Leggiamo le strutture dati lineari come un array, una lista concatenata, uno stack e una coda in cui tutti gli elementi sono disposti in maniera sequenziale. Le diverse strutture dati vengono utilizzate per diversi tipi di dati.
Alcuni fattori vengono considerati per la scelta della struttura dei dati:
Un albero è anche una delle strutture dati che rappresentano i dati gerarchici. Supponiamo di voler mostrare i dipendenti e le loro posizioni in forma gerarchica, quindi possiamo rappresentarli come mostrato di seguito:
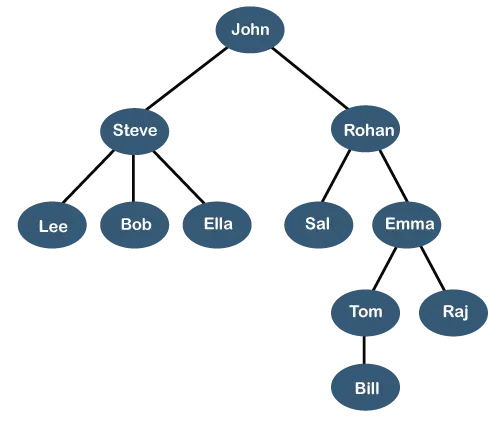
L'albero sopra mostra il gerarchia organizzativa di qualche azienda. Nella struttura di cui sopra, John è il Amministratore delegato dell'azienda e John ha due rapporti diretti denominati come Steve E Rohan . Steve ha tre rapporti diretti nominati Lee, Bob, Ella Dove Steve è un manager. Bob ha due rapporti diretti nominati Deve E Emma . Emma ha due rapporti diretti nominati Tom E Raj . Tom ha un subordinato diretto nominato Conto . Questa particolare struttura logica è nota come a Albero . La sua struttura è simile all'albero vero, per questo è chiamato a Albero . In questa struttura, il radice è in alto e i suoi rami si muovono verso il basso. Pertanto, possiamo dire che la struttura dati Tree è un modo efficiente di archiviare i dati in modo gerarchico.
Comprendiamo alcuni punti chiave della struttura dati dell'Albero.
- Una struttura dati ad albero è definita come una raccolta di oggetti o entità noti come nodi collegati insieme per rappresentare o simulare la gerarchia.
- Una struttura dati ad albero è una struttura dati non lineare perché non viene memorizzata in modo sequenziale. È una struttura gerarchica poiché gli elementi in un albero sono disposti su più livelli.
- Nella struttura dati Tree, il nodo più in alto è noto come nodo radice. Ogni nodo contiene alcuni dati e i dati possono essere di qualsiasi tipo. Nella struttura ad albero sopra, il nodo contiene il nome del dipendente, quindi il tipo di dati sarebbe una stringa.
- Ogni nodo contiene alcuni dati e il collegamento o riferimento di altri nodi che possono essere chiamati figli.
Alcuni termini di base utilizzati nella struttura dati dell'albero.
Consideriamo la struttura ad albero, che è mostrata di seguito:

Nella struttura sopra, ogni nodo è etichettato con un numero. Ciascuna freccia mostrata nella figura sopra è nota come a collegamento tra i due nodi.
Proprietà della struttura dati dell'albero

In base alle proprietà della struttura dati Albero, gli alberi vengono classificati in varie categorie.
Implementazione dell'albero
La struttura dati dell'albero può essere creata creando dinamicamente i nodi con l'aiuto dei puntatori. L'albero in memoria può essere rappresentato come mostrato di seguito:

La figura sopra mostra la rappresentazione della struttura dati ad albero in memoria. Nella struttura precedente, il nodo contiene tre campi. Il secondo campo memorizza i dati; il primo campo memorizza l'indirizzo del figlio di sinistra e il terzo campo memorizza l'indirizzo del figlio di destra.
natasha dalal
Nella programmazione, la struttura di un nodo può essere definita come:
struct node { int data; struct node *left; struct node *right; } La struttura di cui sopra può essere definita solo per gli alberi binari perché l'albero binario può avere al massimo due figli e gli alberi generici possono avere più di due figli. La struttura del nodo per alberi generici sarebbe diversa rispetto all'albero binario.
Applicazioni degli alberi
Le seguenti sono le applicazioni degli alberi:
Tipi di struttura dati dell'albero
Di seguito sono riportati i tipi di struttura dati ad albero:

Ci può essere N numero di sottoalberi in un albero generale. Nell'albero generale, i sottoalberi non sono ordinati poiché i nodi nel sottoalbero non possono essere ordinati.
Ogni albero non vuoto ha un bordo rivolto verso il basso e questi bordi sono collegati ai nodi detti nodi figli . Il nodo radice è etichettato con il livello 0. I nodi che hanno lo stesso genitore sono noti come fratelli .

Per saperne di più sull'albero binario, fare clic sul collegamento indicato di seguito:
https://www.javatpoint.com/binary-tree
Ogni nodo nel sottoalbero di sinistra deve contenere un valore inferiore al valore del nodo radice e il valore di ciascun nodo nel sottoalbero di destra deve essere maggiore del valore del nodo radice.
Un nodo può essere creato con l'aiuto di un tipo di dati definito dall'utente noto come struttura, come mostrato di seguito:
struct node { int data; struct node *left; struct node *right; } Quella sopra è la struttura del nodo con tre campi: campo dati, il secondo campo è il puntatore sinistro del tipo di nodo e il terzo campo è il puntatore destro del tipo di nodo.
Per saperne di più sull'albero di ricerca binario, fare clic sul collegamento indicato di seguito:
https://www.javatpoint.com/binary-search-tree
È uno dei tipi dell'albero binario, o possiamo dire che è una variante dell'albero binario di ricerca. L'albero AVL soddisfa la proprietà di albero binario nonché del albero di ricerca binario . È un albero di ricerca binario autobilanciante inventato da Adelson Velsky Lindas . Qui, autobilanciamento significa bilanciare le altezze del sottoalbero sinistro e del sottoalbero destro. Questo equilibrio è misurato in termini di fattore di equilibrio .
stringa in C++
Possiamo considerare un albero come un albero AVL se obbedisce all'albero di ricerca binario e ad un fattore di bilanciamento. Il fattore di bilanciamento può essere definito come il differenza tra l'altezza del sottoalbero sinistro e l'altezza del sottoalbero destro . Il valore del fattore di bilanciamento deve essere 0, -1 o 1; pertanto, ciascun nodo nell'albero AVL dovrebbe avere il valore del fattore di bilanciamento come 0, -1 o 1.
Per saperne di più sull'albero AVL, fare clic sul collegamento indicato di seguito:
https://www.javatpoint.com/avl-tree
L'albero rosso-nero è l'albero di ricerca binario. Il prerequisito dell'albero Rosso-Nero è che dovremmo conoscere l'albero di ricerca binario. In un albero di ricerca binario, il valore del sottoalbero sinistro dovrebbe essere inferiore al valore di quel nodo e il valore del sottoalbero destro dovrebbe essere maggiore del valore di quel nodo. Come sappiamo, la complessità temporale della ricerca binaria nel caso medio è log2n, il caso migliore è O(1) e il caso peggiore è O(n).
Quando viene eseguita qualsiasi operazione sull'albero, vogliamo che il nostro albero sia bilanciato in modo che tutte le operazioni come ricerca, inserimento, cancellazione, ecc., richiedano meno tempo e tutte queste operazioni abbiano la complessità temporale di tronco d'albero2N.
L'albero rosso-nero è un albero di ricerca binario autobilanciante. L'albero AVL è quindi anche un albero di ricerca binario con bilanciamento dell'altezza perché abbiamo bisogno di un albero rosso-nero . Nell'albero AVL, non sappiamo quante rotazioni sarebbero necessarie per bilanciare l'albero, ma nell'albero Rosso-nero sono necessarie un massimo di 2 rotazioni per bilanciare l'albero. Contiene un bit in più che rappresenta il colore rosso o nero di un nodo per garantire il bilanciamento dell'albero.
La struttura dati dell'albero splay è anche un albero di ricerca binario in cui l'elemento a cui si è avuto accesso di recente viene posizionato nella posizione radice dell'albero eseguendo alcune operazioni di rotazione. Qui, allargamento indica il nodo a cui si è avuto accesso di recente. È un autobilanciamento albero di ricerca binario che non ha alcuna condizione di equilibrio esplicita come AVL albero.
Potrebbe essere possibile che l'altezza dell'albero di splay non sia bilanciata, ovvero l'altezza dei sottoalberi sinistro e destro possa differire, ma le operazioni nell'albero di splay seguono l'ordine di calma tempo dove N è il numero di nodi.
L'albero strombato è un albero equilibrato ma non può essere considerato un albero equilibrato in altezza perché dopo ogni operazione viene eseguita la rotazione che porta ad un albero equilibrato.
La struttura dei dati Treap proviene dalla struttura dei dati Tree e Heap. Pertanto, comprende le proprietà delle strutture dati sia Tree che Heap. Nell'albero di ricerca binario, ogni nodo del sottoalbero di sinistra deve essere uguale o inferiore al valore del nodo radice e ogni nodo del sottoalbero di destra deve essere uguale o maggiore del valore del nodo radice. Nella struttura dei dati heap, sia il sottoalbero destro che quello sinistro contengono chiavi più grandi della radice; pertanto, possiamo dire che il nodo radice contiene il valore più basso.
Nella struttura dati di treap, ogni nodo ha entrambi chiave E priorità dove la chiave è derivata dall'albero di ricerca binario e la priorità è derivata dalla struttura dei dati heap.
stringa in Java
IL Trep la struttura dei dati segue due proprietà che sono riportate di seguito:
- Figlio destro di un nodo>= nodo corrente e figlio sinistro di un nodo<=current node (binary tree)< li>
- I figli di qualsiasi sottoalbero devono essere maggiori del nodo (heap)
Il B-tree è un equilibrato m-way albero dove M definisce l'ordine dell'albero. Finora abbiamo letto che il nodo contiene una sola chiave ma il b-tree può avere più di una chiave e più di 2 figli. Mantiene sempre i dati ordinati. Nell'albero binario, è possibile che i nodi foglia possano trovarsi a livelli diversi, ma nell'albero b tutti i nodi foglia devono essere allo stesso livello.
Se l'ordine è m allora il nodo ha le seguenti proprietà:
- Ogni nodo in un albero b può avere il massimo M bambini
- Per i figli minimi, un nodo foglia ha 0 figli, il nodo radice ha un minimo di 2 figli e il nodo interno ha un tetto minimo di m/2 figli. Ad esempio, il valore di m è 5, il che significa che un nodo può avere 5 figli e i nodi interni possono contenere un massimo di 3 figli.
- Ogni nodo ha un numero massimo di chiavi (m-1).
Il nodo radice deve contenere almeno 1 chiave e tutti gli altri nodi devono contenerne almeno 1 soffitto di m/2 meno 1 chiavi.