La ricerca non informata è una classe di algoritmi di ricerca generici che operano in modalità forza bruta. Gli algoritmi di ricerca non informati non hanno informazioni aggiuntive sullo stato o sullo spazio di ricerca oltre a come attraversare l'albero, quindi viene anche chiamata ricerca cieca.
Di seguito sono riportati i vari tipi di algoritmi di ricerca non informati:
1. Ricerca in ampiezza:
- La ricerca in ampiezza è la strategia di ricerca più comune per attraversare un albero o un grafico. Questo algoritmo esegue la ricerca in larghezza in un albero o in un grafico, quindi è chiamato ricerca in ampiezza.
- L'algoritmo BFS inizia la ricerca dal nodo radice dell'albero ed espande tutti i nodi successivi al livello corrente prima di passare ai nodi del livello successivo.
- L'algoritmo di ricerca in ampiezza è un esempio di algoritmo di ricerca su grafo generale.
- Ricerca in ampiezza implementata utilizzando la struttura dei dati della coda FIFO.
Vantaggi:
- BFS fornirà una soluzione se esiste una soluzione.
- Se esistono più soluzioni per un dato problema, BFS fornirà la soluzione minima che richiede il minor numero di passaggi.
Svantaggi:
- Richiede molta memoria poiché ogni livello dell'albero deve essere salvato in memoria per espandere il livello successivo.
- BFS richiede molto tempo se la soluzione è lontana dal nodo radice.
Esempio:
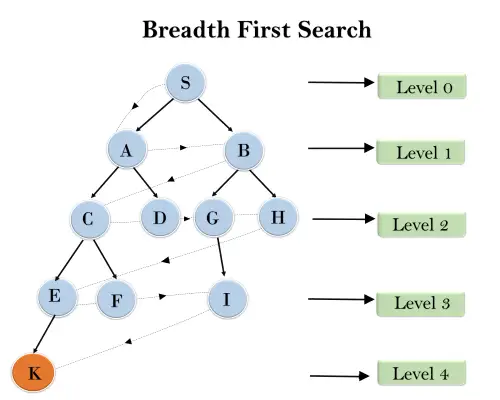
Nella struttura ad albero sottostante, abbiamo mostrato l'attraversamento dell'albero utilizzando l'algoritmo BFS dal nodo radice S al nodo obiettivo K. L'algoritmo di ricerca BFS attraversa a strati, quindi seguirà il percorso mostrato dalla freccia tratteggiata e il il percorso percorso sarà:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
Complessità temporale: La complessità temporale dell'algoritmo BFS può essere ottenuta dal numero di nodi attraversati in BFS fino al nodo più superficiale. Dove d= profondità della soluzione più superficiale eb è un nodo in ogni stato.
carattere Java in stringa
T(b) = 1+b2+b3+.......+ bD= O (bD)
Complessità spaziale: La complessità spaziale dell'algoritmo BFS è data dalla dimensione della memoria della frontiera che è O(bD).
Completezza: BFS è completo, il che significa che se il nodo obiettivo più superficiale si trova a una profondità finita, BFS troverà una soluzione.
Ottimalità: BFS è ottimale se il costo del percorso è una funzione non decrescente della profondità del nodo.
2. Ricerca in profondità
- La ricerca in profondità è un algoritmo ricorsivo per attraversare una struttura dati ad albero o grafico.
- Si chiama ricerca in profondità perché inizia dal nodo radice e segue ciascun percorso fino al nodo di massima profondità prima di passare al percorso successivo.
- DFS utilizza una struttura dati stack per la sua implementazione.
- Il processo dell'algoritmo DFS è simile all'algoritmo BFS.
Nota: il backtracking è una tecnica algoritmica per trovare tutte le possibili soluzioni utilizzando la ricorsione.
Vantaggio:
- DFS richiede molta meno memoria poiché deve solo archiviare uno stack di nodi sul percorso dal nodo radice al nodo corrente.
- Ci vuole meno tempo per raggiungere il nodo obiettivo rispetto all'algoritmo BFS (se attraversa il percorso giusto).
Svantaggio:
- Esiste la possibilità che molti stati continuino a ripetersi e non vi è alcuna garanzia di trovare una soluzione.
- L'algoritmo DFS effettua ricerche approfondite e talvolta potrebbe passare al ciclo infinito.
Esempio:
Nell'albero di ricerca sottostante, abbiamo mostrato il flusso della ricerca in profondità e seguirà l'ordine come:
Nodo radice ---> Nodo sinistro ----> Nodo destro.
Inizierà la ricerca dal nodo radice S e attraverserà A, quindi B, quindi D ed E, dopo aver attraversato E, ripercorrerà l'albero poiché E non ha altri successori e il nodo obiettivo non viene ancora trovato. Dopo il backtracking attraverserà il nodo C e poi G, e qui terminerà quando ha trovato il nodo obiettivo.

Completezza: L'algoritmo di ricerca DFS è completo nello spazio degli stati finito poiché espanderà ogni nodo all'interno di un albero di ricerca limitato.
Complessità temporale: La complessità temporale del DFS sarà equivalente al nodo attraversato dall'algoritmo. Esso è dato da:
T(n)= 1+ n2+n3+.........+nM=O(nM)
Dove, m= profondità massima di qualsiasi nodo e questa può essere molto maggiore di d (profondità della soluzione più bassa)
Complessità spaziale: L'algoritmo DFS deve memorizzare solo un singolo percorso dal nodo radice, quindi la complessità spaziale di DFS è equivalente alla dimensione dell'insieme marginale, che è O(bm) .
Ottimale: L'algoritmo di ricerca DFS non è ottimale, poiché potrebbe generare un numero elevato di passaggi o costi elevati per raggiungere il nodo obiettivo.
3. Algoritmo di ricerca con profondità limitata:
Un algoritmo di ricerca a profondità limitata è simile alla ricerca in profondità con un limite predeterminato. La ricerca a profondità limitata può risolvere l'inconveniente del percorso infinito nella ricerca in profondità. In questo algoritmo, il nodo al limite di profondità verrà considerato come se non avesse ulteriori nodi successivi.
La ricerca a profondità limitata può essere terminata con due condizioni di fallimento:
- Valore di errore standard: indica che il problema non ha alcuna soluzione.
- Valore di fallimento di interruzione: non definisce alcuna soluzione per il problema entro un determinato limite di profondità.
Vantaggi:
La ricerca con profondità limitata è efficiente in termini di memoria.
Svantaggi:
- La ricerca con profondità limitata presenta anche lo svantaggio di incompletezza.
- Potrebbe non essere ottimale se il problema ha più di una soluzione.
Esempio:

Completezza: L'algoritmo di ricerca DLS è completo se la soluzione è superiore al limite di profondità.
materiale angolare
Complessità temporale: La complessità temporale dell'algoritmo DLS è O(bℓ) .
Complessità spaziale: La complessità spaziale dell'algoritmo DLS è O (b�ℓ) .
Ottimale: La ricerca limitata in profondità può essere vista come un caso speciale di DFS e inoltre non è ottimale anche se ℓ>d.
4. Algoritmo di ricerca a costo uniforme:
La ricerca a costo uniforme è un algoritmo di ricerca utilizzato per attraversare un albero o un grafico ponderato. Questo algoritmo entra in gioco quando è disponibile un costo diverso per ciascun bordo. L'obiettivo principale della ricerca a costo uniforme è trovare un percorso verso il nodo obiettivo che ha il costo cumulativo più basso. La ricerca a costo uniforme espande i nodi in base ai costi del percorso dal nodo radice. Può essere utilizzato per risolvere qualsiasi grafo/albero in cui è richiesto il costo ottimale. Un algoritmo di ricerca a costo uniforme è implementato dalla coda di priorità. Dà la massima priorità al costo cumulativo più basso. La ricerca a costo uniforme è equivalente all'algoritmo BFS se il costo del percorso di tutti gli archi è lo stesso.
Vantaggi:
- La ricerca dei costi uniformi è ottimale perché in ogni stato viene scelto il percorso con il costo minore.
Svantaggi:
- Non si preoccupa del numero di passaggi coinvolti nella ricerca e si preoccupa solo del costo del percorso. Per questo motivo questo algoritmo potrebbe rimanere bloccato in un ciclo infinito.
Esempio:

Completezza:
La ricerca a costo uniforme è completa, ad esempio se esiste una soluzione, UCS la troverà.
Complessità temporale:
Sia C* è il Costo della soluzione ottima , E e è ogni passo per avvicinarsi al nodo obiettivo. Allora il numero di passi è = C*/ε+1. Qui abbiamo preso +1, poiché iniziamo dallo stato 0 e finiamo in C*/ε.
Pertanto, la complessità temporale nel caso peggiore della ricerca a costo uniforme è O(b1 + [C*/e])/ .
Complessità spaziale:
La stessa logica vale per la complessità dello spazio, quindi lo è la complessità dello spazio nel caso peggiore della ricerca a costo uniforme O(b1 + [C*/e]) .
Ottimale:
quali sono le dimensioni del mio monitor
La ricerca a costo uniforme è sempre ottimale poiché seleziona solo un percorso con il costo di percorso più basso.
5. Approfondimento iterativo, ricerca approfondita:
L'algoritmo di approfondimento iterativo è una combinazione degli algoritmi DFS e BFS. Questo algoritmo di ricerca individua il miglior limite di profondità e lo fa aumentando gradualmente il limite fino a trovare un obiettivo.
Questo algoritmo esegue la ricerca in profondità fino a un certo 'limite di profondità' e continua ad aumentare il limite di profondità dopo ogni iterazione finché non viene trovato il nodo obiettivo.
Questo algoritmo di ricerca combina i vantaggi della ricerca rapida della ricerca in ampiezza e dell'efficienza della memoria della ricerca in profondità.
L'algoritmo di ricerca iterativa è utile per la ricerca non informata quando lo spazio di ricerca è ampio e la profondità del nodo obiettivo è sconosciuta.
Vantaggi:
- Combina i vantaggi degli algoritmi di ricerca BFS e DFS in termini di ricerca veloce ed efficienza della memoria.
Svantaggi:
- Lo svantaggio principale di IDDFS è che ripete tutto il lavoro della fase precedente.
Esempio:
La seguente struttura ad albero mostra la ricerca iterativa di approfondimento in profondità. L'algoritmo IDDFS esegue varie iterazioni finché non trova il nodo obiettivo. L'iterazione eseguita dall'algoritmo è data come:

1a iterazione-----> A
2a iterazione ----> A, B, C
3a iterazione------>A, B, D, E, C, F, G
4a iterazione------>A, B, D, H, I, E, C, F, K, G
Nella quarta iterazione, l'algoritmo troverà il nodo obiettivo.
Completezza:
Questo algoritmo è completo se il fattore di ramificazione è finito.
Complessità temporale:
Supponiamo che b sia il fattore di ramificazione e che la profondità sia d, quindi lo sarà la complessità temporale nel caso peggiore O(bD) .
Complessità spaziale:
La complessità spaziale di IDDFS sarà O(bd) .
Ottimale:
tutto maiuscolo comanda Excel
L'algoritmo IDDFS è ottimale se il costo del percorso è una funzione non decrescente della profondità del nodo.
6. Algoritmo di ricerca bidirezionale:
L'algoritmo di ricerca bidirezionale esegue due ricerche simultanee, una dallo stato iniziale chiamata ricerca in avanti e l'altra dal nodo obiettivo chiamata ricerca all'indietro, per trovare il nodo obiettivo. La ricerca bidirezionale sostituisce un singolo grafo di ricerca con due piccoli sottografi in cui uno inizia la ricerca da un vertice iniziale e l'altro inizia dal vertice obiettivo. La ricerca si interrompe quando questi due grafici si intersecano.
La ricerca bidirezionale può utilizzare tecniche di ricerca come BFS, DFS, DLS, ecc.
Vantaggi:
- La ricerca bidirezionale è veloce.
- La ricerca bidirezionale richiede meno memoria
Svantaggi:
- L'implementazione dell'albero di ricerca bidirezionale è difficile.
Esempio:
Nell'albero di ricerca sottostante viene applicato l'algoritmo di ricerca bidirezionale. Questo algoritmo divide un grafico/albero in due sottografi. Inizia l'attraversamento dal nodo 1 nella direzione in avanti e inizia dal nodo di destinazione 16 nella direzione all'indietro.
L'algoritmo termina al nodo 9 dove si incontrano due ricerche.

Completezza: La ricerca bidirezionale è completa se utilizziamo BFS in entrambe le ricerche.
Complessità temporale: La complessità temporale della ricerca bidirezionale utilizzando BFS è O(bD) .
Complessità spaziale: La complessità spaziale della ricerca bidirezionale è O(bD) .
Ottimale: La ricerca bidirezionale è ottimale.