i dati eseguendo il comando SELEZIONARE dichiarazione:
SELECT * FROM customer;
Dopo aver eseguito la query, possiamo vedere l'output seguente dove abbiamo otto righe nella tabella:

Ora creeremo un cursore per visualizzare i record del cliente. I frammenti di codice seguenti spiegano tutti i passaggi della dichiarazione o creazione del cursore mettendo tutto insieme:
come convertire un carattere in una stringa Java
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Dopo aver eseguito un cursore, otterremo l'output seguente:

Limitazioni del cursore di SQL Server
Un cursore ha alcune limitazioni per cui dovrebbe essere sempre utilizzato solo quando non c'è altra opzione tranne il cursore. Queste limitazioni sono:
- Il cursore consuma risorse di rete richiedendo un andata e ritorno di rete ogni volta che recupera un record.
- Un cursore è un insieme di puntatori residenti in memoria, il che significa che richiede memoria che altri processi potrebbero utilizzare sulla nostra macchina.
- Impone blocchi su una parte della tabella o sull'intera tabella durante l'elaborazione dei dati.
- Le prestazioni e la velocità del cursore sono più lente perché aggiornano i record della tabella una riga alla volta.
- I cursori sono più veloci dei cicli while, ma hanno un sovraccarico maggiore.
- Il numero di righe e colonne portate nel cursore è un altro aspetto che influisce sulla velocità del cursore. Si riferisce al tempo necessario per aprire il cursore ed eseguire un'istruzione fetch.
Come possiamo evitare i cursori?
Il compito principale dei cursori è attraversare la tabella riga per riga. Il modo più semplice per evitare i cursori è riportato di seguito:
Utilizzando il ciclo while SQL
Il modo più semplice per evitare l'uso di un cursore è utilizzare un ciclo while che consente l'inserimento di un set di risultati nella tabella temporanea.
Funzioni definite dall'utente
A volte i cursori vengono utilizzati per calcolare il set di righe risultante. Possiamo ottenere questo risultato utilizzando una funzione definita dall'utente che soddisfi i requisiti.
Utilizzo dei join
Join elabora solo le colonne che soddisfano la condizione specificata e quindi riduce le righe di codice che forniscono prestazioni più veloci rispetto ai cursori nel caso in cui sia necessario elaborare record di grandi dimensioni.