BERT, un acronimo per rappresentazioni di encoder bidirezionali da trasformatori , si pone come open source quadro di apprendimento automatico progettato per il regno di elaborazione del linguaggio naturale (PNL) . Nato nel 2018, questo framework è stato realizzato dai ricercatori di Google AI Language. L'articolo si propone di esplorare la architettura, funzionamento e applicazioni del BERT .
Cos'è il BERT?
BERT (Rappresentazioni di encoder bidirezionali da trasformatori) sfrutta una rete neurale basata su trasformatore per comprendere e generare un linguaggio simile a quello umano. BERT utilizza un'architettura esclusivamente codificatrice. Nell'originale Architettura del trasformatore , ci sono sia moduli codificatori che decodificatori. La decisione di utilizzare un'architettura esclusivamente codificatrice in BERT suggerisce un'enfasi primaria sulla comprensione delle sequenze di input piuttosto che sulla generazione di sequenze di output.
Approccio bidirezionale del BERT
I modelli linguistici tradizionali elaborano il testo in sequenza, da sinistra a destra o da destra a sinistra. Questo metodo limita la consapevolezza del modello al contesto immediato che precede la parola target. BERT utilizza un approccio bidirezionale considerando sia il contesto sinistro che quello destro delle parole in una frase, invece di analizzare il testo in sequenza, BERT esamina simultaneamente tutte le parole in una frase.
Esempio: La banca è situata sul _______ del fiume.
In un modello unidirezionale, la comprensione dello spazio vuoto dipenderebbe fortemente dalle parole precedenti e il modello potrebbe avere difficoltà a discernere se la banca si riferisce a un istituto finanziario o alla sponda del fiume.
BERT, essendo bidirezionale, considera contemporaneamente sia il contesto sinistro (la riva è situata sul) che quello destro (del fiume), consentendo una comprensione più sfumata. Si comprende che la parola mancante è probabilmente correlata alla posizione geografica della banca, a dimostrazione della ricchezza contestuale apportata dall’approccio bidirezionale.
Pre-formazione e messa a punto
Il modello BERT subisce un processo in due fasi:
- Pre-formazione su grandi quantità di testo senza etichetta per apprendere gli incorporamenti contestuali.
- Ottimizzazione dei dati etichettati per specifici PNL compiti.
Pre-formazione sui Large Data
- BERT è pre-addestrato su grandi quantità di dati di testo senza etichetta. Il modello apprende gli incorporamenti contestuali, che sono le rappresentazioni di parole che tengono conto del contesto circostante in una frase.
- BERT si impegna in vari compiti di pre-formazione senza supervisione. Ad esempio, potrebbe imparare a prevedere le parole mancanti in una frase (modello linguistico mascherato o attività MLM), comprendere la relazione tra due frasi o prevedere la frase successiva in una coppia.
Ottimizzazione dei dati etichettati
- Dopo la fase di pre-addestramento, il modello BERT, armato dei suoi incorporamenti contestuali, viene quindi messo a punto per compiti specifici di elaborazione del linguaggio naturale (NLP). Questo passaggio adatta il modello ad applicazioni più mirate adattando la sua comprensione del linguaggio generale alle sfumature del compito particolare.
- BERT viene messo a punto utilizzando dati etichettati specifici per le attività a valle di interesse. Queste attività potrebbero includere l'analisi del sentiment, la risposta alle domande, riconoscimento dell'entità denominata o qualsiasi altra applicazione PNL. I parametri del modello vengono adattati per ottimizzare le sue prestazioni per i requisiti particolari del compito da svolgere.
L'architettura unificata di BERT gli consente di adattarsi a varie attività a valle con modifiche minime, rendendolo uno strumento versatile e altamente efficace in comprensione del linguaggio naturale ed elaborazione.
Come funziona BERT?
BERT è progettato per generare un modello linguistico, quindi viene utilizzato solo il meccanismo del codificatore. La sequenza di token viene alimentata al codificatore Transformer. Questi token vengono prima incorporati nei vettori e poi elaborati nella rete neurale. L'output è una sequenza di vettori, ciascuno corrispondente a un token di input, che fornisce rappresentazioni contestualizzate.
Quando si addestrano modelli linguistici, definire un obiettivo di previsione è una sfida. Molti modelli prevedono la parola successiva in una sequenza, il che rappresenta un approccio direzionale e può limitare l’apprendimento del contesto. BERT affronta questa sfida con due strategie di formazione innovative:
- Modello del linguaggio mascherato (MLM)
- Previsione della frase successiva (NSP)
1. Modello del linguaggio mascherato (MLM)
Nel processo di pre-addestramento di BERT, una porzione di parole in ciascuna sequenza di input viene mascherata e il modello viene addestrato per prevedere i valori originali di queste parole mascherate in base al contesto fornito dalle parole circostanti.
In parole povere,
- Parole mascherate: Prima che BERT impari dalle frasi, nasconde alcune parole (circa il 15%) e le sostituisce con un simbolo speciale, come [MASK].
- Indovinare le parole nascoste: Il compito di BERT è capire quali sono queste parole nascoste osservando le parole che le circondano. È come un gioco in cui si indovina dove mancano alcune parole e BERT cerca di riempire gli spazi vuoti.
- Come BERT apprende:
- BERT aggiunge un livello speciale al suo sistema di apprendimento per fare queste ipotesi. Quindi controlla quanto le sue ipotesi sono vicine alle effettive parole nascoste.
- Lo fa convertendo le sue ipotesi in probabilità, dicendo: penso che questa parola sia X, e ne sono assolutamente sicuro.
- Particolare attenzione alle parole nascoste
- L’obiettivo principale di BERT durante la formazione è capire bene queste parole nascoste. Si preoccupa meno di prevedere le parole che non sono nascoste.
- Questo perché la vera sfida è capire le parti mancanti e questa strategia aiuta BERT a diventare davvero bravo a comprendere il significato e il contesto delle parole.
In termini tecnici,
- BERT aggiunge un livello di classificazione sopra l'output del codificatore. Questo livello è fondamentale per prevedere le parole mascherate.
- I vettori di output dallo strato di classificazione vengono moltiplicati per la matrice di incorporamento, trasformandoli nella dimensione del vocabolario. Questo passaggio aiuta ad allineare le rappresentazioni previste con lo spazio del vocabolario.
- La probabilità di ogni parola nel vocabolario viene calcolata utilizzando il Funzione di attivazione SoftMax . Questo passaggio genera una distribuzione di probabilità sull'intero vocabolario per ciascuna posizione mascherata.
- La funzione di perdita utilizzata durante l'addestramento considera solo la previsione dei valori mascherati. Il modello viene penalizzato per la deviazione tra le sue previsioni e i valori effettivi delle parole mascherate.
- Il modello converge più lentamente rispetto ai modelli direzionali. Questo perché, durante l'addestramento, BERT si preoccupa solo di prevedere i valori mascherati, ignorando la previsione delle parole non mascherate. La maggiore consapevolezza del contesto ottenuta attraverso questa strategia compensa la convergenza più lenta.
2. Previsione della frase successiva (NSP)
BERT prevede se la seconda frase è collegata alla prima. Questo viene fatto trasformando l'output del token [CLS] in un vettore a forma di 2×1 utilizzando un livello di classificazione e quindi calcolando la probabilità che la seconda frase segua la prima utilizzando SoftMax.
- Nel processo di formazione, BERT impara a comprendere la relazione tra coppie di frasi, prevedendo se la seconda frase segue la prima nel documento originale.
- Il 50% delle coppie di input ha la seconda frase come frase successiva nel documento originale e l'altro 50% ha una frase scelta casualmente.
- Per aiutare il modello a distinguere tra coppie di frasi connesse e disconnesse. L'input viene elaborato prima di entrare nel modello:
- Un token [CLS] viene inserito all'inizio della prima frase e un token [SEP] viene aggiunto alla fine di ciascuna frase.
- A ciascun token viene aggiunta una frase incorporata che indica la frase A o la frase B.
- Un incorporamento posizionale indica la posizione di ciascun token nella sequenza.
- BERT prevede se la seconda frase è collegata alla prima. Questo viene fatto trasformando l'output del token [CLS] in un vettore a forma di 2×1 utilizzando un livello di classificazione e quindi calcolando la probabilità che la seconda frase segua la prima utilizzando SoftMax.
Durante l'addestramento del modello BERT, il Masked LM e la previsione della frase successiva vengono addestrati insieme. Il modello mira a ridurre al minimo la funzione di perdita combinata del Masked LM e della previsione della frase successiva, portando a un modello linguistico robusto con capacità migliorate nella comprensione del contesto all'interno delle frasi e delle relazioni tra frasi.
Perché addestrare insieme Masked LM e Previsione della frase successiva?
Masked LM aiuta BERT a comprendere il contesto all'interno di una frase e Previsione della frase successiva aiuta BERT a cogliere la connessione o la relazione tra coppie di frasi. Pertanto, allenare entrambe le strategie insieme garantisce che BERT acquisisca una comprensione ampia e completa del linguaggio, catturando sia i dettagli all’interno delle frasi che il flusso tra le frasi.
Architetture BERT
L'architettura di BERT è un codificatore con trasformatore bidirezionale multistrato che è abbastanza simile al modello del trasformatore. Un'architettura del trasformatore è una rete codificatore-decodificatore che utilizza auto-attenzione lato encoder e attenzione lato decoder.
- BERTBASEha 1 2 livelli nello stack Encoder mentre BERTGRANDEha 24 livelli nello stack Encoder . Questi sono più dell'architettura Transformer descritta nel documento originale ( 6 livelli di codifica ).
- Le architetture BERT (BASE e LARGE) hanno anche reti feedforward più grandi (rispettivamente 768 e 1024 unità nascoste) e più teste di attenzione (rispettivamente 12 e 16) rispetto all'architettura Transformer suggerita nel documento originale. Contiene 512 unità nascoste e 8 teste di attenzione .
- BERTBASEcontiene 110 milioni di parametri mentre BERTGRANDEha parametri 340M.

Architettura BERT BASE e BERT LARGE.
Questo modello prende il CLS prima il token come input, poi è seguito da una sequenza di parole come input. Qui CLS è un token di classificazione. Quindi passa l'input ai livelli precedenti. Si applica ogni strato auto-attenzione e passa il risultato attraverso una rete feedforward, quindi passa al codificatore successivo. Il modello restituisce un vettore di dimensione nascosta ( 768 per BASE BERT). Se vogliamo produrre un classificatore da questo modello possiamo prendere l'output corrispondente al token CLS.
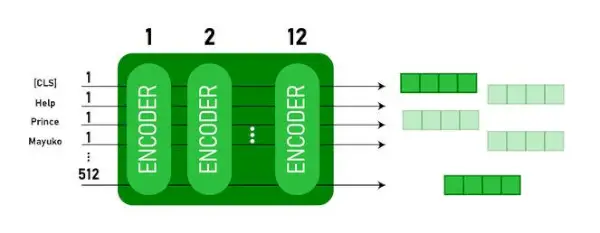
Output BERT come incorporamenti
Ora, questo vettore addestrato può essere utilizzato per eseguire una serie di attività come classificazione, traduzione, ecc. Ad esempio, il documento ottiene ottimi risultati semplicemente utilizzando un singolo livello Rete neurale sul modello BERT nel compito di classificazione.
Come utilizzare il modello BERT nella PNL?
BERT può essere utilizzato per varie attività di elaborazione del linguaggio naturale (NLP) come:
1. Compito di classificazione
- BERT può essere utilizzato per attività di classificazione come analisi del sentimento , l'obiettivo è classificare il testo in diverse categorie (positivo/ negativo/ neutro), BERT può essere utilizzato aggiungendo un livello di classificazione nella parte superiore dell'output Transformer per il token [CLS].
- Il token [CLS] rappresenta le informazioni aggregate dall'intera sequenza di input. Questa rappresentazione raggruppata può quindi essere utilizzata come input per un livello di classificazione per fare previsioni per l'attività specifica.
2. Risposta alle domande
- Nelle attività di risposta alle domande, in cui è richiesto al modello di individuare e contrassegnare la risposta all'interno di una determinata sequenza di testo, BERT può essere addestrato a questo scopo.
- BERT è addestrato a rispondere alle domande apprendendo due vettori aggiuntivi che segnano l'inizio e la fine della risposta. Durante l'addestramento, al modello vengono fornite domande e passaggi corrispondenti e impara a prevedere la posizione iniziale e finale della risposta all'interno del passaggio.
3. Riconoscimento di entità nominate (NER)
- BERT può essere utilizzato per NER, dove l'obiettivo è identificare e classificare entità (ad esempio Persona, Organizzazione, Data) in una sequenza di testo.
- Un modello NER basato su BERT viene addestrato prendendo il vettore di output di ciascun token dal Transformer e inserendolo in un livello di classificazione. Il livello prevede l'etichetta dell'entità denominata per ciascun token, indicando il tipo di entità che rappresenta.
Come tokenizzare e codificare il testo utilizzando BERT?
Per tokenizzare e codificare il testo utilizzando BERT, utilizzeremo la libreria 'transformer' in Python.
Comando per installare i trasformatori:
!pip install transformers>
- Caricheremo il tokenize BERT preaddestrato con un vocabolario in case utilizzando BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(testo) tokenizza il testo di input e lo converte in una sequenza di ID token.
- print(ID token:, codifica) stampa gli ID dei token ottenuti dopo la codifica.
- tokenizer.convert_ids_to_tokens(codifica) riconverte gli ID token nei token corrispondenti.
- print(Token:, token) stampa i token ottenuti dopo la conversione degli ID dei token
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Produzione:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> IL tokenizer.encode Il metodo aggiunge lo speciale [CLS] – classificazione E [SEP] – separatore token all'inizio e alla fine della sequenza codificata.
Applicazione del BERT
BERT è utilizzato per:
- Rappresentazione del testo: BERT viene utilizzato per generare incorporamenti di parole o rappresentazioni per le parole in una frase.
- Riconoscimento di entità denominate (NER) : BERT può essere ottimizzato per attività di riconoscimento di entità denominate, in cui l'obiettivo è identificare entità come nomi di persone, organizzazioni, luoghi, ecc., in un dato testo.
- Classificazione del testo: BERT è ampiamente utilizzato per attività di classificazione del testo, tra cui l'analisi del sentiment, il rilevamento dello spam e la categorizzazione degli argomenti. Ha dimostrato prestazioni eccellenti nella comprensione e nella classificazione del contesto dei dati testuali.
- Sistemi di risposta alle domande: BERT è stato applicato ai sistemi di risposta alle domande, dove il modello è addestrato a comprendere il contesto di una domanda e fornire risposte pertinenti. Ciò è particolarmente utile per attività come la comprensione della lettura.
- Traduzione automatica: Gli incorporamenti contestuali di BERT possono essere sfruttati per migliorare i sistemi di traduzione automatica. Il modello cattura le sfumature del linguaggio che sono cruciali per una traduzione accurata.
- Riepilogo del testo: BERT può essere utilizzato per il riepilogo di testi astratti, in cui il modello genera riepiloghi concisi e significativi di testi più lunghi comprendendo il contesto e la semantica.
- IA conversazionale: BERT è impiegato nella creazione di sistemi di intelligenza artificiale conversazionale, come chatbot, assistenti virtuali e sistemi di dialogo. La sua capacità di cogliere il contesto lo rende efficace per comprendere e generare risposte in linguaggio naturale.
- Somiglianza semantica: Gli incorporamenti BERT possono essere utilizzati per misurare la somiglianza semantica tra frasi o documenti. Ciò è utile in attività come il rilevamento di duplicati, l'identificazione di parafrasi e il recupero di informazioni.
BERT contro GPT
La differenza tra BERT e GPT è la seguente:
| BERT | GPT | |
|---|---|---|
| Architettura | BERT è progettato per l'apprendimento della rappresentazione bidirezionale. Utilizza un obiettivo del modello linguistico mascherato, in cui prevede le parole mancanti in una frase in base al contesto sia sinistro che destro. | GPT, d'altra parte, è progettato per la modellazione del linguaggio generativo. Prevede la parola successiva in una frase dato il contesto precedente, utilizzando un approccio autoregressivo unidirezionale. |
| Obiettivi pre-formativi | BERT è pre-addestrato utilizzando un obiettivo del modello linguistico mascherato e la previsione della frase successiva. Si concentra sull'acquisizione del contesto bidirezionale e sulla comprensione delle relazioni tra le parole in una frase. | GPT è pre-addestrato per prevedere la parola successiva in una frase, il che incoraggia il modello ad apprendere una rappresentazione coerente del linguaggio e a generare sequenze contestualmente rilevanti. |
| Comprensione del contesto | BERT è efficace per attività che richiedono una profonda comprensione del contesto e delle relazioni all'interno di una frase, come la classificazione del testo, il riconoscimento di entità denominate e la risposta alle domande. | GPT è efficace nel generare testo coerente e contestualmente pertinente. Viene spesso utilizzato in compiti creativi, sistemi di dialogo e compiti che richiedono la generazione di sequenze di linguaggio naturale. |
| Tipi di attività e casi d'uso
| Comunemente utilizzato in attività come la classificazione del testo, il riconoscimento di entità denominate, l'analisi del sentiment e la risposta alle domande. | Applicato a compiti quali la generazione di testo, i sistemi di dialogo, il riepilogo e la scrittura creativa. |
| Ottimizzazione vs apprendimento con pochi colpi | BERT è spesso messo a punto su specifiche attività a valle con dati etichettati per adattare le sue rappresentazioni pre-addestrate all'attività da svolgere. | GPT è progettato per eseguire l'apprendimento 'low-shot', in cui può generalizzare a nuove attività con dati di addestramento minimi specifici per attività. |
Controlla anche:
- Classificazione del sentiment utilizzando BERT
- Come generare l'incorporamento di parole utilizzando BERT?
- Modello BART per il completamento automatico del testo in PNL
- Classificazione dei commenti tossici utilizzando BERT
- Predizione della frase successiva utilizzando BERT
Domande frequenti (FAQ)
D. A cosa serve BERT?
BERT viene utilizzato per eseguire attività di PNL come la rappresentazione del testo, il riconoscimento delle entità denominate, la classificazione del testo, i sistemi di domande e risposte, la traduzione automatica, il riepilogo del testo e altro ancora.
D. Quali sono i vantaggi del modello BERT?
Il modello linguistico BERT si distingue per la sua ampia pre-formazione in più lingue, offrendo un'ampia copertura linguistica rispetto ad altri modelli. Ciò rende BERT particolarmente vantaggioso per progetti non basati sull’inglese, poiché fornisce solide rappresentazioni contestuali e comprensione semantica in una vasta gamma di lingue, migliorando la sua versatilità nelle applicazioni multilingue.
D. Come funziona BERT per l'analisi del sentiment?
BERT eccelle nell'analisi dei sentimenti sfruttando la sua rappresentazione bidirezionale e imparando a catturare sfumature contestuali, significati semantici e strutture sintattiche all'interno di un dato testo. Ciò consente a BERT di comprendere il sentimento espresso in una frase considerando le relazioni tra le parole, ottenendo risultati di analisi del sentimento altamente efficaci.
migliorato per il loop Java
D. Google è basato su BERT?
BERT E RankBrain sono componenti dell'algoritmo di ricerca di Google per elaborare query e contenuti delle pagine web per ottenere una migliore comprensione e migliorare i risultati di ricerca.