I fogli Excel sono molto istintivi e facili da usare, il che li rende ideali per manipolare set di dati di grandi dimensioni anche per persone meno tecniche. Se stai cercando luoghi in cui imparare a manipolare e automatizzare elementi nei file Excel utilizzando Pitone , non guardare oltre. Sei nel posto giusto.
In questo articolo imparerai come usarlo Panda per lavorare con fogli di calcolo Excel. In questo articolo impareremo a conoscere:
- Leggere File Excel utilizzando Panda in Python
- Installazione e importazione di Panda
- Lettura di più fogli Excel utilizzando Panda
- Applicazione di diverse funzioni Panda
Lettura di file Excel utilizzando Panda in Python
Installazione di Panda
Per installare Pandas in Python, possiamo utilizzare il seguente comando nel prompt dei comandi:
pip install pandas>
Per installare Panda in Anaconda, possiamo utilizzare il seguente comando in Anaconda Terminal:
conda install pandas>
Importazione di panda
Prima di tutto dobbiamo importare il modulo Pandas, operazione che può essere eseguita eseguendo il comando:
sostituisci tutto nella stringa java
Python3
import> pandas as pd> |
>
>
File di input: Supponiamo che il file Excel sia simile a questo
Foglio 1:

Foglio 1
Foglio 2:
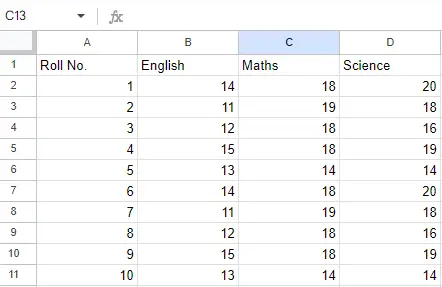
Foglio 2
Ora possiamo importare il file Excel utilizzando la funzione read_excel in Pandas per leggere il file Excel utilizzando Pandas in Python. La seconda istruzione legge i dati da Excel e li memorizza in un Data Frame panda rappresentato dalla variabile newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Produzione:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Caricamento di più fogli utilizzando il metodo Concat()
Se nella cartella di lavoro di Excel sono presenti più fogli, il comando importerà i dati dal primo foglio. Per creare un frame di dati con tutti i fogli della cartella di lavoro, il metodo più semplice è creare diversi frame di dati separatamente e quindi concatenarli. Il metodo read_excel prende come argomenti sheet_name e index_col dove possiamo specificare il foglio di cui dovrebbe essere composto il frame e index_col specifica la colonna del titolo, come mostrato di seguito:
Esempio:
La terza istruzione concatena entrambi i fogli. Ora per controllare l'intero frame di dati, possiamo semplicemente eseguire il seguente comando:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Produzione:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metodi Head() e Tail() in Panda
Per visualizzare 5 colonne dall'alto e dal basso del frame dati, possiamo eseguire il comando. Questo Testa() E coda() accetta anche argomenti come numeri per il numero di colonne da mostrare.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Produzione:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metodo Forma()
IL metodo forma() può essere utilizzato per visualizzare il numero di righe e colonne nel frame di dati come segue:
Python3
newData.shape> |
>
>
Produzione:
(20, 3)>
Metodo Sort_values() in Panda
Se una colonna contiene dati numerici, possiamo ordinarla utilizzando il comando sort_values() metodo nei panda come segue:
Python3
Java oggettivo
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Ora, supponiamo di volere i primi 5 valori della colonna ordinata, possiamo utilizzare il metodo head() qui:
pagine del server Java
Python3
sorted_column.head(>5>)> |
>
>
Produzione:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Possiamo farlo con qualsiasi colonna numerica del frame dati come mostrato di seguito:
Python3
newData[>'Maths'>].head()> |
>
>
Produzione:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Metodo Pandas Describe()
Supponiamo ora che i nostri dati siano per lo più numerici. Possiamo ottenere informazioni statistiche come media, massimo, minimo, ecc. sul frame di dati utilizzando il file descrivere() metodo come mostrato di seguito:
Python3
newData.describe()> |
>
>
Produzione:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Questo può anche essere fatto separatamente per tutte le colonne numeriche usando il seguente comando:
Python3
newData[>'English'>].mean()> |
>
>
Produzione:
14.3>
Anche altre informazioni statistiche possono essere calcolate utilizzando i rispettivi metodi. Come in Excel, è possibile applicare anche formule e creare colonne calcolate come segue:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
Produzione:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Dopo aver operato sui dati nel data frame, possiamo esportare nuovamente i dati in un file Excel utilizzando il metodo to_excel. Per questo, dobbiamo specificare un file Excel di output in cui scrivere i dati trasformati, come mostrato di seguito:
Python3
modello di progettazione di fabbrica
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Produzione:
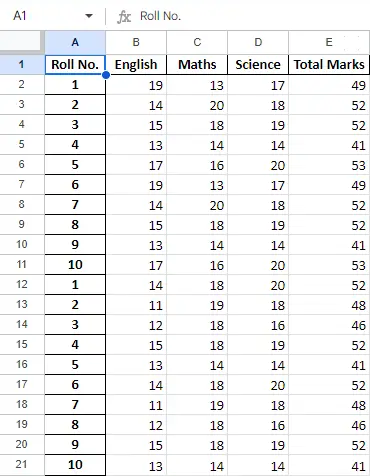
Foglio finale