Il test di regressione è una tecnica di test della scatola nera. Viene utilizzato per autenticare una modifica del codice nel software che non influisce sulla funzionalità esistente del prodotto. Il test di regressione garantisce che il prodotto funzioni correttamente con nuove funzionalità, correzioni di bug o qualsiasi modifica alla funzionalità esistente.
Il test di regressione è un tipo di test del software . I casi di test vengono rieseguiti per verificare che la funzionalità precedente dell'applicazione funzioni correttamente e che le nuove modifiche non abbiano prodotto alcun bug.
Il test di regressione può essere eseguito su una nuova build quando si verifica una modifica significativa nella funzionalità originale. Garantisce che il codice continui a funzionare anche quando si verificano le modifiche. Regressione significa ripetere il test di quelle parti dell'applicazione che sono invariate.
I test di regressione sono noti anche come metodo di verifica. I casi di test sono spesso automatizzati. I casi di test devono essere eseguiti più volte e l'esecuzione manuale dello stesso caso di test più e più volte richiede molto tempo ed è noiosa.
Esempio di test di regressione
Qui prenderemo un caso per definire in modo efficiente il test di regressione:
Considera un prodotto Y, in cui una delle funzionalità è attivare la conferma, l'accettazione e l'invio di e-mail. Deve anche essere testato per garantire che la modifica al codice non li influenzi. La regressione dei test non dipende da alcun linguaggio di programmazione simile Giava , C++ , C# , ecc. Questo metodo viene utilizzato per testare il prodotto per eventuali modifiche o aggiornamenti apportati. Garantisce che qualsiasi modifica in un prodotto non influisca sul modulo esistente del prodotto. Verificare che i bug risolti e le nuove funzionalità aggiunte non abbiano creato alcun problema nella precedente versione funzionante del Software.
Quando possiamo eseguire i test di regressione?
Effettuiamo test di regressione ogni volta che il codice di produzione viene modificato.
Possiamo eseguire test di regressione nel seguente scenario, questi sono:
1. Quando vengono aggiunte nuove funzionalità all'applicazione.
Esempio:
Un sito Web dispone di una funzionalità di accesso che consente agli utenti di accedere solo tramite e-mail. Ora fornisce una nuova funzionalità per effettuare l'accesso utilizzando Facebook.
2. Quando è presente un requisito di modifica.
Esempio:
Ricorda la password rimossa dalla pagina di accesso applicabile in precedenza.
3. Quando il difetto è stato risolto
Esempio:
Supponiamo che il pulsante di accesso non funzioni in una pagina di accesso e che un tester segnali un bug che indica che il pulsante di accesso è rotto. Una volta risolto il bug dagli sviluppatori, il tester lo testa per assicurarsi che il pulsante di accesso funzioni secondo il risultato previsto. Allo stesso tempo, il tester testa altre funzionalità correlate al pulsante di accesso.
4. Quando si verifica un problema di prestazioni risolto
Esempio:
Il caricamento di una home page richiede 5 secondi, riducendo il tempo di caricamento a 2 secondi.
arp: un comando
5. Quando c'è un cambiamento ambientale
Esempio:
Quando aggiorniamo il database da MySql a Oracle.
Come eseguire i test di regressione?
La necessità di eseguire test di regressione nasce quando la manutenzione del software include miglioramenti, correzioni di errori, ottimizzazione ed eliminazione di funzionalità esistenti. Queste modifiche potrebbero influire sulla funzionalità del sistema. In questo caso diventa necessario il test di regressione.
I test di regressione possono essere eseguiti utilizzando le seguenti tecniche:
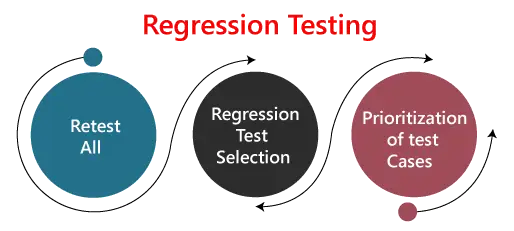
1. Ritestare tutto:
Re-Test è uno degli approcci per eseguire test di regressione. In questo approccio, tutti i casi di test dovrebbero essere rieseguiti. Qui possiamo definire re-test come quando un test fallisce e determiniamo che la causa del fallimento è un errore del software. Se il guasto viene segnalato, possiamo aspettarci una nuova versione del software in cui il difetto sia stato risolto. In questo caso, dovremo eseguire nuovamente il test per confermare che il guasto è stato risolto. Questo è noto come nuovo test. Alcuni lo chiameranno test di conferma.
Il nuovo test è molto costoso, poiché richiede tempo e risorse enormi.
2. Selezione del test di regressione:
- In questa tecnica, verrà eseguita una tuta del caso di test selezionata anziché un'intera causa del caso di test.
- Il caso di test selezionato si adatta diviso in due casi
- Casi di test riutilizzabili.
- Casi di test obsoleti.
- I casi di test riutilizzabili possono essere utilizzati nel ciclo di regressione successivo.
- I casi di test obsoleti non possono essere utilizzati nel ciclo di regressione successivo.
3. Priorità dei casi test:
Assegnare priorità al caso di test in base all'impatto aziendale, alle funzionalità critiche e utilizzate frequentemente. La selezione dei casi di test ridurrà la suite di test di regressione.
Quali sono gli strumenti di test di regressione?
Il test di regressione è una parte vitale del processo di QA; durante l'esecuzione della regressione potremmo dover affrontare le seguenti sfide:
Il completamento dei test di regressione richiede molto tempo. I test di regressione coinvolgono nuovamente i test esistenti, quindi i tester non sono entusiasti di rieseguire il test.
Anche i test di regressione sono complessi quando è necessario aggiornare qualsiasi prodotto; Aumentano anche le liste dei test.
I test di regressione garantiscono che le funzionalità del prodotto esistente siano ancora funzionanti. La comunicazione sui test di regressione con un leader non tecnico può essere un compito difficile. Il dirigente desidera vedere il prodotto progredire e investire molto tempo nei test di regressione per garantire il funzionamento delle funzionalità esistenti può essere difficile.
Processo di test di regressione
Il processo di test di regressione può essere eseguito su tutto il file costruisce e il rilascia .
Test di regressione tra le build
Ogni volta che il bug viene risolto, testiamo nuovamente il bug e, se è presente un modulo dipendente, eseguiamo un test di regressione.

Per esempio , Come eseguiamo i test di regressione se disponiamo di build diverse Costruisci 1, Costruisci 2 e Costruisci 3 , che hanno scenari diversi.
Costruisci1
- In primo luogo il cliente fornirà le esigenze aziendali.
- Quindi il team di sviluppo inizia a sviluppare le funzionalità.
- Successivamente, il team di test inizierà a scrivere i casi di test; ad esempio, scrivono 900 casi di test per la versione n. 1 del prodotto.
- E poi inizieranno a implementare i casi di test.
- Una volta rilasciato il prodotto, il cliente esegue un ciclo di test di accettazione.
- E alla fine, il prodotto viene spostato sul server di produzione.
Costruisci2
- Ora, il cliente richiede l'aggiunta di 3-4 funzionalità extra (nuove) e fornisce anche i requisiti per le nuove funzionalità.
- Il team di sviluppo inizia a sviluppare nuove funzionalità.
- Successivamente, il team di test inizierà a scrivere il test case per le nuove funzionalità e scriverà circa 150 nuovi test case. Pertanto, il numero totale dei casi di test scritti è 1050 per entrambe le versioni.
- Ora il team di test inizia a testare le nuove funzionalità utilizzando 150 nuovi casi di test.
- Una volta terminato, inizieranno a testare le vecchie funzionalità con l'aiuto di 900 casi di test per verificare che l'aggiunta della nuova funzionalità abbia danneggiato o meno le vecchie funzionalità.
- Qui, testare le vecchie funzionalità è noto come Test di regressione .
- Una volta testate tutte le funzionalità (nuove e vecchie), il prodotto viene consegnato al cliente, che successivamente effettuerà il test di accettazione.
- Una volta terminato il test di accettazione, il prodotto viene spostato sul server di produzione.
Costruisci3
- Dopo la seconda versione, il cliente desidera rimuovere una delle funzionalità come Vendite.
- Quindi eliminerà tutti i casi di test appartenenti al modulo vendite (circa 120 casi di test).
- Quindi, testa l'altra funzionalità per verificare che tutte le altre funzionalità funzionino correttamente dopo aver rimosso i casi di test del modulo di vendita e questo processo viene eseguito durante il test di regressione.
Nota:
- Testare le funzionalità stabili per garantire che non funzionino a causa delle modifiche. Qui i cambiamenti implicano che il modifica, aggiunta, correzione di bug o cancellazione .
- La riesecuzione degli stessi casi di test nelle diverse build o versioni serve a garantire che i cambiamenti (modifica, aggiunta, correzione di bug o eliminazione) non introducano bug nelle funzionalità stabili.
Test di regressione durante il rilascio
Il processo di test di regressione inizia ogni volta che c'è una nuova versione per lo stesso progetto perché la nuova funzionalità potrebbe influenzare i vecchi elementi nelle versioni precedenti.
Per comprendere il processo di test di regressione, seguiremo i passaggi seguenti:
Passo 1
Non sono previsti test di regressione Versione n. 1 perché non è stata apportata alcuna modifica alla versione n. 1 poiché la versione stessa è nuova.
Passo 2
Parte dal concetto di test di regressione Versione n.2 quando il cliente ne dà un po' nuovi requisiti .
Passaggio 3
Dopo aver ottenuto prima i nuovi requisiti (modifica delle funzionalità), loro (gli sviluppatori e gli ingegneri di test) capiranno le esigenze prima di passare al analisi d'impatto .
Passaggio 4
Dopo aver compreso i nuovi requisiti, eseguiremo un round di analisi d'impatto per evitare il rischio maggiore, ma qui sorge la domanda: chi farà l’analisi di impatto?
Passaggio 5
L'analisi d'impatto viene effettuata da cliente in base al loro conoscenza aziendale , IL sviluppatore in base al loro conoscenza della codifica e, cosa più importante, è fatto da ingegnere di prova perché hanno il la conoscenza del prodotto .
Nota: se lo fa una singola persona, potrebbe non coprire tutte le aree di impatto, quindi includiamo tutte le persone in modo da poter coprire un'area di impatto massima e l'analisi dell'impatto dovrebbe essere eseguita nelle prime fasi dei rilasci.
Passaggio 6
Una volta che abbiamo finito con zona di impatto , quindi lo sviluppatore preparerà il file area di impatto (documento) , e il cliente preparerà anche il documento relativo all'area di impatto in modo che possiamo raggiungere il massima copertura dell’analisi di impatto .
Passaggio 7
Dopo aver completato l'analisi dell'impatto, lo sviluppatore, il cliente e l'ingegnere del test invieranno il file Rapporti# dei documenti dell'area di impatto al Testare il cavo . E nel frattempo l'ingegnere del test e lo sviluppatore sono impegnati a lavorare sul nuovo banco di prova.
Passaggio 8
Una volta che il responsabile del test riceve il numero dei rapporti, lo farà consolidare i report e archiviati nel file repository dei requisiti dei casi di test per la versione n.1.
Nota: Repository dei test case: qui salveremo tutti i test case dei rilasci.
Passaggio 9
Successivamente, il responsabile del test si avvalerà dell'aiuto di RTM e sceglierà il necessario caso di test di regressione dal archivio di casi di test e tali file verranno inseriti nel file Suite di test di regressione .
Nota:
- Il responsabile del test memorizzerà il caso del test di regressione nella suite di test di regressione per evitare ulteriore confusione.

Passaggio 10
Successivamente, quando l'ingegnere del test avrà finito di lavorare sui nuovi casi di test, lo farà il responsabile del test assegnare il caso del test di regressione all'ingegnere di prova.
Passaggio 11
Quando tutti i casi di test di regressione e le nuove funzionalità sono stabile e superato , quindi controlla il area di impatto utilizzando il caso di prova finché non sarà durevole per le vecchie funzionalità più le nuove funzionalità, quindi verrà consegnato al cliente.

Tipi di test di regressione
I diversi tipi di test di regressione sono i seguenti:
- Test di regressione unitaria [URT]
- Test di regressione regionale[RRT]
- Test di regressione completo o completo [FRT]

1) Test di regressione unitaria [URT]
In questo caso testeremo solo l'unità modificata, non l'area di impatto, perché potrebbe influenzare i componenti dello stesso modulo.
Esempio 1
Nell'applicazione seguente e nella prima build, lo sviluppatore sviluppa il file Ricerca pulsante che accetta 1-15 caratteri . Quindi l'ingegnere di prova testa il pulsante Cerca con l'aiuto di tecnica di progettazione dei casi di test .

Ora, il cliente apporta alcune modifiche al requisito e richiede anche che il file Pulsante Cerca può accettare il 1-35 caratteri . L'ingegnere del test testerà solo il pulsante Cerca per verificare che richieda da 1 a 35 caratteri e non controllerà alcuna ulteriore funzionalità della prima build.
Esempio2
Ecco, abbiamo Costruisci B001 , viene identificato un difetto e il rapporto viene consegnato allo sviluppatore. Lo sviluppatore risolverà il bug e invierà alcune nuove funzionalità sviluppate nel secondo Costruisci B002 . Successivamente, l'ingegnere del test eseguirà il test solo dopo aver risolto il difetto.
- L'ingegnere del test lo identificherà cliccando su Invia il pulsante va alla pagina vuota.
- Ed è un difetto e viene inviato allo sviluppatore per risolverlo.
- Quando la nuova build arriva insieme alle correzioni dei bug, l'ingegnere del test testerà solo il pulsante Invia.
- E qui, non controlleremo le altre funzionalità della prima build e passeremo a testare le nuove funzionalità inviate nella seconda build.
- Siamo sicuri che sistemare il Invia non influenzerà le altre funzionalità, quindi testiamo solo il bug corretto.

Pertanto, possiamo dire che testando solo la funzionalità modificata viene chiamata Test di regressione unitaria .
2) Test di regressione regionale [RRT]
In questo testeremo la modifica insieme all'area o alle regioni di impatto, chiamate Test di regressione regionale . Qui stiamo testando l'area di impatto perché se ci sono moduli affidabili, influenzerà anche gli altri moduli.
Per esempio:
Nell'immagine qui sotto, come possiamo vedere, abbiamo quattro moduli diversi, come ad esempio Modulo A, Modulo B, Modulo C e Modulo D , forniti dagli sviluppatori per i test durante la prima build. Ora, l'ingegnere del test identificherà i bug Modulo D . La segnalazione del bug viene inviata agli sviluppatori e il team di sviluppo corregge tali difetti e invia la seconda build.

Nella seconda build i difetti precedenti vengono risolti. Ora l'ingegnere del test capisce che la correzione dei bug nel Modulo D ha influito su alcune funzionalità Modulo A e Modulo C . Pertanto, l'ingegnere di prova testa prima il Modulo D dove il bug è stato risolto e poi controlla le aree di impatto Modulo A e Modulo C . Pertanto, questo test è noto come Test di regressione regionale.
Durante l'esecuzione del test di regressione regionale, potremmo riscontrare il seguente problema:
Problema:
Nella prima build, il cliente invia alcune modifiche ai requisiti e desidera anche aggiungere nuove funzionalità al prodotto. Le esigenze vengono inviate a entrambi i team, ovvero sviluppo e test.
Dopo aver ottenuto i requisiti, il team di sviluppo inizia ad apportare le modifiche e sviluppa anche le nuove funzionalità in base alle esigenze.
Ora, il responsabile del test invia un messaggio di posta ai clienti e chiede loro quali sono tutte le aree di impatto che saranno interessate dopo che sono state apportate le modifiche necessarie. Pertanto, il cliente si farà un'idea di quali funzionalità siano necessarie per essere testate nuovamente. E invierà anche una mail al team di sviluppo per sapere quali tutte le aree dell'applicazione saranno interessate dai cambiamenti e dall'aggiunta di nuove funzionalità.
Allo stesso modo, il cliente invia un'e-mail al team di test per un elenco delle aree di impatto. Pertanto, il responsabile del test raccoglierà l'elenco degli impatti dal cliente, dal team di sviluppo e anche dal team di test.
Questo Elenco degli impatti viene inviato a tutti gli ingegneri di test che guardano l'elenco e controllano se le loro caratteristiche sono state modificate e, se sì, lo fanno test di regressione regionale . Le aree di impatto e le aree modificate sono tutte testate dai rispettivi ingegneri. Ogni ingegnere di test testa solo le caratteristiche che potrebbero essere state influenzate a seguito della modifica.
Il problema con questo approccio di cui sopra è che il responsabile del test potrebbe non avere un'idea completa delle aree di impatto perché il team di sviluppo e il cliente potrebbero non avere molto tempo per ripristinare le sue e-mail.
Soluzione
Per risolvere il problema di cui sopra, seguiremo la procedura seguente:
Quando una nuova build arriva con le ultime funzionalità e correzioni di bug, il team di test organizzerà un incontro in cui si parlerà se le loro funzionalità stanno influenzando a causa della modifica di cui sopra. Pertanto, faranno un giro di Analisi d'impatto e generare il Elenco degli impatti . In questo particolare elenco, l'ingegnere del test cerca di racchiudere le massime aree di impatto probabili, il che diminuisce anche la possibilità di ottenere difetti.
Quando arriva una nuova build, il team di test seguirà la procedura seguente:
- Eseguiranno test del fumo per verificare la funzionalità di base di un'applicazione.
- Quindi testeranno le nuove funzionalità.
- Successivamente, controlleranno le funzionalità modificate.
- Una volta terminato il controllo delle funzionalità modificate, l'ingegnere del test testerà nuovamente i bug.
- E poi controlleranno l’area di impatto eseguendo i test di regressione regionale.
Svantaggio dell'utilizzo dei test di regressione unitaria e regionale
Di seguito sono riportati alcuni degli svantaggi derivanti dall'utilizzo dei test di regressione unitari e regionali:
- Potremmo perdere alcune aree di impatto.
- È possibile che identifichiamo l'area di impatto sbagliata.
Nota: possiamo dire che il lavoro principale che svolgiamo sui test di regressione regionale ci porterà a ottenere un numero maggiore di difetti. Ma, se dedicheremo la stessa dedizione al lavoro sui test di regressione completa, otterremo un numero inferiore di difetti. Pertanto, possiamo determinare qui che il miglioramento dello sforzo di test non ci aiuterà a ottenere più difetti.
3) Test di regressione completa [FRT]
Durante la seconda e la terza versione del prodotto, il cliente richiede l'aggiunta di 3-4 nuove funzionalità, inoltre è necessario correggere alcuni difetti della versione precedente. Quindi il team di test eseguirà l'analisi dell'impatto e identificherà che la modifica di cui sopra ci porterà a testare l'intero prodotto.
Pertanto, possiamo dire che testare il caratteristiche modificate E tutte le restanti (vecchie) funzionalità è chiamato il Test di regressione completa .

Quando eseguiamo il test di regressione completa?
Effettueremo la FRT quando avremo le seguenti condizioni:
- Quando la modifica avviene nel file sorgente del prodotto. Per esempio , JVM è il file root dell'applicazione JAVA e, se si verifica qualche modifica in JVM, verrà testato l'intero programma JAVA.
- Quando dobbiamo eseguire n-numero di modifiche.
Nota:
Il test di regressione regionale è l'approccio ideale del test di regressione, ma il problema è che potremmo perdere molti difetti durante l'esecuzione del test di regressione regionale.
E qui risolveremo questo problema con l'aiuto del seguente approccio:
- Quando viene presentata la domanda per il test, l'ingegnere del test testerà i primi 10-14 cicli ed eseguirà il RRT .
- Quindi per il 15° ciclo eseguiamo la FRT. E ancora, per i prossimi 10-15 cicli, lo faremo Test di regressione regionale , e per il 31° ciclo, facciamo il test di regressione completa , e continueremo così.
- Ma per gli ultimi dieci cicli dell'uscita ci esibiremo solo test di regressione completo .
Pertanto, se seguiamo l'approccio sopra descritto, possiamo ottenere più difetti.
Lo svantaggio di eseguire manualmente i test di regressione ripetutamente:
- La produttività diminuirà.
- È un lavoro difficile da fare.
- Non c'è coerenza nell'esecuzione del test.
- E aumenta anche il tempo di esecuzione del test.
Quindi, ricorreremo all'automazione per superare questi problemi; quando avremo il numero n del ciclo di test di regressione, opteremo per processo di test di regressione automatizzato .
Processo di test di regressione automatizzato
Generalmente optiamo per l'automazione ogni volta che ci sono più rilasci o cicli di regressione multipli o c'è un'attività ripetitiva.
Il processo di test di regressione automatizzato può essere eseguito nei seguenti passaggi:
Nota 1:
Il processo di test dell'applicazione utilizzando alcuni strumenti è noto come test di automazione.
Supponiamo di prendere un esempio campione di a Modulo di accesso , quindi come possiamo eseguire il test di regressione.
In questo caso il Login può essere effettuato in due modi, che sono i seguenti:

Manualmente: In questo, eseguiremo la regressione solo una volta e due volte.
Automazione: In questo caso, eseguiremo l'automazione più volte poiché dobbiamo scrivere gli script di test ed eseguire l'esecuzione.
Nota2: in tempo reale, se abbiamo affrontato alcuni problemi come:
| Problemi | Maneggiare da |
|---|---|
| Nuove caratteristiche | Ingegnere di test manuale |
| Funzionalità di test regressivi | Ingegnere di test di automazione |
| Rimanenti (funzione 110 + versione n. 1) | Ingegnere di test manuale |
Passo 1
Quando inizia la nuova versione, non optiamo per l'automazione perché non esiste il concetto di test di regressione e caso di test di regressione come lo abbiamo capito nel processo di cui sopra.
Passo 2
Quando iniziano la nuova versione e il miglioramento, abbiamo due team, ovvero il team manuale e il team di automazione.
Passaggio 3
Il team manuale esaminerà i requisiti, identificherà anche l'area di impatto e consegnerà il file suite di test dei requisiti al team di automazione.
Passaggio 4
Ora, il team manuale inizia a lavorare sulle nuove funzionalità e il team di automazione inizierà a sviluppare lo script di test e inizierà anche ad automatizzare il test case, il che significa che i test case di regressione verranno convertiti nello script di test.
Passaggio 5
Prima che loro (il team di automazione) inizino ad automatizzare il caso di test, analizzeranno anche quali tutti i casi possono essere automatizzati o meno.
Passaggio 6
Sulla base dell'analisi, avvieranno l'automazione, ovvero convertendo tutti i casi di test di regressione nello script di test.
Passaggio 7
Durante questo processo, si avvarranno dell'aiuto di Casi di regressione perché non hanno una conoscenza del prodotto così come il attrezzo e il applicazione .
Passaggio 8
Una volta che lo script di test è pronto, inizieranno l'esecuzione di questi script sulla nuova applicazione [vecchia funzionalità]. Poiché lo script di test viene scritto con l'aiuto della funzionalità di regressione o della vecchia funzionalità.
Passaggio 9
Una volta completata l'esecuzione, otteniamo uno stato diverso come Superato/fallito .
Passaggio 10
Se lo stato è fallito, significa che deve essere riconfermato manualmente e se il bug esiste, verrà segnalato allo sviluppatore interessato. Quando lo sviluppatore risolve il bug, il bug deve essere nuovamente testato insieme all'area Impatto dall'ingegnere del test manuale e anche lo script deve essere rieseguito dall'ingegnere del test di automazione.
Passaggio 11
Questo processo continua finché non vengono superate tutte le nuove funzionalità e la funzionalità di regressione.

Vantaggi derivanti dall'esecuzione di test di regressione tramite test automatizzati:
- Lo script di test può essere riutilizzato in più versioni.
- Anche se il numero di casi di test di regressione aumenta rilascio per rilascio, non è necessario aumentare le risorse di automazione poiché alcuni casi di regressione sono già automatizzati dalla versione precedente.
- È un processo che fa risparmiare tempo perché l'esecuzione è sempre più veloce rispetto al metodo manuale.
Come selezionare i casi di test per i test di regressione?
È stato trovato da un'ispezione industriale. I numerosi difetti segnalati dal cliente erano dovuti a correzioni di bug dell'ultimo minuto. Creare effetti collaterali e quindi selezionare il caso di test per i test di regressione è un'arte, non un compito facile.
Il test di regressione può essere eseguito mediante:
- Un caso di test che presenta frequenti difetti
- Funzionalità più visibili agli utenti.
- I casi di test verificano le caratteristiche principali del prodotto.
- Tutti i casi di test di integrazione
- Tutti casi di test complessi
- Casi di test del valore limite
- Un esempio di casi di test di successo
- Fallimento dei casi di test
Strumenti di test di regressione
Se il Software subisce frequenti modifiche, aumentano anche i costi dei test di regressione. In questi casi, l’esecuzione manuale dei casi di test aumenta i tempi e i costi di esecuzione dei test. In tal caso, il test automatizzato è la scelta migliore. La durata dell'automazione dipende dal numero di casi di test che rimangono riutilizzabili per cicli di regressione successivi.
Di seguito sono riportati gli strumenti essenziali utilizzati per i test di regressione:
Selenio
Selenium è uno strumento open source. Questo strumento viene utilizzato per il test automatizzato di un'applicazione web. Per i test di regressione basati su browser, è stato utilizzato il selenio. Selenio utilizzato per il test di regressione a livello di interfaccia utente per applicazioni basate sul Web.
Ranorex Studio
Automazione dei test di regressione tutto in uno per app desktop, Web e mobili con Selenium Web Driver integrato. Ranorex Studio include IDE completo e strumenti per l'automazione senza codice.
Test rapido professionale (QTP)
QTP è uno strumento di test automatizzato utilizzato per la regressione e i test funzionali. È uno strumento basato sui dati e basato su parole chiave. Utilizzava il linguaggio VBScript per l'automazione. Se apriamo lo strumento QTP, vediamo i tre pulsanti che sono Registra, riproduci e ferma . Questi pulsanti aiutano a registrare ogni clic e azione eseguita sul sistema informatico. Registra le azioni e le riproduce.

Tester funzionale razionale (RTF)
Il tester funzionale razionale è uno strumento Java utilizzato per automatizzare i casi di test delle applicazioni software. RTF utilizzato per automatizzare i casi di test di regressione e si integra anche con il tester funzionale razionale.
Per ulteriori informazioni sugli strumenti di test di regressione e automazione, fare riferimento al collegamento seguente:
https://www.javatpoint.com/automation-testing-tool
Test di regressione e gestione della configurazione
La gestione della configurazione nei test di regressione diventa fondamentale negli ambienti Agile, dove un codice viene continuamente modificato. Per garantire un test di regressione valido, dobbiamo seguire i passaggi:
- Non sono consentite modifiche al codice durante la fase di test di regressione.
- Un caso di test di regressione non deve essere influenzato dalle modifiche dello sviluppatore.
- Il database utilizzato per i test di regressione deve essere isolato; non sono consentite modifiche nel database.
Differenze tra test di ripetizione e test di regressione
Nuovo test significa testare nuovamente la funzionalità o il bug per garantire che il codice venga corretto. Se non impostati, non è necessario riaprire i difetti. Se risolto, il difetto si è risolto.
Il re-test è un tipo di test eseguito per verificare che i casi di test che non hanno avuto successo nell'esecuzione finale vengano superati con successo dopo la riparazione dei difetti.
Test di regressione significa testare l'applicazione software quando subisce una modifica del codice per garantire che il nuovo codice non abbia influenzato altre parti del Software.
Il test di regressione è un tipo di test eseguito per verificare se un codice non ha modificato la funzionalità esistente dell'applicazione.
Le differenze tra il nuovo test e il test di regressione sono le seguenti:
| Nuovo test | Test di regressione |
|---|---|
| Il nuovo test viene eseguito per garantire che i casi di test che non hanno superato l'esecuzione finale vengano superati dopo la correzione dei difetti. | Il test di regressione viene eseguito per confermare se la modifica del codice non ha influenzato le funzionalità esistenti. |
| Il nuovo test funziona sulle correzioni dei difetti. | Lo scopo del test di regressione è garantire che le modifiche al codice non influiscano negativamente sulla funzionalità esistente. |
| La verifica dei difetti è la parte del nuovo test. | Il test di regressione non include la verifica dei difetti |
| La priorità del Ripetizione è più alta rispetto al Test di Regressione, quindi viene eseguito prima del Test di Regressione. | In base al tipo di progetto e alla disponibilità delle risorse, il test di regressione può essere parallelo al Ripetizione. |
| Il Re-Test è un test pianificato. | Il test di regressione è un test generico. |
| Non possiamo automatizzare i casi di test per il Ripetizione. | Possiamo eseguire l'automazione per i test di regressione; i test manuali potrebbero essere costosi e richiedere molto tempo. |
| Il nuovo test riguarda i casi di test falliti. | Il test di regressione è per i casi test superati. |
| Un nuovo test assicura che il guasto originale sia corretto. | Il test di regressione verifica la presenza di effetti collaterali imprevisti. |
| Il nuovo test esegue i difetti con gli stessi dati e lo stesso ambiente con input diversi con una nuova build. | Il test di regressione avviene quando si verifica una modifica o le modifiche diventano obbligatorie in un progetto esistente. |
| Non è possibile ripetere il test prima di iniziare il test. | I test di regressione possono ottenere casi di test dalle specifiche funzionali, tutorial e manuali per l'utente e rapporti sui difetti relativi al problema corretto. |
Vantaggi dei test di regressione
I vantaggi del test di regressione sono:
- I test di regressione aumentano la qualità del prodotto.
- Garantisce che eventuali correzioni di bug o modifiche non influiscano sulla funzionalità esistente del prodotto.
- Gli strumenti di automazione possono essere utilizzati per i test di regressione.
- Si assicura che i problemi risolti non si ripetano.
Svantaggi dei test di regressione
Ci sono molti vantaggi del test di regressione, ma ci sono anche degli svantaggi.
- Il test di regressione dovrebbe essere eseguito per piccole modifiche al codice poiché anche una lieve modifica al codice può creare problemi nella funzionalità esistente.
- Se nel caso in cui l'automazione non viene utilizzata nel progetto per i test, eseguire il test ancora e ancora sarà un compito noioso e dispendioso in termini di tempo.
Conclusione
Il test di regressione è uno degli aspetti essenziali in quanto aiuta a fornire un prodotto di qualità che fa risparmiare tempo e denaro alle organizzazioni. Aiuta a fornire un prodotto di qualità assicurandosi che qualsiasi modifica nel codice non influisca sulla funzionalità esistente.
Per automatizzare i casi di test di regressione, sono disponibili diversi strumenti di automazione. Uno strumento dovrebbe avere la capacità di aggiornare il file suite di prova poiché la tuta del test di regressione deve essere aggiornata frequentemente.