Pandas.apply consente agli utenti di passare una funzione e applicarla su ogni singolo valore della serie Pandas. Si tratta di un enorme miglioramento per la libreria panda poiché questa funzione aiuta a separare i dati in base alle condizioni richieste, grazie alle quali vengono utilizzati in modo efficiente nella scienza dei dati e nell'apprendimento automatico.
Installazione:
Importa il modulo Pandas nel file Python utilizzando i seguenti comandi sul terminale:
pip install pandas>
Per leggere il file CSV e comprimerlo in una serie di panda vengono utilizzati i seguenti comandi:
import pandas as pd s = pd.read_csv('stock.csv', squeeze=True)> Sintassi:
s.apply(func, convert_dtype=True, args=())>
parametri:
funzione: .apply prende una funzione e la applica a tutti i valori delle serie panda. convert_dtipo: Converti dtype secondo l'operazione della funzione. argomenti=(): Argomenti aggiuntivi da passare alla funzione anziché alla serie. Tipo di reso: Serie Panda dopo la funzione/operazione applicata.
Esempio 1:
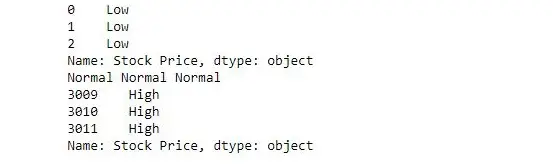
L'esempio seguente passa una funzione e controlla il valore di ciascun elemento in serie e restituisce di conseguenza basso, normale o alto.
PITONE3
import> pandas as pd> # reading csv> s>=> pd.read_csv('stock.csv', squeeze>=> True>)> # defining function to check price> def> fun(num):> >if> num<>200>:> >return> 'Low'> >elif> num>>=> 200> and> num<>400>:> >return> 'Normal'> >else>:> >return> 'High'> # passing function to apply and storing returned series in new> new>=> s.>apply>(fun)> # printing first 3 element> print>(new.head(>3>))> # printing elements somewhere near the middle of series> print>(new[>1400>], new[>1500>], new[>1600>])> # printing last 3 elements> print>(new.tail(>3>))> |
quando è uscito windows 7?
>
>
Produzione:
Esempio n.2:
Nell'esempio seguente, viene creata una funzione anonima temporanea in .apply utilizzando lambda. Aggiunge 5 a ciascun valore in serie e restituisce una nuova serie.
PITONE3
import> pandas as pd> s>=> pd.read_csv('stock.csv', squeeze>=> True>)> # adding 5 to each value> new>=> s.>apply>(>lambda> num : num>+> 5>)> # printing first 5 elements of old and new series> print>(s.head(),>'
'>, new.head())> # printing last 5 elements of old and new series> print>(>'
'>, s.tail(),>'
'>, new.tail())> |
>
>
Produzione:
0 50.12 1 54.10 2 54.65 3 52.38 4 52.95 Name: Stock Price, dtype: float64 0 55.12 1 59.10 2 59.65 3 57.38 4 57.95 Name: Stock Price, dtype: float64 3007 772.88 3008 771.07 3009 773.18 3010 771.61 3011 782.22 Name: Stock Price, dtype: float64 3007 777.88 3008 776.07 3009 778.18 3010 776.61 3011 787.22 Name: Stock Price, dtype: float64>
Come osservato, Nuovi valori = vecchi valori + 5