L'apprendimento automatico è il ramo di Intelligenza artificiale che si concentra sullo sviluppo di modelli e algoritmi che consentono ai computer di apprendere dai dati e migliorare dall'esperienza precedente senza essere esplicitamente programmati per ogni attività. In parole semplici, il machine learning insegna ai sistemi a pensare e comprendere come gli esseri umani imparando dai dati.
In questo articolo esploreremo i vari tipi di algoritmi di apprendimento automatico che sono importanti per le esigenze future. Apprendimento automatico è generalmente un sistema di formazione per imparare dalle esperienze passate e migliorare le prestazioni nel tempo. Apprendimento automatico aiuta a prevedere enormi quantità di dati. Aiuta a fornire risultati rapidi e accurati per ottenere opportunità redditizie.
Tipi di apprendimento automatico
Esistono diversi tipi di machine learning, ciascuno con caratteristiche e applicazioni speciali. Alcuni dei principali tipi di algoritmi di machine learning sono i seguenti:
- Apprendimento automatico supervisionato
- Apprendimento automatico non supervisionato
- Apprendimento automatico semi-supervisionato
- Insegnamento rafforzativo
Tipi di apprendimento automatico
1. Apprendimento automatico supervisionato
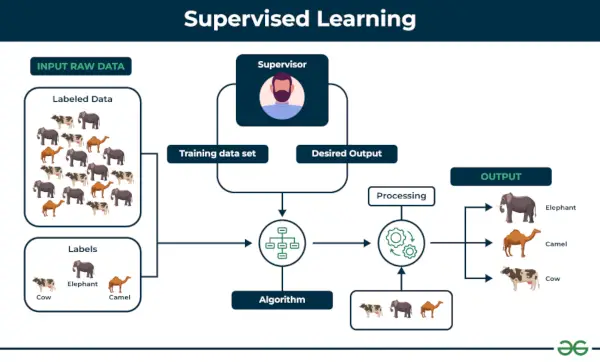
Apprendimento supervisionato è definito come quando un modello viene addestrato su a Set di dati etichettato . I set di dati etichettati hanno parametri sia di input che di output. In Apprendimento supervisionato gli algoritmi imparano a mappare i punti tra gli input e gli output corretti. Ha sia i set di dati di training che quelli di validazione etichettati.
Apprendimento supervisionato
Capiamolo con l'aiuto di un esempio.
Esempio: Considera uno scenario in cui devi creare un classificatore di immagini per distinguere tra cani e gatti. Se si alimentano i set di dati di immagini etichettate di cani e gatti all'algoritmo, la macchina imparerà a classificare un cane o un gatto da queste immagini etichettate. Quando inseriamo nuove immagini di cani o gatti che non ha mai visto prima, utilizzerà gli algoritmi appresi e predirà se si tratta di un cane o di un gatto. Questo è come apprendimento supervisionato funziona, e questa è in particolare una classificazione delle immagini.
Esistono due categorie principali di apprendimento supervisionato, menzionate di seguito:
- Classificazione
- Regressione
Classificazione
Classificazione si occupa di predire categorico variabili target, che rappresentano classi o etichette discrete. Ad esempio, classificando le e-mail come spam o non spam o prevedendo se un paziente ha un alto rischio di malattie cardiache. Gli algoritmi di classificazione imparano a mappare le caratteristiche di input su una delle classi predefinite.
Ecco alcuni algoritmi di classificazione:
- Regressione logistica
- Supporta la macchina vettoriale
- Foresta casuale
- Albero decisionale
- K-Vicini più vicini (KNN)
- L'ingenuo Bayes
Regressione
Regressione , d'altra parte, si occupa di previsione continuo variabili target, che rappresentano valori numerici. Ad esempio, prevedere il prezzo di una casa in base alle sue dimensioni, posizione e servizi oppure prevedere le vendite di un prodotto. Gli algoritmi di regressione imparano a mappare le caratteristiche di input su un valore numerico continuo.
Ecco alcuni algoritmi di regressione:
- Regressione lineare
- Regressione polinomiale
- Regressione della cresta
- Regressione al lazo
- Albero decisionale
- Foresta casuale
Vantaggi dell'apprendimento automatico supervisionato
- Apprendimento supervisionato i modelli possono avere un'elevata precisione poiché vengono addestrati dati etichettati .
- Il processo decisionale nei modelli di apprendimento supervisionato è spesso interpretabile.
- Può essere spesso utilizzato in modelli pre-addestrati, consentendo di risparmiare tempo e risorse durante lo sviluppo di nuovi modelli da zero.
Svantaggi dell'apprendimento automatico supervisionato
- Ha limitazioni nel conoscere i modelli e potrebbe avere difficoltà con modelli invisibili o inaspettati che non sono presenti nei dati di addestramento.
- Può essere dispendioso in termini di tempo e denaro poiché fa affidamento su etichettato solo dati.
- Potrebbe portare a generalizzazioni inadeguate basate su nuovi dati.
Applicazioni dell'apprendimento supervisionato
L'apprendimento supervisionato viene utilizzato in un'ampia varietà di applicazioni, tra cui:
- Classificazione delle immagini : identifica oggetti, volti e altre caratteristiche nelle immagini.
- Elaborazione del linguaggio naturale: Estrai informazioni dal testo, come sentimenti, entità e relazioni.
- Riconoscimento vocale : converte la lingua parlata in testo.
- Sistemi di raccomandazione : fornisce consigli personalizzati agli utenti.
- Analisi predittiva : prevedere risultati quali vendite, abbandono dei clienti e prezzi delle azioni.
- Diagnosi medica : Rileva malattie e altre condizioni mediche.
- Intercettazione di una frode : identificare le transazioni fraudolente.
- Veicoli autonomi : Riconoscere e rispondere agli oggetti nell'ambiente.
- Rilevamento dello spam tramite posta elettronica : classifica le email come spam o non spam.
- Controllo di qualità nella produzione : Ispezionare i prodotti per eventuali difetti.
- Livello di crediti : Valutare il rischio di inadempienza del mutuatario su un prestito.
- Gioco : Riconosci i personaggi, analizza il comportamento dei giocatori e crea NPC.
- Servizio Clienti : automatizza le attività di assistenza clienti.
- Previsioni del tempo : effettua previsioni su temperatura, precipitazioni e altri parametri meteorologici.
- Analisi sportiva : analizza le prestazioni dei giocatori, fai previsioni di gioco e ottimizza le strategie.
2. Apprendimento automatico non supervisionato
Apprendimento non supervisionato L'apprendimento non supervisionato è un tipo di tecnica di apprendimento automatico in cui un algoritmo scopre modelli e relazioni utilizzando dati senza etichetta. A differenza dell’apprendimento supervisionato, l’apprendimento non supervisionato non prevede la fornitura all’algoritmo di output target etichettati. L'obiettivo principale dell'apprendimento non supervisionato è spesso quello di scoprire modelli nascosti, somiglianze o cluster all'interno dei dati, che possono quindi essere utilizzati per vari scopi, come l'esplorazione dei dati, la visualizzazione, la riduzione della dimensionalità e altro ancora.
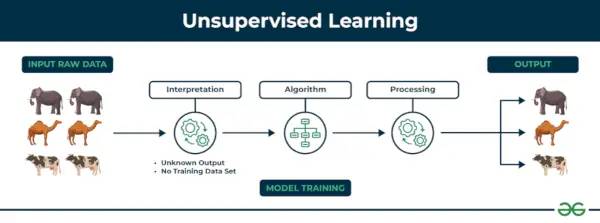
Apprendimento non supervisionato
Capiamolo con l'aiuto di un esempio.
Esempio: Considera di avere un set di dati che contiene informazioni sugli acquisti effettuati dal negozio. Attraverso il clustering, l'algoritmo può raggruppare lo stesso comportamento d'acquisto tra te e altri clienti, rivelando potenziali clienti senza etichette predefinite. Questo tipo di informazioni può aiutare le aziende a ottenere clienti target e a identificare valori anomali.
Esistono due categorie principali di apprendimento non supervisionato, menzionate di seguito:
- Raggruppamento
- Associazione
Raggruppamento
Raggruppamento è il processo di raggruppamento dei punti dati in cluster in base alla loro somiglianza. Questa tecnica è utile per identificare modelli e relazioni nei dati senza la necessità di esempi etichettati.
Ecco alcuni algoritmi di clustering:
- Algoritmo di clustering K-Means
- Algoritmo di spostamento della media
- Algoritmo DBSCAN
- Analisi del componente principale
- Analisi dei componenti indipendenti
Associazione
Impara la regola dell'associazione ing è una tecnica per scoprire le relazioni tra gli elementi in un set di dati. Identifica le regole che indicano che la presenza di un elemento implica la presenza di un altro elemento con una probabilità specifica.
Ecco alcuni algoritmi di apprendimento delle regole di associazione:
- Algoritmo Apriori
- Incandescenza
- Algoritmo di crescita FP
Vantaggi dell'apprendimento automatico non supervisionato
- Aiuta a scoprire modelli nascosti e varie relazioni tra i dati.
- Utilizzato per attività come segmentazione della clientela, rilevamento anomalie, E esplorazione dei dati .
- Non richiede dati etichettati e riduce lo sforzo di etichettatura dei dati.
Svantaggi dell'apprendimento automatico non supervisionato
- Senza utilizzare le etichette, potrebbe essere difficile prevedere la qualità dell’output del modello.
- L'interpretabilità dei cluster potrebbe non essere chiara e potrebbe non avere interpretazioni significative.
- Ha tecniche come codificatori automatici E riduzione della dimensionalità che può essere utilizzato per estrarre caratteristiche significative dai dati grezzi.
Applicazioni dell'apprendimento non supervisionato
Ecco alcune applicazioni comuni dell’apprendimento non supervisionato:
- Raggruppamento : raggruppa punti dati simili in cluster.
- Rilevamento anomalie : identificare valori anomali o anomalie nei dati.
- Riduzione della dimensionalità : Ridurre la dimensionalità dei dati preservandone le informazioni essenziali.
- Sistemi di raccomandazione : suggerisce prodotti, film o contenuti agli utenti in base al loro comportamento o alle loro preferenze storiche.
- Modellazione degli argomenti : Scopri argomenti latenti all'interno di una raccolta di documenti.
- Stima della densità : Stimare la funzione di densità di probabilità dei dati.
- Compressione di immagini e video : riduce la quantità di spazio di archiviazione richiesto per i contenuti multimediali.
- Preelaborazione dei dati : aiuta con le attività di preelaborazione dei dati come la pulizia dei dati, l'imputazione di valori mancanti e il ridimensionamento dei dati.
- Analisi del paniere di mercato : Scopri le associazioni tra i prodotti.
- Analisi dei dati genomici : Identificare modelli o raggruppare geni con profili di espressione simili.
- Segmentazione delle immagini : segmenta le immagini in regioni significative.
- Rilevamento della comunità nei social network : identificare comunità o gruppi di individui con interessi o connessioni simili.
- Analisi del comportamento del cliente : Scopri modelli e approfondimenti per migliori consigli di marketing e prodotti.
- Raccomandazione sui contenuti : classifica e tagga i contenuti per facilitare il consiglio di articoli simili agli utenti.
- Analisi esplorativa dei dati (EDA) : esplora i dati e ottieni informazioni approfondite prima di definire attività specifiche.
3. Apprendimento semi-supervisionato
Apprendimento semi-supervisionato è un algoritmo di apprendimento automatico che funziona tra supervisionato e non supervisionato learning quindi utilizza entrambi etichettati e non etichettati dati. È particolarmente utile quando ottenere dati etichettati è costoso, dispendioso in termini di tempo o di risorse. Questo approccio è utile quando il set di dati è costoso e richiede molto tempo. L'apprendimento semi-supervisionato viene scelto quando i dati etichettati richiedono competenze e risorse pertinenti per addestrarsi o imparare da essi.
Usiamo queste tecniche quando abbiamo a che fare con dati che sono un po' etichettati e il resto gran parte di essi non è etichettato. Possiamo utilizzare le tecniche non supervisionate per prevedere le etichette e quindi fornire queste etichette alle tecniche supervisionate. Questa tecnica è applicabile principalmente nel caso di set di dati di immagini in cui solitamente tutte le immagini non sono etichettate.
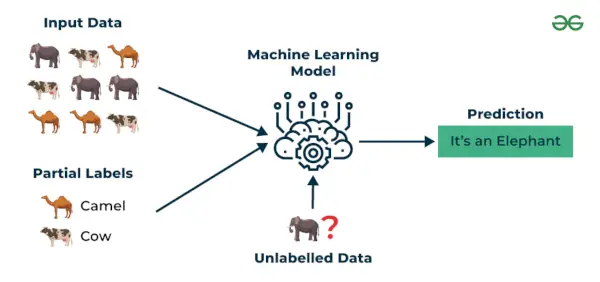
Apprendimento semi-supervisionato
Capiamolo con l'aiuto di un esempio.
Esempio : Considera che stiamo costruendo un modello di traduzione linguistica, avere traduzioni etichettate per ogni coppia di frasi può richiedere molte risorse. Consente ai modelli di apprendere da coppie di frasi etichettate e non etichettate, rendendoli più accurati. Questa tecnica ha portato a miglioramenti significativi nella qualità dei servizi di traduzione automatica.
Tipi di metodi di apprendimento semi-supervisionato
Esistono diversi metodi di apprendimento semi-supervisionato, ciascuno con le proprie caratteristiche. Alcuni dei più comuni includono:
- Apprendimento semi-supervisionato basato su grafici: Questo approccio utilizza un grafico per rappresentare le relazioni tra i punti dati. Il grafico viene quindi utilizzato per propagare le etichette dai punti dati etichettati ai punti dati senza etichetta.
- Propagazione dell'etichetta: Questo approccio propaga in modo iterativo le etichette dai punti dati etichettati ai punti dati senza etichetta, in base alle somiglianze tra i punti dati.
- Co-formazione: Questo approccio addestra due diversi modelli di machine learning su diversi sottoinsiemi di dati senza etichetta. I due modelli vengono quindi utilizzati per etichettare le rispettive previsioni.
- Auto allenamento: Questo approccio addestra un modello di machine learning sui dati etichettati e quindi utilizza il modello per prevedere le etichette per i dati senza etichetta. Il modello viene quindi riqualificato sui dati etichettati e sulle etichette previste per i dati senza etichetta.
- Reti avversarie generative (GAN) : I GAN sono un tipo di algoritmo di deep learning che può essere utilizzato per generare dati sintetici. I GAN possono essere utilizzati per generare dati senza etichetta per l'apprendimento semi-supervisionato addestrando due reti neurali, un generatore e un discriminatore.
Vantaggi del machine learning semi-supervisionato
- Porta a una migliore generalizzazione rispetto a apprendimento supervisionato, poiché richiede sia dati etichettati che non etichettati.
- Può essere applicato a un'ampia gamma di dati.
Svantaggi del machine learning semi-supervisionato
- Semi-supervisionato i metodi possono essere più complessi da implementare rispetto ad altri approcci.
- Ne richiede ancora alcuni dati etichettati che potrebbe non essere sempre disponibile o facile da ottenere.
- I dati senza etichetta possono influire di conseguenza sulle prestazioni del modello.
Applicazioni dell'apprendimento semi-supervisionato
Ecco alcune applicazioni comuni dell’apprendimento semi-supervisionato:
- Classificazione delle immagini e riconoscimento degli oggetti : migliora la precisione dei modelli combinando un piccolo set di immagini etichettate con un set più ampio di immagini senza etichetta.
- Elaborazione del linguaggio naturale (PNL) : migliora le prestazioni dei modelli linguistici e dei classificatori combinando un piccolo insieme di dati di testo etichettati con una grande quantità di testo senza etichetta.
- Riconoscimento vocale: Migliora la precisione del riconoscimento vocale sfruttando una quantità limitata di dati vocali trascritti e un set più ampio di audio senza etichetta.
- Sistemi di raccomandazione : migliorare l'accuratezza dei consigli personalizzati integrando un insieme sparso di interazioni utente-oggetto (dati etichettati) con una vasta gamma di dati sul comportamento degli utenti senza etichetta.
- Sanità e imaging medico : migliora l'analisi delle immagini mediche utilizzando un piccolo set di immagini mediche etichettate insieme a un set più ampio di immagini senza etichetta.
4. Apprendimento automatico di rinforzo
Apprendimento automatico per rinforzo L'algoritmo è un metodo di apprendimento che interagisce con l'ambiente producendo azioni e scoprendo errori. Tentativi, errori e ritardi sono le caratteristiche più rilevanti dell’apprendimento per rinforzo. In questa tecnica, il modello continua ad aumentare le sue prestazioni utilizzando il feedback della ricompensa per apprendere il comportamento o il modello. Questi algoritmi sono specifici per un particolare problema, ad es. Google Self Driving car, AlphaGo, dove un bot compete con gli esseri umani e persino con se stesso per ottenere prestazioni sempre migliori nel Go Game. Ogni volta che inseriamo dati, loro apprendono e aggiungono i dati alla loro conoscenza, ovvero i dati di addestramento. Quindi, più impara, meglio viene addestrato e quindi sperimentato.
Ecco alcuni degli algoritmi di apprendimento per rinforzo più comuni:
- Q-apprendimento: Q-learning è un algoritmo RL senza modello che apprende una funzione Q, che associa gli stati alle azioni. La funzione Q stima la ricompensa attesa per intraprendere una particolare azione in un dato stato.
- SARSA (Azione-Stato-Ricompensa-Azione-Stato): SARSA è un altro algoritmo RL senza modello che apprende una funzione Q. Tuttavia, a differenza del Q-learning, SARSA aggiorna la funzione Q per l’azione effettivamente intrapresa, piuttosto che per l’azione ottimale.
- Apprendimento Q profondo : Il Deep Q-learning è una combinazione di Q-learning e deep learning. Il Q-learning profondo utilizza una rete neurale per rappresentare la funzione Q, che le consente di apprendere relazioni complesse tra stati e azioni.
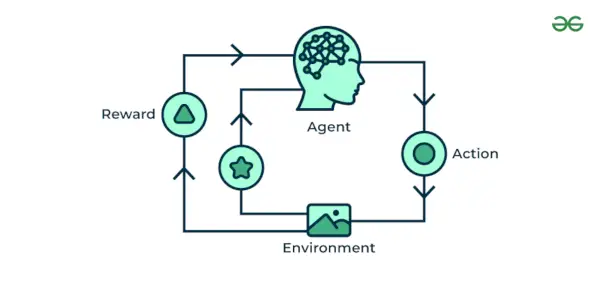
Apprendimento automatico per rinforzo
Capiamolo con l'aiuto di esempi.
Esempio: Considera che stai addestrando un AI agente a giocare a un gioco come gli scacchi. L'agente esplora diverse mosse e riceve feedback positivi o negativi in base al risultato. L'apprendimento per rinforzo trova anche applicazioni in cui imparano a eseguire compiti interagendo con l'ambiente circostante.
Tipi di machine learning per rinforzo
Esistono due tipi principali di apprendimento per rinforzo:
Rinforzo positivo
- Premia l'agente per aver intrapreso l'azione desiderata.
- Incoraggia l'agente a ripetere il comportamento.
- Esempi: dare un dolcetto a un cane perché si sieda, fornire un punto in un gioco per una risposta corretta.
Rinforzo negativo
- Rimuove uno stimolo indesiderato per incoraggiare un comportamento desiderato.
- Scoraggia l'agente dal ripetere il comportamento.
- Esempi: disattivare un forte segnale acustico quando viene premuta una leva, evitare una penalità completando un'attività.
Vantaggi dell'apprendimento automatico per rinforzo
- Ha un processo decisionale autonomo che ben si adatta ai compiti e che può imparare a prendere una sequenza di decisioni, come la robotica e il gioco.
- Questa tecnica è preferita per ottenere risultati a lungo termine molto difficili da ottenere.
- Viene utilizzato per risolvere problemi complessi che non possono essere risolti con le tecniche convenzionali.
Svantaggi dell'apprendimento automatico per rinforzo
- Rinforzo della formazione Gli agenti di apprendimento possono essere computazionalmente costosi e richiedere molto tempo.
- L’apprendimento per rinforzo non è preferibile alla risoluzione di problemi semplici.
- Ha bisogno di molti dati e molti calcoli, il che lo rende poco pratico e costoso.
Applicazioni dell'apprendimento automatico per rinforzo
Ecco alcune applicazioni dell’apprendimento per rinforzo:
- Gioco : RL può insegnare agli agenti a giocare, anche a quelli complessi.
- Robotica : RL può insegnare ai robot a eseguire compiti in modo autonomo.
- Veicoli autonomi : RL può aiutare le auto a guida autonoma a navigare e a prendere decisioni.
- Sistemi di raccomandazione : RL può migliorare gli algoritmi di raccomandazione apprendendo le preferenze dell'utente.
- Assistenza sanitaria : RL può essere utilizzato per ottimizzare i piani di trattamento e la scoperta di farmaci.
- Elaborazione del linguaggio naturale (PNL) : RL può essere utilizzato nei sistemi di dialogo e nei chatbot.
- Finanza e commercio : RL può essere utilizzato per il trading algoritmico.
- Gestione della catena di fornitura e delle scorte : RL può essere utilizzato per ottimizzare le operazioni della catena di approvvigionamento.
- Gestione dell'energia : RL può essere utilizzato per ottimizzare il consumo energetico.
- Giochi di intelligenza artificiale : RL può essere utilizzato per creare NPC più intelligenti e adattivi nei videogiochi.
- Assistenti personali adattivi : RL può essere utilizzato per migliorare gli assistenti personali.
- Realtà Virtuale (VR) e Realtà Aumentata (AR): RL può essere utilizzato per creare esperienze coinvolgenti e interattive.
- Controllo industriale : RL può essere utilizzato per ottimizzare i processi industriali.
- Formazione scolastica : RL può essere utilizzato per creare sistemi di apprendimento adattivo.
- agricoltura : RL può essere utilizzato per ottimizzare le operazioni agricole.
Deve controllare, il nostro articolo dettagliato su : Algoritmi di apprendimento automatico
Conclusione
In conclusione, ogni tipo di machine learning ha il proprio scopo e contribuisce al ruolo generale nello sviluppo di capacità avanzate di previsione dei dati e ha il potenziale per cambiare vari settori come Scienza dei dati . Aiuta ad affrontare la massiccia produzione di dati e la gestione dei set di dati.
siti web di film simili a 123movies
Tipi di machine learning – Domande frequenti
1. Quali sono le sfide affrontate nell’apprendimento supervisionato?
Alcune delle sfide affrontate nell’apprendimento supervisionato includono principalmente la risoluzione degli squilibri di classe, l’uso di dati etichettati di alta qualità e l’evitare l’adattamento eccessivo laddove i modelli funzionano male sui dati in tempo reale.
2. Dove possiamo applicare l’apprendimento supervisionato?
L'apprendimento supervisionato viene comunemente utilizzato per attività come l'analisi delle e-mail di spam, il riconoscimento delle immagini e l'analisi del sentiment.
3. Come si presenta il futuro dell'apprendimento automatico?
L’apprendimento automatico come prospettiva futura può funzionare in settori quali l’analisi meteorologica o climatica, i sistemi sanitari e la modellazione autonoma.
4. Quali sono i diversi tipi di apprendimento automatico?
Esistono tre tipi principali di machine learning:
- Apprendimento supervisionato
- Apprendimento non supervisionato
- Insegnamento rafforzativo
5. Quali sono gli algoritmi di machine learning più comuni?
Alcuni degli algoritmi di machine learning più comuni includono:
- Regressione lineare
- Regressione logistica
- Supporta macchine vettoriali (SVM)
- K-vicini più vicini (KNN)
- Alberi decisionali
- Foreste casuali
- Reti neurali artificiali