Nel mondo reale apprendimento automatico applicazioni, è comune avere molte caratteristiche rilevanti, ma solo un sottoinsieme di esse può essere osservabile. Quando si ha a che fare con variabili che a volte sono osservabili e a volte no, è infatti possibile utilizzare i casi in cui tale variabile è visibile o osservata per apprendere e fare previsioni per i casi in cui non è osservabile. Questo approccio viene spesso definito gestione dei dati mancanti. Utilizzando le istanze disponibili in cui la variabile è osservabile, gli algoritmi di apprendimento automatico possono apprendere modelli e relazioni dai dati osservati. Questi modelli appresi possono quindi essere utilizzati per prevedere i valori della variabile nei casi in cui manca o non è osservabile.
L'algoritmo di massimizzazione delle aspettative può essere utilizzato per gestire situazioni in cui le variabili sono parzialmente osservabili. Quando determinate variabili sono osservabili, possiamo utilizzare tali istanze per apprendere e stimare i loro valori. Quindi, possiamo prevedere i valori di queste variabili nei casi in cui non sono osservabili.
L'algoritmo EM è stato proposto e nominato in un articolo fondamentale pubblicato nel 1977 da Arthur Dempster, Nan Laird e Donald Rubin. Il loro lavoro ha formalizzato l'algoritmo e ne ha dimostrato l'utilità nella modellazione e nella stima statistica.
L'algoritmo EM è applicabile alle variabili latenti, che sono variabili che non sono direttamente osservabili ma sono dedotte dai valori di altre variabili osservate. Sfruttando la forma generale conosciuta della distribuzione di probabilità che governa queste variabili latenti, l’algoritmo EM può prevederne i valori.
L'algoritmo EM funge da base per molti algoritmi di clustering non supervisionati nel campo dell'apprendimento automatico. Fornisce un quadro per trovare i parametri di massima verosimiglianza locale di un modello statistico e dedurre variabili latenti nei casi in cui i dati mancano o sono incompleti.
Algoritmo di massimizzazione delle aspettative (EM).
L'algoritmo Expectation-Maximization (EM) è un metodo di ottimizzazione iterativo che combina diversi metodi non supervisionati apprendimento automatico algoritmi per trovare la massima verosimiglianza o la massima stima a posteriori di parametri in modelli statistici che coinvolgono variabili latenti non osservate. L'algoritmo EM è comunemente utilizzato per i modelli a variabili latenti e può gestire i dati mancanti. Consiste in una fase di stima (E-step) e una fase di massimizzazione (M-step), formando un processo iterativo per migliorare l'adattamento del modello.
- Nella fase E, l'algoritmo calcola le variabili latenti, ovvero l'aspettativa della log-verosimiglianza utilizzando le stime dei parametri correnti.
- Nella fase M, l'algoritmo determina i parametri che massimizzano la log-verosimiglianza attesa ottenuta nella fase E, e i parametri del modello corrispondenti vengono aggiornati in base alle variabili latenti stimate.

Massimizzazione delle aspettative nell'algoritmo EM
Ripetendo iterativamente questi passaggi, l'algoritmo EM cerca di massimizzare la verosimiglianza dei dati osservati. Viene comunemente utilizzato per attività di apprendimento non supervisionato, come il clustering, in cui vengono dedotte variabili latenti e ha applicazioni in vari campi, tra cui l'apprendimento automatico, la visione artificiale e l'elaborazione del linguaggio naturale.
Termini chiave nell'algoritmo di massimizzazione delle aspettative (EM).
Alcuni dei termini chiave più comunemente usati nell’algoritmo di massimizzazione delle aspettative (EM) sono i seguenti:
- Variabili latenti: le variabili latenti sono variabili non osservate nei modelli statistici che possono essere dedotte solo indirettamente attraverso i loro effetti su variabili osservabili. Non possono essere misurati direttamente ma possono essere rilevati dal loro impatto sulle variabili osservabili. Probabilità: è la probabilità di osservare i dati forniti dati i parametri del modello. Nell'algoritmo EM, l'obiettivo è trovare i parametri che massimizzano la probabilità. Log-Likelihood: è il logaritmo della funzione di verosimiglianza, che misura la bontà dell'adattamento tra i dati osservati e il modello. L'algoritmo EM cerca di massimizzare la probabilità logaritmica. Stima della massima verosimiglianza (MLE): MLE è un metodo per stimare i parametri di un modello statistico trovando i valori dei parametri che massimizzano la funzione di verosimiglianza, che misura quanto bene il modello spiega i dati osservati. Probabilità posteriore: nel contesto dell'inferenza bayesiana, l'algoritmo EM può essere esteso per stimare le stime massime a posteriori (MAP), dove la probabilità a posteriori dei parametri viene calcolata in base alla distribuzione a priori e alla funzione di verosimiglianza. Passaggio delle aspettative (E): il passaggio E dell'algoritmo EM calcola il valore atteso o la probabilità a posteriori delle variabili latenti dati i dati osservati e le stime dei parametri attuali. Implica il calcolo delle probabilità di ciascuna variabile latente per ciascun punto dati. Fase di massimizzazione (M): la fase M dell'algoritmo EM aggiorna le stime dei parametri massimizzando la log-verosimiglianza attesa ottenuta dalla fase E. Si tratta di trovare i valori dei parametri che ottimizzano la funzione di verosimiglianza, tipicamente attraverso metodi di ottimizzazione numerica. Convergenza: La convergenza si riferisce alla condizione in cui l'algoritmo EM ha raggiunto una soluzione stabile. In genere viene determinato controllando se la variazione della probabilità logaritmica o delle stime dei parametri scende al di sotto di una soglia predefinita.
Come funziona l'algoritmo di massimizzazione delle aspettative (EM):
L'essenza dell'algoritmo di massimizzazione delle aspettative è utilizzare i dati osservati disponibili del set di dati per stimare i dati mancanti e quindi utilizzare tali dati per aggiornare i valori dei parametri. Cerchiamo di comprendere l'algoritmo EM in dettaglio.
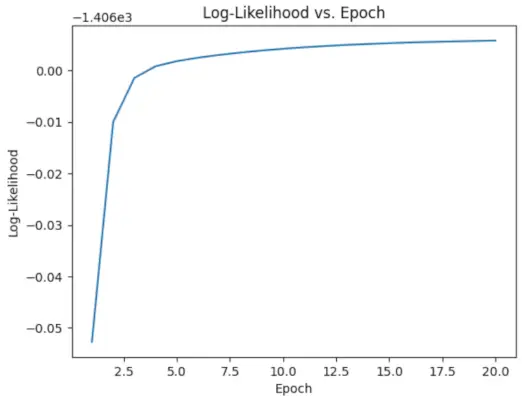
Diagramma di flusso dell'algoritmo EM
- Inizializzazione:
- Inizialmente, viene considerato un insieme di valori iniziali dei parametri. Una serie di dati osservati incompleti viene fornita al sistema presupponendo che i dati osservati provengano da un modello specifico.
- Calcolare la probabilità a posteriori o la responsabilità di ciascuna variabile latente dati i dati osservati e le stime dei parametri attuali.
- Stimare i valori dei dati mancanti o incompleti utilizzando le stime dei parametri correnti.
- Calcolare la probabilità logaritmica dei dati osservati in base alle stime dei parametri attuali e ai dati mancanti stimati.
- Aggiornare i parametri del modello massimizzando la probabilità di registrazione completa dei dati prevista ottenuta dall'E-step.
- Ciò in genere comporta la risoluzione di problemi di ottimizzazione per trovare i valori dei parametri che massimizzano la probabilità logaritmica.
- La tecnica di ottimizzazione specifica utilizzata dipende dalla natura del problema e dal modello utilizzato.
- Verificare la convergenza confrontando la variazione della probabilità logaritmica o i valori dei parametri tra le iterazioni.
- Se la variazione è inferiore a una soglia predefinita, fermarsi e considerare l'algoritmo convergente.
- Altrimenti, torna alla fase E e ripeti il processo finché non viene raggiunta la convergenza.
Implementazione passo dopo passo dell'algoritmo di massimizzazione delle aspettative
Importa le librerie necessarie
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> scipy.stats>import> norm> |
>
>
Genera un set di dati con due componenti gaussiani
Python3
# Generate a dataset with two Gaussian components> mu1, sigma1>=> 2>,>1> mu2, sigma2>=> ->1>,>0.8> X1>=> np.random.normal(mu1, sigma1, size>=>200>)> X2>=> np.random.normal(mu2, sigma2, size>=>600>)> X>=> np.concatenate([X1, X2])> # Plot the density estimation using seaborn> sns.kdeplot(X)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.show()> |
>
>
Produzione :
Grafico della densità
Inizializzare i parametri
Python3
# Initialize parameters> mu1_hat, sigma1_hat>=> np.mean(X1), np.std(X1)> mu2_hat, sigma2_hat>=> np.mean(X2), np.std(X2)> pi1_hat, pi2_hat>=> len>(X1)>/> len>(X),>len>(X2)>/> len>(X)> |
>
>
Eseguire l'algoritmo EM
- Itera per il numero di epoche specificato (20 in questo caso).
- In ciascuna epoca, l'E-step calcola le responsabilità (valori gamma) valutando le densità di probabilità gaussiane per ciascun componente e ponderandole in base alle proporzioni corrispondenti.
- Il passo M aggiorna i parametri calcolando la media ponderata e la deviazione standard per ciascun componente
Python3
vantaggi dell'elettricità
# Perform EM algorithm for 20 epochs> num_epochs>=> 20> log_likelihoods>=> []> for> epoch>in> range>(num_epochs):> ># E-step: Compute responsibilities> >gamma1>=> pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >gamma2>=> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)> >total>=> gamma1>+> gamma2> >gamma1>/>=> total> >gamma2>/>=> total> > ># M-step: Update parameters> >mu1_hat>=> np.>sum>(gamma1>*> X)>/> np.>sum>(gamma1)> >mu2_hat>=> np.>sum>(gamma2>*> X)>/> np.>sum>(gamma2)> >sigma1_hat>=> np.sqrt(np.>sum>(gamma1>*> (X>-> mu1_hat)>*>*>2>)>/> np.>sum>(gamma1))> >sigma2_hat>=> np.sqrt(np.>sum>(gamma2>*> (X>-> mu2_hat)>*>*>2>)>/> np.>sum>(gamma2))> >pi1_hat>=> np.mean(gamma1)> >pi2_hat>=> np.mean(gamma2)> > ># Compute log-likelihood> >log_likelihood>=> np.>sum>(np.log(pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >+> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)))> >log_likelihoods.append(log_likelihood)> # Plot log-likelihood values over epochs> plt.plot(>range>(>1>, num_epochs>+>1>), log_likelihoods)> plt.xlabel(>'Epoch'>)> plt.ylabel(>'Log-Likelihood'>)> plt.title(>'Log-Likelihood vs. Epoch'>)> plt.show()> |
>
>
Produzione :
Epoca vs verosimiglianza
Tracciare la densità finale stimata
Python3
# Plot the final estimated density> X_sorted>=> np.sort(X)> density_estimation>=> pi1_hat>*>norm.pdf(X_sorted,> >mu1_hat,> >sigma1_hat)>+> pi2_hat>*> norm.pdf(X_sorted,> >mu2_hat,> >sigma2_hat)> plt.plot(X_sorted, gaussian_kde(X_sorted)(X_sorted), color>=>'green'>, linewidth>=>2>)> plt.plot(X_sorted, density_estimation, color>=>'red'>, linewidth>=>2>)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.legend([>'Kernel Density Estimation'>,>'Mixture Density'>])> plt.show()> |
>
>
Produzione :
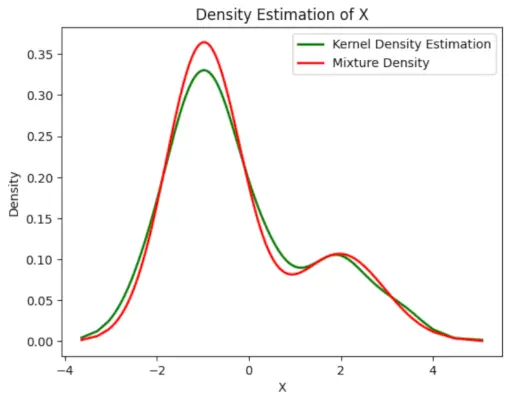
Densità stimata
Applicazioni del Algoritmo EM
- Può essere utilizzato per inserire i dati mancanti in un campione.
- Può essere utilizzato come base per l'apprendimento non supervisionato dei cluster.
- Può essere utilizzato allo scopo di stimare i parametri del modello Hidden Markov (HMM).
- Può essere utilizzato per scoprire i valori delle variabili latenti.
Vantaggi dell'algoritmo EM
- È sempre garantito che la probabilità aumenterà ad ogni iterazione.
- L'E-step e l'M-step sono spesso piuttosto semplici per molti problemi in termini di implementazione.
- Le soluzioni ai passaggi M spesso esistono in forma chiusa.
Svantaggi dell'algoritmo EM
- Ha una convergenza lenta.
- Converge solo all'ottimo locale.
- Richiede entrambe le probabilità, in avanti e all'indietro (l'ottimizzazione numerica richiede solo la probabilità in avanti).