Nel mondo reale, non tutti i dati su cui lavoriamo hanno una variabile target. Questo tipo di dati non può essere analizzato utilizzando algoritmi di apprendimento supervisionato. Abbiamo bisogno dell’aiuto di algoritmi non supervisionati. Uno dei tipi di analisi più popolari nell'ambito dell'apprendimento non supervisionato è segmentazione della clientela per pubblicità mirate o nell'imaging medico per trovare aree sconosciute o nuove infette e molti altri casi d'uso di cui parleremo più avanti in questo articolo.
Tabella dei contenuti
- Cos'è il clustering?
- Tipi di clustering
- Usi del clustering
- Tipi di algoritmi di clustering
- Applicazioni del Clustering in diversi ambiti:
- Domande frequenti (FAQ) sul clustering
Cos'è il clustering?
L'attività di raggruppare i punti dati in base alla loro somiglianza tra loro è chiamata Clustering o Cluster Analysis. Questo metodo è definito nel ramo di Apprendimento non supervisionato , che mira a ottenere informazioni da punti dati non etichettati, a differenza di apprendimento supervisionato non abbiamo una variabile target.
Il clustering mira a formare gruppi di punti dati omogenei da un set di dati eterogeneo. Valuta la somiglianza in base a una metrica come la distanza euclidea, la somiglianza del coseno, la distanza di Manhattan, ecc. e quindi raggruppa insieme i punti con il punteggio di somiglianza più alto.
Ad esempio, nel grafico riportato di seguito, possiamo vedere chiaramente che ci sono 3 cluster circolari che si formano in base alla distanza.
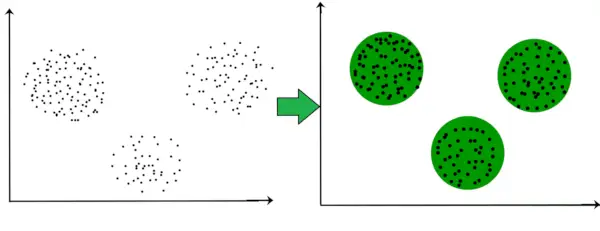
Ora non è necessario che i grappoli formati debbano essere di forma circolare. La forma dei cluster può essere arbitraria. Esistono molti algoritmi che funzionano bene con il rilevamento di cluster di forma arbitraria.
Ad esempio, nel grafico riportato di seguito possiamo vedere che i cluster formati non hanno una forma circolare.

Tipi di clustering
In generale, esistono 2 tipi di clustering che possono essere eseguiti per raggruppare punti dati simili:
- Clustering difficile: In questo tipo di clustering, ciascun punto dati appartiene completamente o meno a un cluster. Ad esempio, supponiamo che ci siano 4 punti dati e dobbiamo raggrupparli in 2 cluster. Pertanto ogni punto dati apparterrà al cluster 1 o al cluster 2.
| Punti dati | Cluster |
|---|---|
| UN | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Clustering morbido: In questo tipo di clustering, invece di assegnare ciascun punto dati in un cluster separato, viene valutata la probabilità che quel punto sia quel cluster. Ad esempio, supponiamo che ci siano 4 punti dati e dobbiamo raggrupparli in 2 cluster. Quindi valuteremo la probabilità che un punto dati appartenga a entrambi i cluster. Questa probabilità viene calcolata per tutti i punti dati.
| Punti dati | Probabilità di C1 | Probabilità di C2 |
| UN | 0,91 | 0,09 |
| B | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| D | 1 | 0 |
Usi del clustering
Ora, prima di iniziare con i tipi di algoritmi di clustering, esamineremo i casi d'uso degli algoritmi di clustering. Gli algoritmi di clustering sono utilizzati principalmente per:
- Segmentazione del mercato – Le aziende utilizzano il clustering per raggruppare i propri clienti e utilizzare pubblicità mirate per attirare più pubblico.
- Analisi delle reti sociali – I siti di social media utilizzano i tuoi dati per comprendere il tuo comportamento di navigazione e fornirti consigli mirati sugli amici o sui contenuti.
- Imaging medico: i medici utilizzano il clustering per individuare aree malate in immagini diagnostiche come i raggi X.
- Rilevamento anomalie – Per trovare valori anomali in un flusso di set di dati in tempo reale o prevedere transazioni fraudolente, possiamo utilizzare il clustering per identificarli.
- Semplifica il lavoro con set di dati di grandi dimensioni: a ogni cluster viene assegnato un ID cluster una volta completato il clustering. Ora puoi ridurre l'intero set di funzionalità di un set di funzionalità nel suo ID cluster. Il clustering è efficace quando può rappresentare un caso complicato con un ID cluster semplice. Utilizzando lo stesso principio, il clustering dei dati può semplificare i set di dati complessi.
Esistono molti altri casi d'uso per il clustering, ma esistono alcuni dei casi d'uso principali e comuni del clustering. D'ora in poi discuteremo degli algoritmi di clustering che ti aiuteranno a eseguire le attività di cui sopra.
Tipi di algoritmi di clustering
A livello superficiale, il clustering aiuta nell'analisi dei dati non strutturati. La grafica, la distanza più breve e la densità dei punti dati sono alcuni degli elementi che influenzano la formazione dei cluster. Il clustering è il processo per determinare la relazione tra gli oggetti in base a una metrica chiamata misura di somiglianza. Le metriche di somiglianza sono più facili da individuare in insiemi di funzionalità più piccoli. Diventa più difficile creare misure di somiglianza man mano che il numero di funzionalità aumenta. A seconda del tipo di algoritmo di clustering utilizzato nel data mining, vengono impiegate diverse tecniche per raggruppare i dati dai set di dati. In questa parte vengono descritte le tecniche di clustering. Vari tipi di algoritmi di clustering sono:
- Clustering basato su centroidi (metodi di partizionamento)
- Clustering basato sulla densità (metodi basati su modelli)
- Clustering basato sulla connettività (clustering gerarchico)
- Clustering basato sulla distribuzione
Esamineremo brevemente ciascuno di questi tipi.
1. I metodi di partizionamento sono gli algoritmi di clustering più semplici. Raggruppano i punti dati in base alla loro vicinanza. Generalmente, la misura di somiglianza scelta per questi algoritmi è la distanza euclidea, la distanza di Manhattan o la distanza di Minkowski. I set di dati sono separati in un numero predeterminato di cluster e a ciascun cluster fa riferimento un vettore di valori. Rispetto al valore del vettore, la variabile dei dati di input non mostra differenze e si unisce al cluster.
Lo svantaggio principale di questi algoritmi è il requisito di stabilire il numero di cluster, k, in modo intuitivo o scientifico (utilizzando il metodo Elbow) prima che qualsiasi sistema di machine learning di clustering inizi ad allocare i punti dati. Nonostante ciò, è ancora il tipo di clustering più popolare. K-significa E K-medoidi clustering sono alcuni esempi di questo tipo di clustering.
2. Clustering basato sulla densità (metodi basati su modelli)
Il clustering basato sulla densità, un metodo basato su modello, trova i gruppi in base alla densità dei punti dati. Contrariamente al clustering basato sui centroidi, che richiede che il numero di cluster sia predefinito ed è sensibile all'inizializzazione, il clustering basato sulla densità determina automaticamente il numero di cluster ed è meno suscettibile alle posizioni iniziali. Sono ottimi nella gestione di cluster di diverse dimensioni e forme, il che li rende ideali per set di dati con cluster di forma irregolare o sovrapposti. Questi metodi gestiscono sia regioni di dati dense che sparse concentrandosi sulla densità locale e possono distinguere cluster con una varietà di morfologie.
Al contrario, il raggruppamento basato sui centroidi, come k-means, ha difficoltà a trovare cluster di forma arbitraria. A causa del numero preimpostato di requisiti del cluster e dell'estrema sensibilità al posizionamento iniziale dei centroidi, i risultati possono variare. Inoltre, la tendenza degli approcci basati sui centroidi a produrre cluster sferici o convessi limita la loro capacità di gestire cluster complicati o di forma irregolare. In conclusione, il clustering basato sulla densità supera gli inconvenienti delle tecniche basate sui centroidi scegliendo autonomamente le dimensioni dei cluster, essendo resiliente all'inizializzazione e acquisendo con successo cluster di varie dimensioni e forme. L'algoritmo di clustering basato sulla densità più popolare è DBSCAN .
3. Clustering basato sulla connettività (clustering gerarchico)
Un metodo per assemblare punti dati correlati in cluster gerarchici è chiamato clustering gerarchico. Ogni punto dati viene inizialmente preso in considerazione come un cluster separato, che viene successivamente combinato con i cluster più simili per formare un unico grande cluster che contiene tutti i punti dati.
Pensa a come organizzare una raccolta di articoli in base a quanto sono simili. Ogni oggetto inizia come un proprio cluster alla base dell'albero quando si utilizza il clustering gerarchico, che crea un dendrogramma, una struttura ad albero. Gli accoppiamenti più vicini di cluster vengono quindi combinati in cluster più grandi dopo che l'algoritmo ha esaminato quanto simili sono gli oggetti tra loro. Quando ogni oggetto si trova in un cluster nella parte superiore dell'albero, il processo di fusione è terminato. Esplorare vari livelli di granularità è una delle cose divertenti del clustering gerarchico. Per ottenere un determinato numero di grappoli si può scegliere di tagliare il dendrogramma ad una particolare altezza. Più due oggetti sono simili all'interno di un cluster, più sono vicini. È paragonabile alla classificazione degli elementi in base ai loro alberi genealogici, dove i parenti più prossimi sono raggruppati insieme e i rami più ampi indicano connessioni più generali. Esistono 2 approcci per il clustering gerarchico:
- Clustering divisivo : Segue un approccio top-down, qui consideriamo tutti i punti dati come parte di un grande cluster e quindi questo cluster viene diviso in gruppi più piccoli.
- Clustering agglomerativo : Segue un approccio dal basso verso l'alto, qui consideriamo tutti i punti dati come parte di singoli cluster e quindi questi cluster vengono raggruppati insieme per creare un grande cluster con tutti i punti dati.
4. Clustering basato sulla distribuzione
Utilizzando il clustering basato sulla distribuzione, i punti dati vengono generati e organizzati in base alla loro propensione a rientrare nella stessa distribuzione di probabilità (come gaussiana, binomiale o altra) all'interno dei dati. Gli elementi dei dati sono raggruppati utilizzando una distribuzione basata sulla probabilità basata su distribuzioni statistiche. Sono inclusi gli oggetti dati che hanno una maggiore probabilità di trovarsi nel cluster. È meno probabile che un punto dati venga incluso in un cluster quanto più è lontano dal punto centrale del cluster, che esiste in ogni cluster.
Uno svantaggio notevole degli approcci basati sulla densità e sui confini è la necessità di specificare i cluster a priori per alcuni algoritmi, e principalmente la definizione della forma dei cluster per la maggior parte degli algoritmi. Deve essere selezionato almeno un tuning o un iperparametro e, sebbene farlo dovrebbe essere semplice, sbagliare potrebbe avere ripercussioni impreviste. Il clustering basato sulla distribuzione presenta un netto vantaggio rispetto agli approcci di clustering basati su centroidi e prossimità in termini di flessibilità, precisione e struttura del cluster. La questione fondamentale è che, per evitare adattamento eccessivo , molti metodi di clustering funzionano solo con dati simulati o prodotti o quando la maggior parte dei punti dati appartiene sicuramente a una distribuzione preimpostata. L'algoritmo di clustering basato sulla distribuzione più popolare è Modello di miscela gaussiana .
Applicazioni del Clustering in diversi ambiti:
- Marketing: Può essere utilizzato per caratterizzare e scoprire segmenti di clienti per scopi di marketing.
- Biologia: Può essere utilizzato per la classificazione tra diverse specie di piante e animali.
- Biblioteche: Viene utilizzato per raggruppare diversi libri sulla base di argomenti e informazioni.
- Assicurazione: Viene utilizzato per riconoscere i clienti, le loro politiche e identificare le frodi.
- Pianificazione della citta: Viene utilizzato per creare gruppi di case e studiarne il valore in base alla loro posizione geografica e ad altri fattori presenti.
- Studi sui terremoti: Conoscendo le zone colpite dal terremoto possiamo determinare le zone pericolose.
- Elaborazione delle immagini : il clustering può essere utilizzato per raggruppare insieme immagini simili, classificare le immagini in base al contenuto e identificare modelli nei dati dell'immagine.
- Genetica: Il clustering viene utilizzato per raggruppare geni che hanno modelli di espressione simili e identificare reti di geni che lavorano insieme nei processi biologici.
- Finanza: Il clustering viene utilizzato per identificare segmenti di mercato in base al comportamento dei clienti, identificare modelli nei dati del mercato azionario e analizzare il rischio nei portafogli di investimento.
- Assistenza clienti: Il clustering viene utilizzato per raggruppare le richieste e i reclami dei clienti in categorie, identificare problemi comuni e sviluppare soluzioni mirate.
- Produzione : Il clustering viene utilizzato per raggruppare insieme prodotti simili, ottimizzare i processi di produzione e identificare i difetti nei processi di produzione.
- Diagnosi medica: Il clustering viene utilizzato per raggruppare pazienti con sintomi o malattie simili, il che aiuta a fare diagnosi accurate e identificare trattamenti efficaci.
- Intercettazione di una frode: Il clustering viene utilizzato per identificare modelli sospetti o anomalie nelle transazioni finanziarie, che possono aiutare a individuare frodi o altri crimini finanziari.
- Analisi del traffico: Il clustering viene utilizzato per raggruppare modelli simili di dati sul traffico, come ore di punta, percorsi e velocità, che possono aiutare a migliorare la pianificazione e l'infrastruttura dei trasporti.
- Analisi dei social network: Il clustering viene utilizzato per identificare comunità o gruppi all'interno dei social network, che possono aiutare a comprendere il comportamento, l'influenza e le tendenze sociali.
- Sicurezza informatica: Il clustering viene utilizzato per raggruppare modelli simili di traffico di rete o comportamento del sistema, che possono aiutare a rilevare e prevenire attacchi informatici.
- Analisi del clima: Il clustering viene utilizzato per raggruppare modelli simili di dati climatici, come temperatura, precipitazioni e vento, che possono aiutare a comprendere il cambiamento climatico e il suo impatto sull’ambiente.
- Analisi sportiva: Il clustering viene utilizzato per raggruppare modelli simili di dati sulle prestazioni di giocatori o squadre, che possono aiutare ad analizzare i punti di forza e di debolezza dei giocatori o della squadra e a prendere decisioni strategiche.
- Analisi del crimine: Il clustering viene utilizzato per raggruppare modelli simili di dati sulla criminalità, come posizione, ora e tipo, che possono aiutare a identificare i punti caldi della criminalità, prevedere le tendenze future della criminalità e migliorare le strategie di prevenzione della criminalità.
Conclusione
In questo articolo abbiamo discusso del clustering, dei suoi tipi e delle sue applicazioni nel mondo reale. C'è molto altro da coprire nell'apprendimento non supervisionato e l'analisi dei cluster è solo il primo passo. Questo articolo può aiutarti a iniziare con gli algoritmi di clustering e aiutarti a ottenere un nuovo progetto che può essere aggiunto al tuo portfolio.
Domande frequenti (FAQ) sul clustering
D. Qual è il metodo di clustering migliore?
I primi 10 algoritmi di clustering sono:
- K-significa clustering
- Clustering gerarchico
- DBSCAN (Clustering spaziale basato sulla densità di applicazioni con rumore)
- Modelli di miscela gaussiana (GMM)
- Clustering agglomerativo
- Clustering spettrale
- Raggruppamento dei turni medi
- Propagazione per affinità
- OTTICA (punti di ordinamento per identificare la struttura di clustering)
- Birch (riduzione iterativa bilanciata e clustering utilizzando gerarchie)
D. Qual è la differenza tra clustering e classificazione?
La differenza principale tra clustering e classificazione è che la classificazione è un algoritmo di apprendimento supervisionato e il clustering è un algoritmo di apprendimento non supervisionato. Cioè, applichiamo il clustering a quei set di dati che non hanno una variabile target.
D. Quali sono i vantaggi dell'analisi di clustering?
I dati possono essere organizzati in gruppi significativi utilizzando il potente strumento analitico dell'analisi dei cluster. Puoi usarlo per individuare segmenti, trovare modelli nascosti e migliorare le decisioni.
D. Qual è il metodo di clustering più veloce?
Il clustering K-means è spesso considerato il metodo di clustering più veloce grazie alla sua semplicità ed efficienza computazionale. Assegna in modo iterativo i punti dati al centroide del cluster più vicino, rendendolo adatto a set di dati di grandi dimensioni con bassa dimensionalità e un numero moderato di cluster.
D. Quali sono i limiti del clustering?
I limiti del clustering includono la sensibilità alle condizioni iniziali, la dipendenza dalla scelta dei parametri, la difficoltà nel determinare il numero ottimale di cluster e le sfide con la gestione di dati ad alta dimensione o rumorosi.
D. Da cosa dipende la qualità del risultato del clustering?
La qualità dei risultati del clustering dipende da fattori quali la scelta dell'algoritmo, la metrica della distanza, il numero di cluster, il metodo di inizializzazione, le tecniche di preelaborazione dei dati, le metriche di valutazione dei cluster e la conoscenza del dominio. Questi elementi influenzano collettivamente l'efficacia e l'accuratezza del risultato del clustering.
confronta la stringa java