L'architettura seguente spiega il flusso di invio della query in Hive.
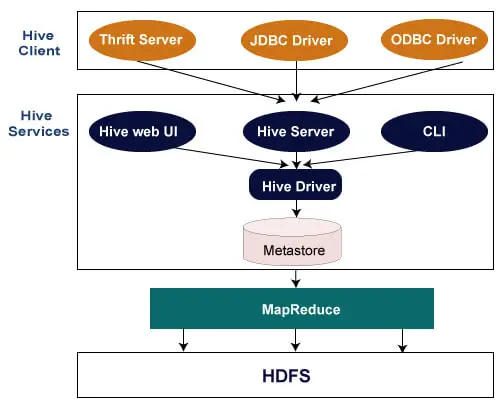
Cliente Alveare
Hive consente di scrivere applicazioni in vari linguaggi, tra cui Java, Python e C++. Supporta diversi tipi di client come: -
- Thrift Server: è una piattaforma di fornitore di servizi multilingue che soddisfa la richiesta di tutti quei linguaggi di programmazione che supportano Thrift.
- Driver JDBC: viene utilizzato per stabilire una connessione tra hive e le applicazioni Java. Il driver JDBC è presente nella classe org.apache.hadoop.hive.jdbc.HiveDriver.
- Driver ODBC: consente alle applicazioni che supportano il protocollo ODBC di connettersi a Hive.
Servizi dell'alveare
Di seguito sono riportati i servizi forniti da Hive: -
- Hive CLI - La Hive CLI (Command Line Interface) è una shell in cui possiamo eseguire query e comandi Hive.
- Interfaccia utente Web Hive: l'interfaccia utente Web Hive è solo un'alternativa alla CLI Hive. Fornisce una GUI basata sul Web per l'esecuzione di query e comandi Hive.
- Hive MetaStore - È un repository centrale che memorizza tutte le informazioni sulla struttura di varie tabelle e partizioni nel magazzino. Include anche i metadati della colonna e le informazioni sul tipo, i serializzatori e i deserializzatori utilizzati per leggere e scrivere i dati e i file HDFS corrispondenti in cui sono archiviati i dati.
- Hive Server: viene chiamato Apache Thrift Server. Accetta la richiesta da diversi client e la fornisce a Hive Driver.
- Hive Driver: riceve query da diverse fonti come interfaccia utente Web, CLI, Thrift e driver JDBC/ODBC. Trasferisce le query al compilatore.
- Compilatore Hive: lo scopo del compilatore è analizzare la query ed eseguire analisi semantiche sui diversi blocchi ed espressioni di query. Converte le istruzioni HiveQL in lavori MapReduce.
- Motore di esecuzione Hive: l'ottimizzatore genera il piano logico sotto forma di DAG di attività di riduzione della mappa e attività HDFS. Alla fine, il motore di esecuzione esegue le attività in arrivo nell'ordine delle loro dipendenze.