Prima di esaminare le differenze tra BFS e DFS, dovremmo prima conoscere BFS e DFS separatamente.
Cos'è il BFS?
BFS sta per Prima ricerca in ampiezza . È anche noto come attraversamento dell'ordine di livello . La struttura dati Queue viene utilizzata per l'attraversamento della ricerca Breadth First. Quando utilizziamo l'algoritmo BFS per l'attraversamento in un grafico, possiamo considerare qualsiasi nodo come nodo radice.
Consideriamo il grafico seguente per l'attraversamento della prima ricerca in ampiezza.
differenza tra una tigre e un leone
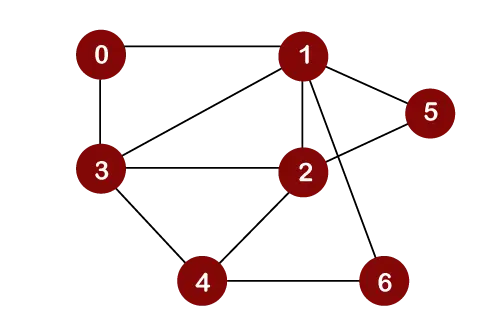
Supponiamo di considerare il nodo 0 come un nodo radice. Pertanto, l'attraversamento verrebbe avviato dal nodo 0.

Una volta rimosso il nodo 0 dalla coda, viene stampato e contrassegnato come a nodo visitato.
Una volta che il nodo 0 viene rimosso dalla coda, i nodi adiacenti del nodo 0 verranno inseriti in una coda come mostrato di seguito:

Ora il nodo 1 verrà rimosso dalla Coda; viene stampato e contrassegnato come nodo visitato
Una volta che il nodo 1 viene rimosso dalla coda, tutti i nodi adiacenti di un nodo 1 verranno aggiunti in una coda. I nodi adiacenti del nodo 1 sono 0, 3, 2, 6 e 5. Ma dobbiamo inserire solo i nodi non visitati in una coda. Poiché i nodi 3, 2, 6 e 5 non sono visitati; pertanto, questi nodi verranno aggiunti in una coda come mostrato di seguito:

Il nodo successivo è 3 in una coda. Quindi, il nodo 3 verrà rimosso dalla coda, verrà stampato e contrassegnato come visitato come mostrato di seguito:

Una volta che il nodo 3 viene rimosso dalla coda, tutti i nodi adiacenti del nodo 3 tranne i nodi visitati verranno aggiunti in una coda. I nodi adiacenti del nodo 3 sono 0, 1, 2 e 4. Poiché i nodi 0, 1 sono già visitati e il nodo 2 è presente in una coda; quindi dobbiamo inserire solo il nodo 4 in una coda.
lancia int su string

Ora, il nodo successivo nella coda è 2. Quindi, 2 verrebbe eliminato dalla coda. Viene stampato e contrassegnato come visitato come mostrato di seguito:

Una volta che il nodo 2 viene rimosso dalla coda, tutti i nodi adiacenti del nodo 2 tranne i nodi visitati verranno aggiunti in una coda. I nodi adiacenti del nodo 2 sono 1, 3, 5, 6 e 4. Poiché i nodi 1 e 3 sono già stati visitati e 4, 5, 6 sono già aggiunti nella coda; non è quindi necessario inserire alcun nodo nella Coda.
L'elemento successivo è 5. Quindi, 5 verrebbe eliminato dalla coda. Viene stampato e contrassegnato come visitato come mostrato di seguito:

Una volta che il nodo 5 viene rimosso dalla coda, tutti i nodi adiacenti del nodo 5 tranne i nodi visitati verranno aggiunti alla coda. I nodi adiacenti del nodo 5 sono 1 e 2. Poiché entrambi i nodi sono già stati visitati; pertanto non esiste alcun vertice da inserire in una coda.
Il nodo successivo è 6. Quindi, 6 verrebbe eliminato dalla coda. Viene stampato e contrassegnato come visitato come mostrato di seguito:

Una volta che il nodo 6 viene rimosso dalla coda, tutti i nodi adiacenti del nodo 6 tranne i nodi visitati verranno aggiunti alla coda. I nodi adiacenti al nodo 6 sono 1 e 4. Poiché il nodo 1 è già stato visitato e il nodo 4 è già aggiunto nella Coda; quindi non c'è nessun vertice da inserire nella Queue.
L'elemento successivo nella coda è 4. Quindi, 4 verrebbe eliminato dalla coda. Viene stampato e contrassegnato come visitato.
Una volta che il nodo 4 viene rimosso dalla coda, tutti i nodi adiacenti del nodo 4 tranne i nodi visitati verranno aggiunti alla coda. I nodi adiacenti del nodo 4 sono 3, 2 e 6. Poiché tutti i nodi adiacenti sono già stati visitati; quindi non c'è nessun vertice da inserire nella Queue.
Cos'è il DFS?
DFS sta per Ricerca prima in profondità. Nell'attraversamento DFS viene utilizzata la struttura dei dati dello stack, che funziona secondo il principio LIFO (Last In First Out). In DFS, l'attraversamento può essere avviato da qualsiasi nodo, oppure possiamo dire che qualsiasi nodo può essere considerato come nodo radice finché il nodo radice non viene menzionato nel problema.
Nel caso di BFS, l'elemento che viene eliminato dalla coda, i nodi adiacenti del nodo eliminato vengono aggiunti alla coda. Al contrario, in DFS, l'elemento che viene rimosso dallo stack, viene aggiunto allo stack solo un nodo adiacente di un nodo eliminato.
Consideriamo il grafico seguente per l'attraversamento della ricerca in profondità.
carattere in lattice di dimensioni

Considera il nodo 0 come un nodo radice.
modulazione d'ampiezza
Per prima cosa inseriamo l'elemento 0 nello stack come mostrato di seguito:

Il nodo 0 ha due nodi adiacenti, cioè 1 e 3. Ora possiamo prendere solo un nodo adiacente, 1 o 3, per l'attraversamento. Supponiamo di considerare il nodo 1; pertanto, 1 viene inserito in uno stack e viene stampato come mostrato di seguito:

Ora esamineremo i vertici adiacenti del nodo 1. I vertici adiacenti non visitati del nodo 1 sono 3, 2, 5 e 6. Possiamo considerare uno qualsiasi di questi quattro vertici. Supponiamo di prendere il nodo 3 e di inserirlo nello stack come mostrato di seguito:

Considera i vertici adiacenti non visitati del nodo 3. I vertici adiacenti non visitati del nodo 3 sono 2 e 4. Possiamo prendere uno qualsiasi dei vertici, cioè 2 o 4. Supponiamo di prendere il vertice 2 e inserirlo nello stack come mostrato di seguito:

I vertici adiacenti non visitati del nodo 2 sono 5 e 4. Possiamo scegliere uno dei vertici, cioè 5 o 4. Supponiamo di prendere il vertice 4 e inserirlo nello stack come mostrato di seguito:

Ora considereremo i vertici adiacenti non visitati del nodo 4. Il vertice adiacente non visitato del nodo 4 è il nodo 6. Pertanto, l'elemento 6 viene inserito nello stack come mostrato di seguito:

Dopo aver inserito l'elemento 6 nello stack, esamineremo i vertici adiacenti non visitati del nodo 6. Poiché non ci sono vertici adiacenti non visitati del nodo 6, quindi non possiamo spostarci oltre il nodo 6. In questo caso, eseguiremo fare marcia indietro . L'elemento più in alto, ovvero 6, verrebbe estratto dallo stack come mostrato di seguito:


L'elemento più in alto nello stack è 4. Poiché non ci sono vertici adiacenti non visitati a sinistra del nodo 4; pertanto, il nodo 4 viene estratto dallo stack come mostrato di seguito:


Il successivo elemento più in alto nello stack è 2. Ora esamineremo i vertici adiacenti non visitati del nodo 2. Poiché è rimasto solo un nodo non visitato, cioè 5, quindi il nodo 5 verrebbe inserito nello stack sopra 2 e verrà stampato come mostrato di seguito:

Ora controlleremo i vertici adiacenti del nodo 5, che non sono ancora visitati. Poiché non è rimasto alcun vertice da visitare, estraiamo l'elemento 5 dallo stack come mostrato di seguito:

Non possiamo spostarci ulteriormente di 5, quindi dobbiamo eseguire il backtracking. Nel backtracking, l'elemento più in alto verrebbe estratto dallo stack. L'elemento più in alto è 5 che verrebbe estratto dallo stack e torniamo al nodo 2 come mostrato di seguito:
allineamento del testo css

Ora controlleremo i vertici adiacenti non visitati del nodo 2. Poiché non è rimasto alcun vertice adiacente da visitare, eseguiamo il backtracking. Nel backtracking, l'elemento più in alto, ovvero il 2, verrebbe estratto dallo stack e si tornerebbe al nodo 3 come mostrato di seguito:


Ora controlleremo i vertici adiacenti non visitati del nodo 3. Poiché non è rimasto alcun vertice adiacente da visitare, eseguiamo il backtracking. Nel backtracking, l'elemento più in alto, ovvero 3, verrebbe estratto dallo stack e si tornerebbe al nodo 1 come mostrato di seguito:


Dopo aver estratto l'elemento 3, controlleremo i vertici adiacenti non visitati del nodo 1. Poiché non è rimasto alcun vertice da visitare; pertanto verrà eseguito il backtracking. Nel backtracking, l'elemento più in alto, ovvero 1, verrebbe estratto dallo stack e torneremo al nodo 0 come mostrato di seguito:


Controlleremo i vertici adiacenti del nodo 0, che non sono ancora visitati. Poiché non è rimasto alcun vertice adiacente da visitare, eseguiamo il backtracking. In questo caso, solo un elemento, ovvero 0 rimasto nello stack, verrebbe estratto dallo stack come mostrato di seguito:

Come possiamo osservare nella figura sopra, lo stack è vuoto. Quindi, dobbiamo interrompere qui l'attraversamento DFS e gli elementi stampati sono il risultato dell'attraversamento DFS.
Differenze tra BFS e DFS
Di seguito sono riportate le differenze tra BFS e DFS:
| BFS | DFS | |
|---|---|---|
| Modulo completo | BFS sta per Breadth First Search. | DFS sta per Depth First Search. |
| Tecnica | È una tecnica basata sui vertici per trovare il percorso più breve in un grafico. | È una tecnica basata sui bordi perché i vertici lungo il bordo vengono esplorati per primi dal nodo iniziale a quello finale. |
| Definizione | BFS è una tecnica di attraversamento in cui vengono prima esplorati tutti i nodi dello stesso livello e poi si passa al livello successivo. | DFS è anche una tecnica di attraversamento in cui l'attraversamento viene avviato dal nodo radice ed esplora i nodi il più lontano possibile fino a raggiungere il nodo che non ha nodi adiacenti non visitati. |
| Struttura dati | La struttura dei dati della coda viene utilizzata per l'attraversamento BFS. | La struttura dei dati dello stack viene utilizzata per l'attraversamento BFS. |
| Fare marcia indietro | BFS non utilizza il concetto di backtracking. | DFS utilizza il backtracking per attraversare tutti i nodi non visitati. |
| Numero di bordi | BFS trova il percorso più breve avente un numero minimo di archi da attraversare dall'origine al vertice di destinazione. | In DFS, è necessario un numero maggiore di bordi per attraversare dal vertice di origine al vertice di destinazione. |
| Ottimalità | L'attraversamento BFS è ottimale per quei vertici che devono essere cercati più vicini al vertice sorgente. | L'attraversamento DFS è ottimale per quei grafici in cui le soluzioni sono lontane dal vertice sorgente. |
| Velocità | BFS è più lento di DFS. | DFS è più veloce di BFS. |
| Idoneità per l'albero decisionale | Non è adatto per l'albero decisionale perché richiede prima di esplorare tutti i nodi vicini. | È adatto per l'albero decisionale. In base alla decisione si esplorano tutte le strade. Quando l'obiettivo viene trovato, interrompe la sua traversata. |
| Efficiente in termini di memoria | Non è efficiente in termini di memoria poiché richiede più memoria di DFS. | È efficiente in termini di memoria poiché richiede meno memoria di BFS. |