Le reti neurali sono modelli computazionali che imitano le complesse funzioni del cervello umano. Le reti neurali sono costituite da nodi o neuroni interconnessi che elaborano e apprendono dai dati, consentendo attività come il riconoscimento di modelli e il processo decisionale nell’apprendimento automatico. L'articolo esplora di più sulle reti neurali, sul loro funzionamento, sull'architettura e altro ancora.
Tabella dei contenuti
- Evoluzione delle reti neurali
- Cosa sono le reti neurali?
- Come funzionano le reti neurali?
- Apprendimento di una rete neurale
- Tipi di reti neurali
- Semplice implementazione di una rete neurale
Evoluzione delle reti neurali
A partire dagli anni ’40 ci sono stati numerosi progressi degni di nota nel campo delle reti neurali:
- Anni Quaranta - Cinquanta: primi concetti
Le reti neurali iniziarono con l'introduzione del primo modello matematico di neuroni artificiali da parte di McCulloch e Pitts. Ma i vincoli computazionali hanno reso difficile il progresso.
- Anni '60 -'70: Percettroni
Questa era è definita dal lavoro di Rosenblatt sui percettroni. Percettroni sono reti a strato singolo la cui applicabilità era limitata a problemi che potevano essere risolti linearmente separatamente.
- Anni '80: retropropagazione e connessionismo
Rete multistrato l’addestramento è stato reso possibile dall’invenzione del metodo di backpropagation da parte di Rumelhart, Hinton e Williams. Con la sua enfasi sull’apprendimento attraverso nodi interconnessi, il connessionismo ha guadagnato fascino.
- Anni '90: boom e inverno
Con applicazioni nell’identificazione delle immagini, nella finanza e in altri campi, le reti neurali hanno visto un boom. La ricerca sulle reti neurali, tuttavia, ha vissuto un inverno a causa dei costi computazionali esorbitanti e delle aspettative gonfiate.
- Anni 2000: rinascita e deep learning
Set di dati più grandi, strutture innovative e capacità di elaborazione migliorate hanno stimolato il ritorno. Apprendimento approfondito ha dimostrato un'efficacia straordinaria in numerose discipline utilizzando numerosi livelli.
- Anni 2010-presente: dominanza del deep learning
Le reti neurali convoluzionali (CNN) e le reti neurali ricorrenti (RNN), due architetture di deep learning, hanno dominato l’apprendimento automatico. Il loro potere è stato dimostrato dalle innovazioni nei giochi, nel riconoscimento delle immagini e nell’elaborazione del linguaggio naturale.
Cosa sono le reti neurali?
Reti neurali estrarre caratteristiche identificative dai dati, mancando di comprensione pre-programmata. I componenti della rete includono neuroni, connessioni, pesi, bias, funzioni di propagazione e una regola di apprendimento. I neuroni ricevono input, governati da soglie e funzioni di attivazione. Le connessioni implicano pesi e pregiudizi che regolano il trasferimento delle informazioni. L’apprendimento, aggiustando pesi e pregiudizi, avviene in tre fasi: calcolo degli input, generazione di output e perfezionamento iterativo che migliora la competenza della rete in diversi compiti.
Questi includono:
- La rete neurale viene simulata da un nuovo ambiente.
- Quindi come risultato di questa simulazione vengono modificati i parametri liberi della rete neurale.
- La rete neurale risponde quindi in un modo nuovo all'ambiente a causa dei cambiamenti nei suoi parametri liberi.
Importanza delle reti neurali
La capacità delle reti neurali di identificare modelli, risolvere enigmi complessi e adattarsi ai cambiamenti dell’ambiente circostante è essenziale. La loro capacità di apprendere dai dati ha effetti di vasta portata, che vanno dalla rivoluzione tecnologica elaborazione del linguaggio naturale e automobili a guida autonoma per automatizzare i processi decisionali e aumentare l’efficienza in numerosi settori. Lo sviluppo dell’intelligenza artificiale dipende in gran parte dalle reti neurali, che guidano anche l’innovazione e influenzano la direzione della tecnologia.
Come funzionano le reti neurali?
Capiamo con un esempio come funziona una rete neurale:
Considera una rete neurale per la classificazione delle email. Il livello di input accetta funzionalità come contenuto dell'e-mail, informazioni sul mittente e oggetto. Questi input, moltiplicati per i pesi adeguati, passano attraverso strati nascosti. La rete, attraverso la formazione, impara a riconoscere modelli che indicano se un'e-mail è spam o meno. Il livello di output, con una funzione di attivazione binaria, prevede se l'e-mail è spam (1) o meno (0). Man mano che la rete perfeziona iterativamente i suoi pesi attraverso la backpropagation, diventa esperta nel distinguere tra spam ed e-mail legittime, dimostrando la praticità delle reti neurali in applicazioni del mondo reale come il filtraggio della posta elettronica.
Funzionamento di una rete neurale
Le reti neurali sono sistemi complessi che imitano alcune caratteristiche del funzionamento del cervello umano. È composto da uno strato di input, uno o più strati nascosti e uno strato di output costituito da strati di neuroni artificiali accoppiati. Le due fasi del processo di base sono chiamate backpropagation e propagazione in avanti .
Propagazione in avanti
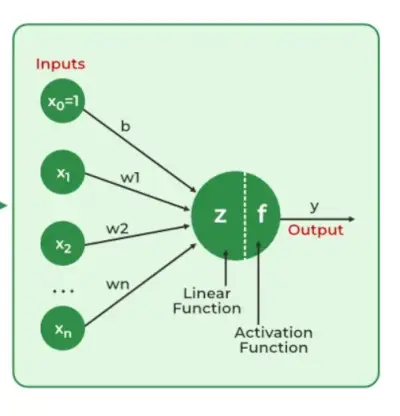
- Livello di input: Ogni caratteristica nel livello di input è rappresentata da un nodo sulla rete, che riceve i dati di input.
- Pesi e Connessioni: Il peso di ciascuna connessione neuronale indica quanto è forte la connessione. Durante l'allenamento, questi pesi vengono modificati.
- Livelli nascosti: Ogni neurone dello strato nascosto elabora gli input moltiplicandoli per pesi, sommandoli e quindi facendoli passare attraverso una funzione di attivazione. In questo modo viene introdotta la non linearità, consentendo alla rete di riconoscere modelli complessi.
- Produzione: Il risultato finale viene prodotto ripetendo il processo fino al raggiungimento dello strato di output.
Propagazione all'indietro
- Calcolo delle perdite: L’output della rete viene valutato rispetto ai valori obiettivo reali e viene utilizzata una funzione di perdita per calcolare la differenza. Per un problema di regressione, il Errore quadratico medio (MSE) è comunemente utilizzata come funzione di costo.
Funzione di perdita:
- Discesa gradiente: La discesa del gradiente viene quindi utilizzata dalla rete per ridurre la perdita. Per ridurre l'imprecisione, i pesi vengono modificati in base alla derivata della perdita rispetto a ciascun peso.
- Regolazione dei pesi: I pesi vengono adeguati ad ogni connessione applicando questo processo iterativo, o propagazione all'indietro , all'indietro attraverso la rete.
- Formazione: Durante l'addestramento con diversi campioni di dati, l'intero processo di propagazione in avanti, calcolo delle perdite e propagazione all'indietro viene eseguito in modo iterativo, consentendo alla rete di adattarsi e apprendere modelli dai dati.
- Funzioni di attivazione: La non linearità del modello è introdotta da funzioni di attivazione come unità lineare rettificata (ReLU) ore sigmoideo . La loro decisione se attivare un neurone si basa sull’intero input ponderato.

Apprendimento di una rete neurale
1. Apprendimento con apprendimento supervisionato
In apprendimento supervisionato , la rete neurale è guidata da un insegnante che ha accesso ad entrambe le coppie input-output. La rete crea output in base agli input senza tenere conto dell'ambiente circostante. Confrontando questi risultati con i risultati desiderati noti all'insegnante, viene generato un segnale di errore. Per ridurre gli errori, i parametri della rete vengono modificati in modo iterativo e si interrompono quando le prestazioni raggiungono un livello accettabile.
2. Apprendimento con apprendimento non supervisionato
Le variabili di output equivalenti sono assenti in apprendimento non supervisionato . Il suo obiettivo principale è comprendere la struttura sottostante dei dati in entrata (X). Nessun istruttore è presente per offrire consigli. La modellazione dei modelli e delle relazioni dei dati è invece il risultato previsto. Parole come regressione e classificazione sono legate all'apprendimento supervisionato, mentre l'apprendimento non supervisionato è associato al clustering e all'associazione.
3. Apprendimento con l'apprendimento per rinforzo
Attraverso l’interazione con l’ambiente e il feedback sotto forma di premi o penalità, la rete acquisisce conoscenza. Trovare una politica o una strategia che ottimizzi i premi cumulativi nel tempo è l’obiettivo della rete. Questo tipo è spesso utilizzato nelle applicazioni di gioco e decisionali.
proposizione logica
Tipi di reti neurali
Ci sono Sette tipi di reti neurali utilizzabili.
- Reti feedforward: UN rete neurale feedforward è una semplice architettura di rete neurale artificiale in cui i dati si muovono dall'input all'output in un'unica direzione. Ha livelli di input, nascosti e di output; i circuiti di feedback sono assenti. La sua architettura semplice lo rende adatto a numerose applicazioni, come la regressione e il riconoscimento di pattern.
- Perceptron multistrato (MLP): MLP è un tipo di rete neurale feedforward con tre o più strati, incluso uno strato di input, uno o più strati nascosti e uno strato di output. Utilizza funzioni di attivazione non lineari.
- Rete Neurale Convoluzionale (CNN): UN Rete neurale convoluzionale (CNN) è una rete neurale artificiale specializzata progettata per l'elaborazione delle immagini. Impiega livelli convoluzionali per apprendere automaticamente le caratteristiche gerarchiche dalle immagini di input, consentendo un riconoscimento e una classificazione efficaci delle immagini. Le CNN hanno rivoluzionato la visione artificiale e sono fondamentali in attività come il rilevamento di oggetti e l'analisi delle immagini.
- Rete neurale ricorrente (RNN): Un tipo di rete neurale artificiale destinata all'elaborazione sequenziale dei dati è chiamata a Rete neurale ricorrente (RNN). È appropriato per applicazioni in cui le dipendenze contestuali sono critiche, come la previsione di serie temporali e l'elaborazione del linguaggio naturale, poiché utilizza cicli di feedback che consentono alle informazioni di sopravvivere all'interno della rete.
- Memoria a breve termine (LSTM): LSTM è un tipo di RNN progettato per superare il problema del gradiente evanescente nell'addestramento delle RNN. Utilizza celle e porte di memoria per leggere, scrivere e cancellare selettivamente le informazioni.
Semplice implementazione di una rete neurale
Python3
import> numpy as np> # array of any amount of numbers. n = m> X>=> np.array([[>1>,>2>,>3>],> >[>3>,>4>,>1>],> >[>2>,>5>,>3>]])> # multiplication> y>=> np.array([[.>5>, .>3>, .>2>]])> # transpose of y> y>=> y.T> # sigma value> sigm>=> 2> # find the delta> delt>=> np.random.random((>3>,>3>))>-> 1> for> j>in> range>(>100>):> > ># find matrix 1. 100 layers.> >m1>=> (y>-> (>1>/>(>1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt))))))>*>((>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))>*>(>1>->(>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))))> ># find matrix 2> >m2>=> m1.dot(delt.T)>*> ((>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> >*> (>1>->(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))))> ># find delta> >delt>=> delt>+> (>1>/>(>1> +> np.exp(>->(np.dot(X, sigm))))).T.dot(m1)> ># find sigma> >sigm>=> sigm>+> (X.T.dot(m2))> # print output from the matrix> print>(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> |
>
>
Produzione:
[[0.99999325 0.99999375 0.99999352] [0.99999988 0.99999989 0.99999988] [1. 1. 1. ]]>
Vantaggi delle reti neurali
Le reti neurali sono ampiamente utilizzate in molte applicazioni diverse a causa dei loro numerosi vantaggi:
- Adattabilità: Le reti neurali sono utili per attività in cui il collegamento tra input e output è complesso o non ben definito perché possono adattarsi a nuove situazioni e imparare dai dati.
- Riconoscimento dei modelli: La loro competenza nel riconoscimento dei modelli li rende efficaci in compiti come l'identificazione di audio e immagini, l'elaborazione del linguaggio naturale e altri complessi modelli di dati.
- Elaborazione parallela: Poiché le reti neurali sono per natura capaci di elaborazione parallela, possono elaborare numerosi lavori contemporaneamente, il che accelera e migliora l’efficienza dei calcoli.
- Non linearità: Le reti neurali sono in grado di modellare e comprendere relazioni complicate nei dati in virtù delle funzioni di attivazione non lineare presenti nei neuroni, che superano gli inconvenienti dei modelli lineari.
Svantaggi delle reti neurali
Le reti neurali, sebbene potenti, non sono prive di inconvenienti e difficoltà:
- Intensità computazionale: L’addestramento di reti neurali di grandi dimensioni può essere un processo laborioso ed impegnativo dal punto di vista computazionale che richiede molta potenza di calcolo.
- Natura della scatola nera: In quanto modelli a scatola nera, le reti neurali rappresentano un problema in importanti applicazioni poiché è difficile capire come prendono le decisioni.
- Adattamento eccessivo: L’overfitting è un fenomeno in cui le reti neurali affidano il materiale didattico alla memoria anziché identificare modelli nei dati. Sebbene gli approcci di regolarizzazione contribuiscano ad alleviare questo problema, il problema esiste ancora.
- Necessità di set di dati di grandi dimensioni: Per un addestramento efficiente, le reti neurali necessitano spesso di set di dati etichettati e considerevoli; in caso contrario, le loro prestazioni potrebbero risentire di dati incompleti o distorti.
Domande frequenti (FAQ)
1. Cos'è una rete neurale?
Una rete neurale è un sistema artificiale costituito da nodi interconnessi (neuroni) che elaborano informazioni, modellato sulla struttura del cervello umano. Viene impiegato in lavori di machine learning in cui i modelli vengono estratti dai dati.
2. Come funziona una rete neurale?
Strati di neuroni connessi elaborano i dati nelle reti neurali. La rete elabora i dati di input, modifica i pesi durante l'addestramento e produce un output in base ai modelli scoperti.
3. Quali sono i tipi comuni di architetture di rete neurale?
Le reti neurali feedforward, le reti neurali ricorrenti (RNN), le reti neurali convoluzionali (CNN) e le reti di memoria a breve termine (LSTM) sono esempi di architetture comuni progettate ciascuna per un determinato compito.
4. Qual è la differenza tra apprendimento supervisionato e non supervisionato nelle reti neurali?
Nell'apprendimento supervisionato, i dati etichettati vengono utilizzati per addestrare una rete neurale in modo che possa imparare a mappare gli input sugli output corrispondenti. L'apprendimento non supervisionato funziona con dati senza etichetta e cerca strutture o modelli nei dati .
5. In che modo le reti neurali gestiscono i dati sequenziali?
I circuiti di feedback incorporati nelle reti neurali ricorrenti (RNN) consentono loro di elaborare dati sequenziali e, nel tempo, acquisire dipendenze e contesto.