Guardiano dello zoo è un servizio di coordinamento distribuito e open source per applicazioni distribuite. Espone un semplice insieme di primitive per implementare servizi di livello superiore per la sincronizzazione, la manutenzione della configurazione, il gruppo e la denominazione.
In un sistema distribuito, ci sono più nodi o macchine che devono comunicare tra loro e coordinare le proprie azioni. ZooKeeper fornisce un modo per garantire che questi nodi siano consapevoli l'uno dell'altro e possano coordinare le loro azioni. Lo fa mantenendo un albero gerarchico di nodi dati chiamato Znodi , che può essere utilizzato per archiviare e recuperare dati e mantenere le informazioni sullo stato. ZooKeeper fornisce una serie di primitive, come blocchi, barriere e code, che possono essere utilizzate per coordinare le azioni dei nodi in un sistema distribuito. Fornisce inoltre funzionalità quali l'elezione del leader, il failover e il ripristino, che possono contribuire a garantire che il sistema sia resistente ai guasti. ZooKeeper è ampiamente utilizzato in sistemi distribuiti come Hadoop, Kafka e HBase ed è diventato un componente essenziale di molte applicazioni distribuite.
Perchè ne abbiamo bisogno?
- Servizi di coordinamento : L'integrazione/comunicazione di servizi in un ambiente distribuito.
- I servizi di coordinamento sono complessi da gestire correttamente. Sono particolarmente inclini a errori come condizioni di gara e stallo.
- Condizione di gara -Due o più sistemi che tentano di eseguire alcune attività.
- Deadlock – Due o più operazioni sono in attesa l'una dell'altra.
- Per facilitare il coordinamento tra ambienti distribuiti, gli sviluppatori hanno avuto un’idea chiamata zookeeper in modo da non dover sollevare da zero le applicazioni distribuite dalla responsabilità di implementare i servizi di coordinamento.
Cos'è il sistema distribuito?
- Più sistemi informatici che lavorano su un unico problema.
- È una rete composta da computer autonomi collegati tramite middleware distribuito.
- Caratteristiche principali : Simultaneo, condivisione delle risorse, indipendente, globale, maggiore tolleranza agli errori e rapporto prezzo/prestazioni molto migliore.
- Obiettivo chiave s: Trasparenza, Affidabilità, Prestazioni, Scalabilità.
- Sfide : Sicurezza, Guasto, Coordinamento e condivisione delle risorse.
Sfida di coordinamento
- Perché il coordinamento in un sistema distribuito è il problema più difficile?
- Coordinamento o gestione della configurazione per un'applicazione distribuita che dispone di molti sistemi.
- Nodo master in cui sono archiviati i dati del cluster.
- I nodi di lavoro o i nodi slave ottengono i dati da questo nodo master.
- singolo punto di guasto.
- la sincronizzazione non è facile.
- Sono necessarie un’attenta progettazione e implementazione.
Guardiano dello zoo Apache
Apache Zookeeper è un servizio di coordinamento distribuito e open source per sistemi distribuiti. Fornisce un luogo centrale in cui le applicazioni distribuite possono archiviare dati, comunicare tra loro e coordinare le attività. Zookeeper viene utilizzato nei sistemi distribuiti per coordinare processi e servizi distribuiti. Fornisce un modello dati semplice e strutturato ad albero, una semplice API e un protocollo distribuito per garantire la coerenza e la disponibilità dei dati. Zookeeper è progettato per essere altamente affidabile e tollerante agli errori e può gestire elevati livelli di throughput di lettura e scrittura.
Zookeeper è implementato in Java ed è ampiamente utilizzato nei sistemi distribuiti, in particolare nell'ecosistema Hadoop. È un progetto della Apache Software Foundation ed è rilasciato sotto la licenza Apache 2.0.
Architettura del guardiano dello zoo
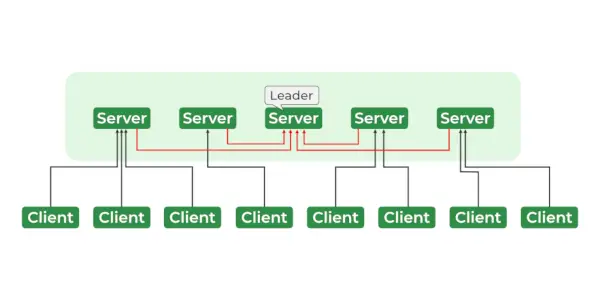
Servizi di guardiani dello zoo
L'architettura ZooKeeper è costituita da una gerarchia di nodi chiamati znodes, organizzati in una struttura ad albero. Ogni znode può archiviare dati e dispone di una serie di autorizzazioni che controllano l'accesso allo znode. Gli znode sono organizzati in uno spazio dei nomi gerarchico, simile a un file system. Alla radice della gerarchia c'è lo znode radice, e tutti gli altri znodi sono figli dello znode radice. La gerarchia è simile a una gerarchia di file system, in cui ogni znode può avere figli e nipoti e così via.
Componenti importanti in Zookeeper
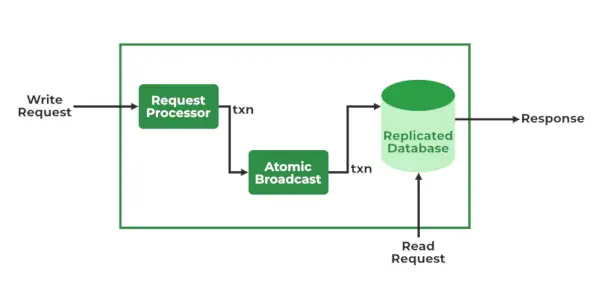
Servizi ZooKeeper
- Leader e seguace
- Richiedi processore – Attivo nel Leader Node ed è responsabile dell'elaborazione delle richieste di scrittura. Dopo l'elaborazione, invia le modifiche ai nodi follower
- Trasmissione atomica – Presente sia nel nodo leader che nei nodi follower. È responsabile dell'invio delle modifiche agli altri nodi.
- Database in memoria (Database replicati): è responsabile della memorizzazione dei dati nello zookeeper. Ogni nodo contiene i propri database. I dati vengono inoltre scritti nel file system garantendo la recuperabilità in caso di problemi con il cluster.
Altri componenti
- Cliente – Uno dei nodi nel nostro cluster di applicazioni distribuite. Accedi alle informazioni dal server. Ogni client invia un messaggio al server per far sapere al server che il client è vivo.
- server – Fornisce tutti i servizi al cliente. Dà il riconoscimento al cliente.
- Insieme – Gruppo di server Zookeeper. Il numero minimo di nodi necessari per formare un insieme è 3.
Modello di dati del guardiano dello zoo
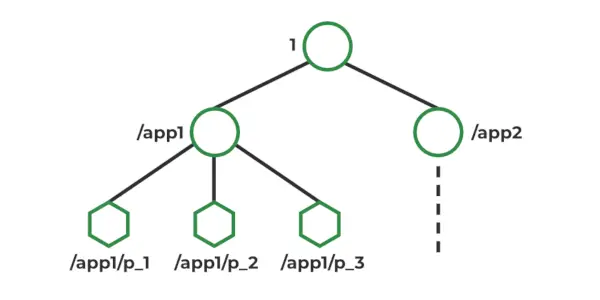
Modello dati ZooKeeper
In Zookeeper, i dati vengono archiviati in uno spazio dei nomi gerarchico, simile a un file system. Ogni nodo nello spazio dei nomi è chiamato Znode e può archiviare dati e avere figli. Gli Znodi sono simili ai file e alle directory in un file system. Zookeeper fornisce una semplice API per creare, leggere, scrivere ed eliminare Znode. Fornisce inoltre meccanismi per rilevare modifiche ai dati archiviati in Znodes, come orologi e trigger. Gli Znode mantengono una struttura delle statistiche che include: numero di versione, ACL, timestamp, lunghezza dei dati
Tipi di Znodi :
- Persistenza : vivi finché non vengono esplicitamente eliminati.
- Effimero : attivo finché la connessione client è attiva.
- Sequenziale : persistente o effimero.
Perché abbiamo bisogno di ZooKeeper in Hadoop?
Zookeeper viene utilizzato per gestire e coordinare i nodi in un cluster Hadoop, inclusi NameNode, DataNode e ResourceManager. In un cluster Hadoop, Zookeeper aiuta a:
- Mantieni le informazioni di configurazione: Zookeeper archivia le informazioni di configurazione per il cluster Hadoop, inclusa la posizione di NameNode, DataNode e ResourceManager.
- Gestisci lo stato del cluster: Zookeeper tiene traccia dello stato dei nodi nel cluster Hadoop e può essere utilizzato per rilevare quando un nodo ha fallito o è diventato non disponibile.
- Coordinare i processi distribuiti: Zookeeper può essere utilizzato per coordinare i processi distribuiti, come la pianificazione dei lavori e l'allocazione delle risorse, tra i nodi di un cluster Hadoop.
Zookeeper aiuta a garantire la disponibilità e l'affidabilità di un cluster Hadoop fornendo un servizio di coordinamento centrale per i nodi del cluster.
Come funziona ZooKeeper in Hadoop?
ZooKeeper funziona come un file system distribuito ed espone un semplice set di API che consentono ai client di leggere e scrivere dati nel file system. Memorizza i suoi dati in una struttura ad albero chiamata znode, che può essere pensata come un file o una directory in un file system tradizionale. ZooKeeper utilizza un algoritmo di consenso per garantire che tutti i suoi server abbiano una visione coerente dei dati archiviati negli Znode. Ciò significa che se un client scrive dati su uno znode, tali dati verranno replicati su tutti gli altri server nell'insieme ZooKeeper.
Una caratteristica importante di ZooKeeper è la sua capacità di supportare il concetto di orologio. Un orologio consente a un client di registrarsi per ricevere notifiche quando i dati archiviati in uno znode cambiano. Ciò può essere utile per monitorare le modifiche ai dati archiviati in ZooKeeper e reagire a tali modifiche in un sistema distribuito.
In Hadoop, ZooKeeper viene utilizzato per diversi scopi, tra cui:
- Memorizzazione delle informazioni di configurazione: ZooKeeper viene utilizzato per memorizzare le informazioni di configurazione condivise da più componenti Hadoop. Ad esempio, potrebbe essere utilizzato per archiviare le posizioni dei NameNode in un cluster Hadoop o gli indirizzi dei nodi JobTracker.
- Fornire sincronizzazione distribuita: ZooKeeper viene utilizzato per coordinare le attività di vari componenti Hadoop e garantire che lavorino insieme in modo coerente. Ad esempio, potrebbe essere utilizzato per garantire che in un cluster Hadoop sia attivo un solo NameNode alla volta.
- Mantenimento della denominazione: ZooKeeper viene utilizzato per mantenere un servizio di denominazione centralizzato per i componenti Hadoop. Ciò può essere utile per identificare e localizzare le risorse in un sistema distribuito.
ZooKeeper è un componente essenziale di Hadoop e svolge un ruolo cruciale nel coordinare l'attività dei suoi vari sottocomponenti.
Leggere e scrivere in Apache Zookeeper
ZooKeeper fornisce un'interfaccia semplice e affidabile per leggere e scrivere dati. I dati sono archiviati in uno spazio dei nomi gerarchico, simile a un file system, con nodi chiamati znodes. Ogni znode può memorizzare dati e avere znode figli. I client ZooKeeper possono leggere e scrivere dati su questi znode utilizzando rispettivamente i metodi getData() e setData(). Ecco un esempio di lettura e scrittura di dati utilizzando l'API Java ZooKeeper:
Giava
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
Python3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
java int in carattere
>
Sessione e orologi
Sessione
- Le richieste in una sessione vengono eseguite in ordine FIFO.
- Una volta stabilita la sessione, il ID sessione viene assegnato al cliente.
- Il cliente invia battiti del cuore per mantenere valida la sessione
- il timeout della sessione è solitamente rappresentato in millisecondi
Orologi
- Gli orologi sono meccanismi che consentono ai client di ricevere notifiche sui cambiamenti in Zookeeper
- Il client può guardare mentre legge un particolare znode.
- Le modifiche agli Znodi sono modifiche dei dati associati agli znodi o cambiamenti nei figli degli znodi.
- Gli orologi vengono attivati una sola volta.
- Se la sessione è scaduta, vengono rimossi anche gli orologi.